 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTensor Yard: One-Shot Algorithm of Hardware-Friendly Tensor-Train Decomposition for Convolutional Neural Networks
Aug 09, 2021
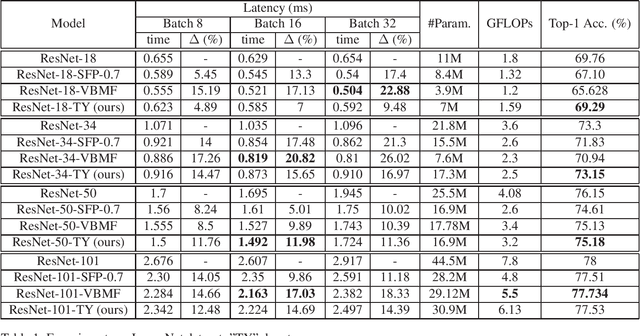
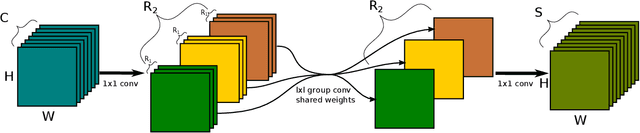

Nowadays Deep Learning became widely used in many economic, technical and scientific areas of human interest. It is clear that efficiency of solutions based on Deep Neural Networks should consider not only quality metric for the target task, but also latency and constraints of target platform design should be taken into account. In this paper we present novel hardware-friendly Tensor-Train decomposition implementation for Convolutional Neural Networks together with Tensor Yard - one-shot training algorithm which optimizes an order of decomposition of network layers. These ideas allow to accelerate ResNet models on Ascend 310 NPU devices without significant loss of accuracy. For example we accelerate ResNet-101 by 14.6% with drop by 0.5 of top-1 ImageNet accuracy.