 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient Flow Through Diagram Expansions: Learning Regimes and Explicit Solutions
Feb 04, 2026We develop a general mathematical framework to analyze scaling regimes and derive explicit analytic solutions for gradient flow (GF) in large learning problems. Our key innovation is a formal power series expansion of the loss evolution, with coefficients encoded by diagrams akin to Feynman diagrams. We show that this expansion has a well-defined large-size limit that can be used to reveal different learning phases and, in some cases, to obtain explicit solutions of the nonlinear GF. We focus on learning Canonical Polyadic (CP) decompositions of high-order tensors, and show that this model has several distinct extreme lazy and rich GF regimes such as free evolution, NTK and under- and over-parameterized mean-field. We show that these regimes depend on the parameter scaling, tensor order, and symmetry of the model in a specific and subtle way. Moreover, we propose a general approach to summing the formal loss expansion by reducing it to a PDE; in a wide range of scenarios, it turns out to be 1st order and solvable by the method of characteristics. We observe a very good agreement of our theoretical predictions with experiment.
A Generalization Bound for Nearly-Linear Networks
Jul 09, 2024
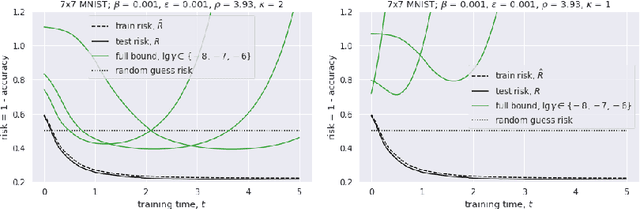
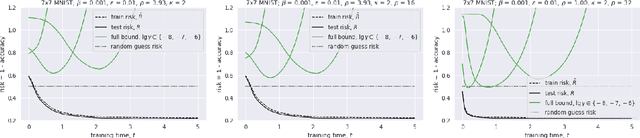
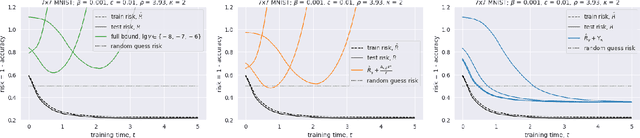
We consider nonlinear networks as perturbations of linear ones. Based on this approach, we present novel generalization bounds that become non-vacuous for networks that are close to being linear. The main advantage over the previous works which propose non-vacuous generalization bounds is that our bounds are a-priori: performing the actual training is not required for evaluating the bounds. To the best of our knowledge, they are the first non-vacuous generalization bounds for neural nets possessing this property.
Neural Tangent Kernel: A Survey
Aug 29, 2022
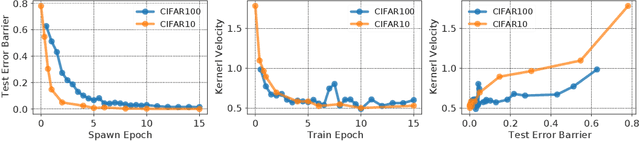
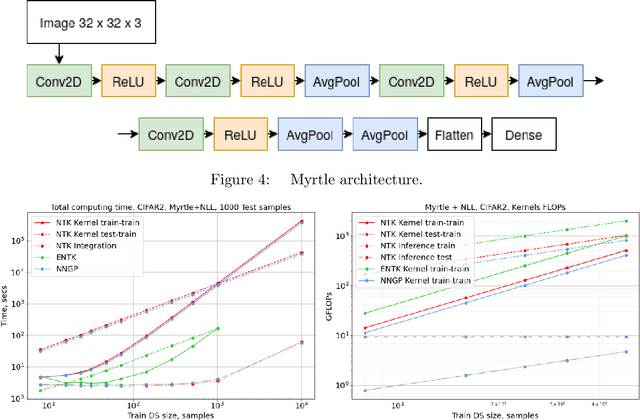
A seminal work [Jacot et al., 2018] demonstrated that training a neural network under specific parameterization is equivalent to performing a particular kernel method as width goes to infinity. This equivalence opened a promising direction for applying the results of the rich literature on kernel methods to neural nets which were much harder to tackle. The present survey covers key results on kernel convergence as width goes to infinity, finite-width corrections, applications, and a discussion of the limitations of the corresponding method.
Feature Learning in $L_{2}$-regularized DNNs: Attraction/Repulsion and Sparsity
May 31, 2022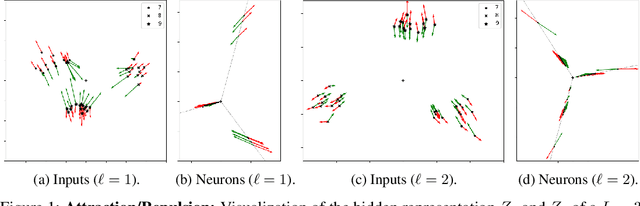

We study the loss surface of DNNs with $L_{2}$ regularization. We show that the loss in terms of the parameters can be reformulated into a loss in terms of the layerwise activations $Z_{\ell}$ of the training set. This reformulation reveals the dynamics behind feature learning: each hidden representations $Z_{\ell}$ are optimal w.r.t. to an attraction/repulsion problem and interpolate between the input and output representations, keeping as little information from the input as necessary to construct the activation of the next layer. For positively homogeneous non-linearities, the loss can be further reformulated in terms of the covariances of the hidden representations, which takes the form of a partially convex optimization over a convex cone. This second reformulation allows us to prove a sparsity result for homogeneous DNNs: any local minimum of the $L_{2}$-regularized loss can be achieved with at most $N(N+1)$ neurons in each hidden layer (where $N$ is the size of the training set). We show that this bound is tight by giving an example of a local minimum which requires $N^{2}/4$ hidden neurons. But we also observe numerically that in more traditional settings much less than $N^{2}$ neurons are required to reach the minima.
An Essay on Optimization Mystery of Deep Learning
May 17, 2019
Despite the huge empirical success of deep learning, theoretical understanding of neural networks learning process is still lacking. This is the reason, why some of its features seem "mysterious". We emphasize two mysteries of deep learning: generalization mystery, and optimization mystery. In this essay we review and draw connections between several selected works concerning the latter.
Embedding-reparameterization procedure for manifold-valued latent variables in generative models
Dec 06, 2018


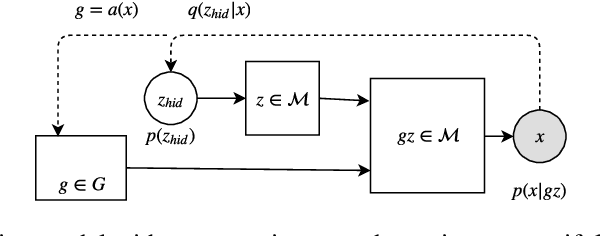
Conventional prior for Variational Auto-Encoder (VAE) is a Gaussian distribution. Recent works demonstrated that choice of prior distribution affects learning capacity of VAE models. We propose a general technique (embedding-reparameterization procedure, or ER) for introducing arbitrary manifold-valued variables in VAE model. We compare our technique with a conventional VAE on a toy benchmark problem. This is work in progress.
Differentiable lower bound for expected BLEU score
Aug 23, 2018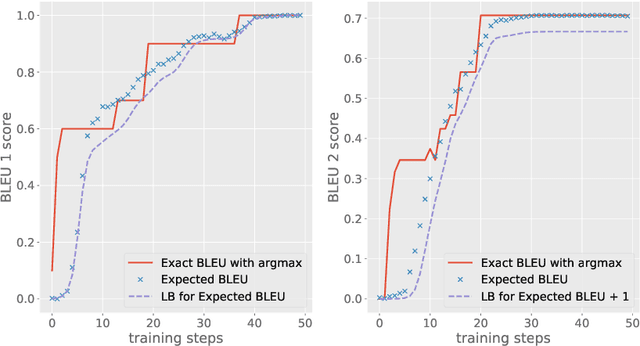
In natural language processing tasks performance of the models is often measured with some non-differentiable metric, such as BLEU score. To use efficient gradient-based methods for optimization, it is a common workaround to optimize some surrogate loss function. This approach is effective if optimization of such loss also results in improving target metric. The corresponding problem is referred to as loss-evaluation mismatch. In the present work we propose a method for calculation of differentiable lower bound of expected BLEU score that does not involve computationally expensive sampling procedure such as the one required when using REINFORCE rule from reinforcement learning (RL) framework.
Using stochastic computation graphs formalism for optimization of sequence-to-sequence model
Dec 15, 2017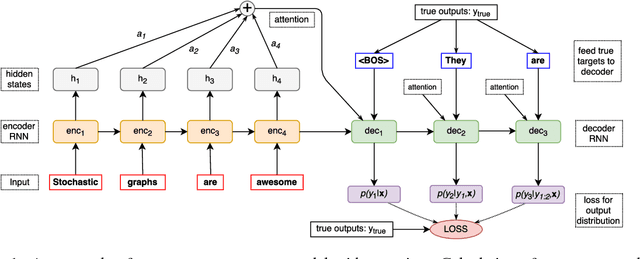
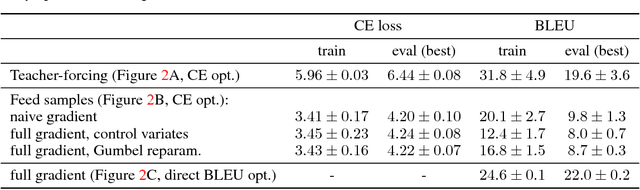
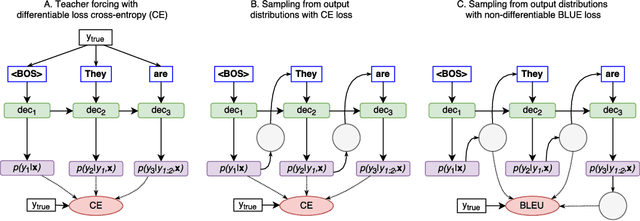
Variety of machine learning problems can be formulated as an optimization task for some (surrogate) loss function. Calculation of loss function can be viewed in terms of stochastic computation graphs (SCG). We use this formalism to analyze a problem of optimization of famous sequence-to-sequence model with attention and propose reformulation of the task. Examples are given for machine translation (MT). Our work provides a unified view on different optimization approaches for sequence-to-sequence models and could help researchers in developing new network architectures with embedded stochastic nodes.