 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKandinsky 5.0: A Family of Foundation Models for Image and Video Generation
Nov 19, 2025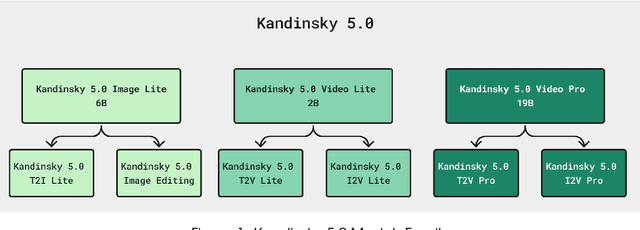

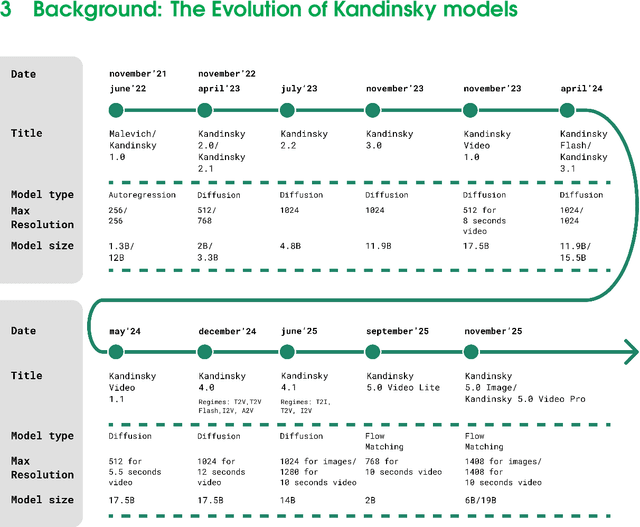
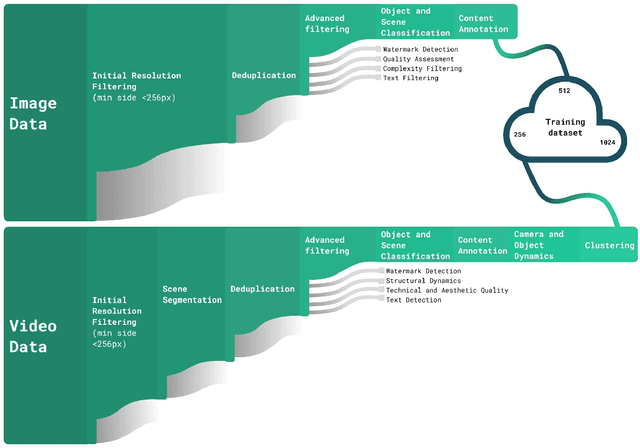
This report introduces Kandinsky 5.0, a family of state-of-the-art foundation models for high-resolution image and 10-second video synthesis. The framework comprises three core line-up of models: Kandinsky 5.0 Image Lite - a line-up of 6B parameter image generation models, Kandinsky 5.0 Video Lite - a fast and lightweight 2B parameter text-to-video and image-to-video models, and Kandinsky 5.0 Video Pro - 19B parameter models that achieves superior video generation quality. We provide a comprehensive review of the data curation lifecycle - including collection, processing, filtering and clustering - for the multi-stage training pipeline that involves extensive pre-training and incorporates quality-enhancement techniques such as self-supervised fine-tuning (SFT) and reinforcement learning (RL)-based post-training. We also present novel architectural, training, and inference optimizations that enable Kandinsky 5.0 to achieve high generation speeds and state-of-the-art performance across various tasks, as demonstrated by human evaluation. As a large-scale, publicly available generative framework, Kandinsky 5.0 leverages the full potential of its pre-training and subsequent stages to be adapted for a wide range of generative applications. We hope that this report, together with the release of our open-source code and training checkpoints, will substantially advance the development and accessibility of high-quality generative models for the research community.
$ abla$NABLA: Neighborhood Adaptive Block-Level Attention
Jul 17, 2025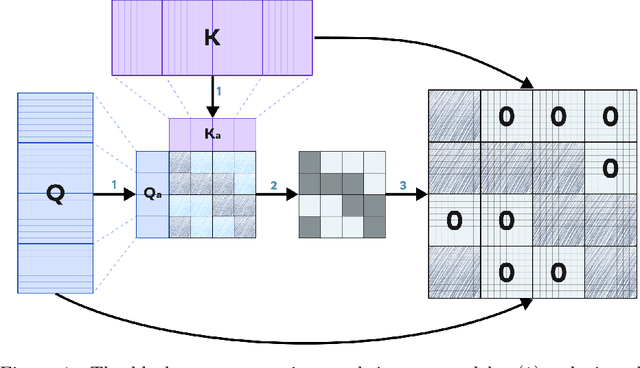
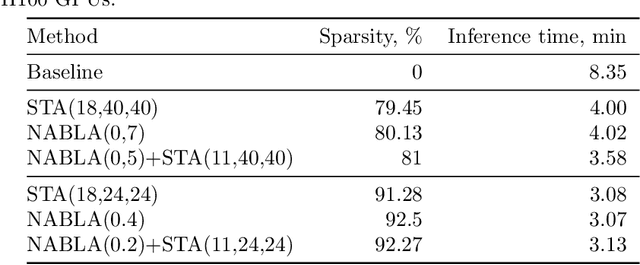
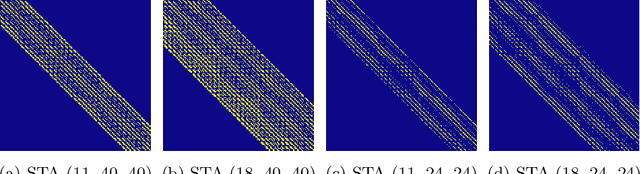
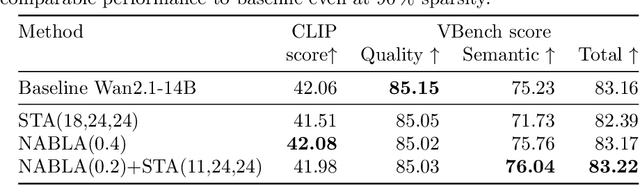
Recent progress in transformer-based architectures has demonstrated remarkable success in video generation tasks. However, the quadratic complexity of full attention mechanisms remains a critical bottleneck, particularly for high-resolution and long-duration video sequences. In this paper, we propose NABLA, a novel Neighborhood Adaptive Block-Level Attention mechanism that dynamically adapts to sparsity patterns in video diffusion transformers (DiTs). By leveraging block-wise attention with adaptive sparsity-driven threshold, NABLA reduces computational overhead while preserving generative quality. Our method does not require custom low-level operator design and can be seamlessly integrated with PyTorch's Flex Attention operator. Experiments demonstrate that NABLA achieves up to 2.7x faster training and inference compared to baseline almost without compromising quantitative metrics (CLIP score, VBench score, human evaluation score) and visual quality drop. The code and model weights are available here: https://github.com/gen-ai-team/Wan2.1-NABLA
NeoNeXt: Novel neural network operator and architecture based on the patch-wise matrix multiplications
Mar 17, 2024Most of the computer vision architectures nowadays are built upon the well-known foundation operations: fully-connected layers, convolutions and multi-head self-attention blocks. In this paper we propose a novel foundation operation - NeoCell - which learns matrix patterns and performs patchwise matrix multiplications with the input data. The main advantages of the proposed operator are (1) simple implementation without need in operations like im2col, (2) low computational complexity (especially for large matrices) and (3) simple and flexible implementation of up-/down-sampling. We validate NeoNeXt family of models based on this operation on ImageNet-1K classification task and show that they achieve competitive quality.
Neural Tangent Kernel: A Survey
Aug 29, 2022
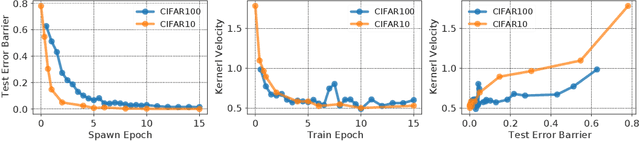
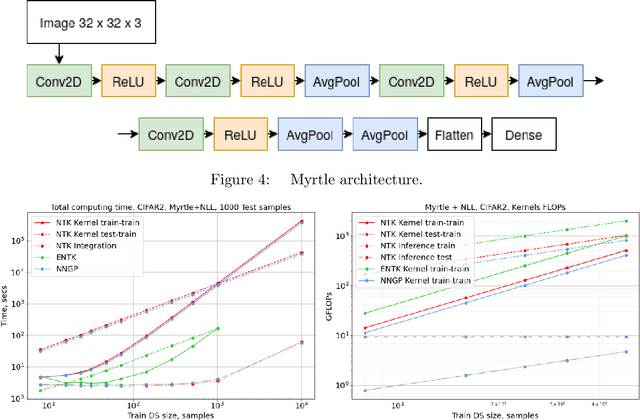
A seminal work [Jacot et al., 2018] demonstrated that training a neural network under specific parameterization is equivalent to performing a particular kernel method as width goes to infinity. This equivalence opened a promising direction for applying the results of the rich literature on kernel methods to neural nets which were much harder to tackle. The present survey covers key results on kernel convergence as width goes to infinity, finite-width corrections, applications, and a discussion of the limitations of the corresponding method.
ISyNet: Convolutional Neural Networks design for AI accelerator
Sep 04, 2021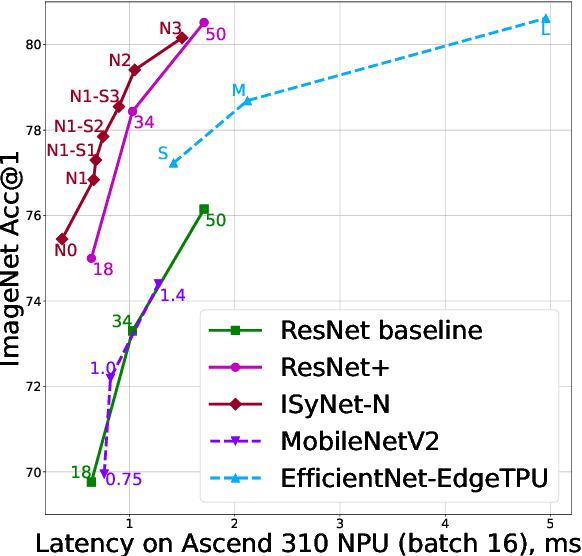
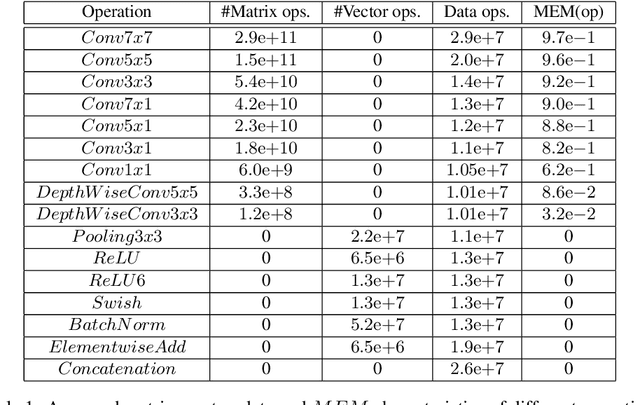
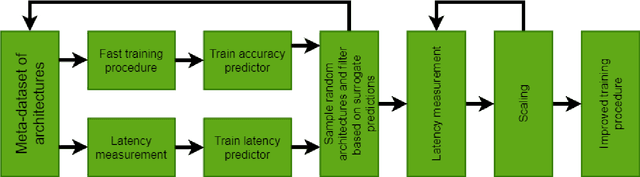
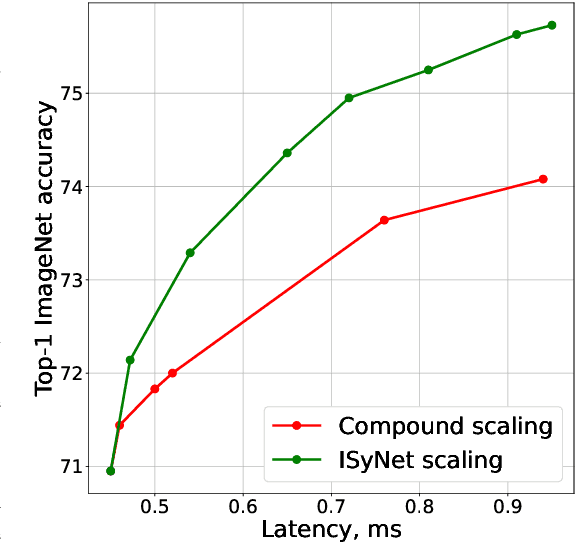
In recent years Deep Learning reached significant results in many practical problems, such as computer vision, natural language processing, speech recognition and many others. For many years the main goal of the research was to improve the quality of models, even if the complexity was impractically high. However, for the production solutions, which often require real-time work, the latency of the model plays a very important role. Current state-of-the-art architectures are found with neural architecture search (NAS) taking model complexity into account. However, designing of the search space suitable for specific hardware is still a challenging task. To address this problem we propose a measure of hardware efficiency of neural architecture search space - matrix efficiency measure (MEM); a search space comprising of hardware-efficient operations; a latency-aware scaling method; and ISyNet - a set of architectures designed to be fast on the specialized neural processing unit (NPU) hardware and accurate at the same time. We show the advantage of the designed architectures for the NPU devices on ImageNet and the generalization ability for the downstream classification and detection tasks.
Tensor Yard: One-Shot Algorithm of Hardware-Friendly Tensor-Train Decomposition for Convolutional Neural Networks
Aug 09, 2021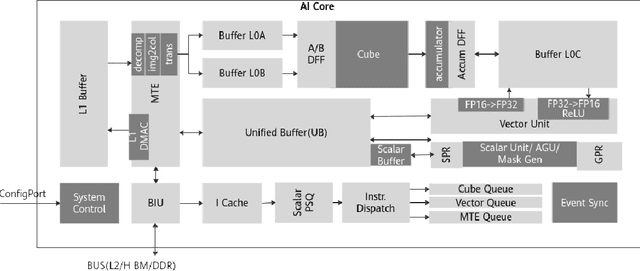
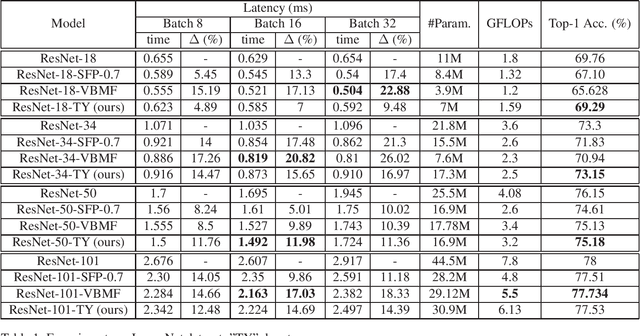
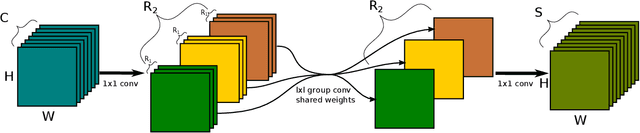

Nowadays Deep Learning became widely used in many economic, technical and scientific areas of human interest. It is clear that efficiency of solutions based on Deep Neural Networks should consider not only quality metric for the target task, but also latency and constraints of target platform design should be taken into account. In this paper we present novel hardware-friendly Tensor-Train decomposition implementation for Convolutional Neural Networks together with Tensor Yard - one-shot training algorithm which optimizes an order of decomposition of network layers. These ideas allow to accelerate ResNet models on Ascend 310 NPU devices without significant loss of accuracy. For example we accelerate ResNet-101 by 14.6% with drop by 0.5 of top-1 ImageNet accuracy.