 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDifferentiable lower bound for expected BLEU score
Aug 23, 2018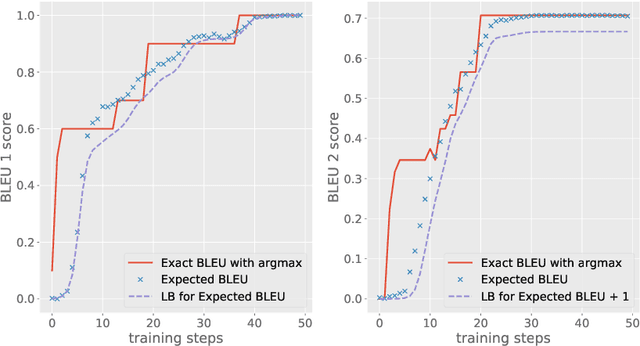
In natural language processing tasks performance of the models is often measured with some non-differentiable metric, such as BLEU score. To use efficient gradient-based methods for optimization, it is a common workaround to optimize some surrogate loss function. This approach is effective if optimization of such loss also results in improving target metric. The corresponding problem is referred to as loss-evaluation mismatch. In the present work we propose a method for calculation of differentiable lower bound of expected BLEU score that does not involve computationally expensive sampling procedure such as the one required when using REINFORCE rule from reinforcement learning (RL) framework.
Using stochastic computation graphs formalism for optimization of sequence-to-sequence model
Dec 15, 2017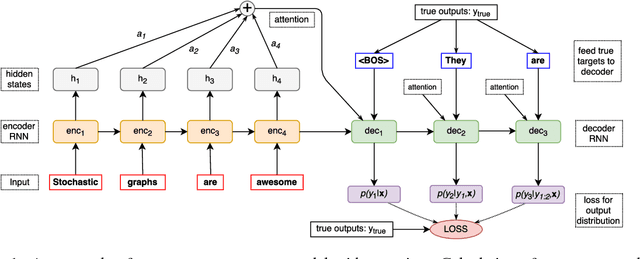
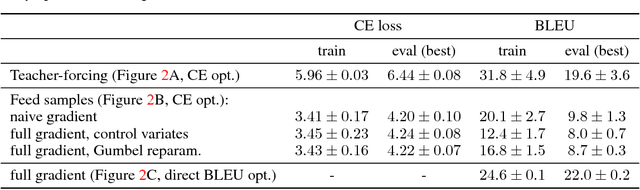
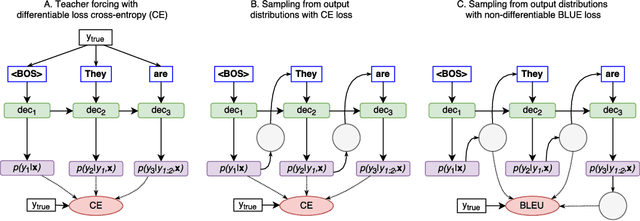
Variety of machine learning problems can be formulated as an optimization task for some (surrogate) loss function. Calculation of loss function can be viewed in terms of stochastic computation graphs (SCG). We use this formalism to analyze a problem of optimization of famous sequence-to-sequence model with attention and propose reformulation of the task. Examples are given for machine translation (MT). Our work provides a unified view on different optimization approaches for sequence-to-sequence models and could help researchers in developing new network architectures with embedded stochastic nodes.