 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDeep Linear Networks Dynamics: Low-Rank Biases Induced by Initialization Scale and L2 Regularization
Paper and Code
Jun 30, 2021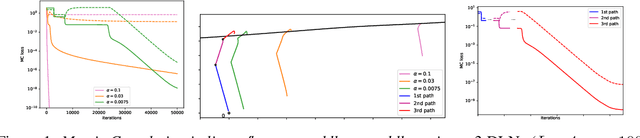

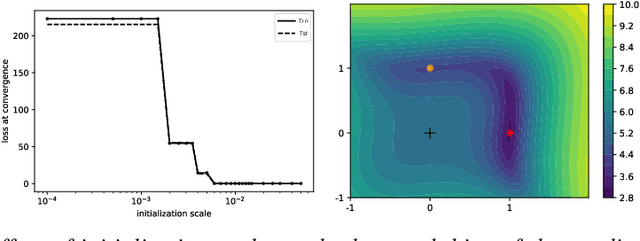
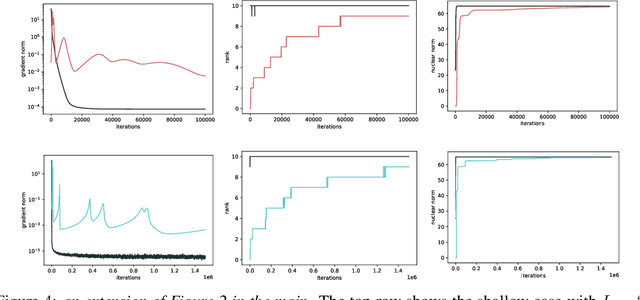
For deep linear networks (DLN), various hyperparameters alter the dynamics of training dramatically. We investigate how the rank of the linear map found by gradient descent is affected by (1) the initialization norm and (2) the addition of $L_{2}$ regularization on the parameters. For (1), we study two regimes: (1a) the linear/lazy regime, for large norm initialization; (1b) a \textquotedbl saddle-to-saddle\textquotedbl{} regime for small initialization norm. In the (1a) setting, the dynamics of a DLN of any depth is similar to that of a standard linear model, without any low-rank bias. In the (1b) setting, we conjecture that throughout training, gradient descent approaches a sequence of saddles, each corresponding to linear maps of increasing rank, until reaching a minimal rank global minimum. We support this conjecture with a partial proof and some numerical experiments. For (2), we show that adding a $L_{2}$ regularization on the parameters corresponds to the addition to the cost of a $L_{p}$-Schatten (quasi)norm on the linear map with $p=\frac{2}{L}$ (for a depth-$L$ network), leading to a stronger low-rank bias as $L$ grows. The effect of $L_{2}$ regularization on the loss surface depends on the depth: for shallow networks, all critical points are either strict saddles or global minima, whereas for deep networks, some local minima appear. We numerically observe that these local minima can generalize better than global ones in some settings.