 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePopulation Risk Bounds for Kolmogorov-Arnold Networks Trained by DP-SGD with Correlated Noise
May 12, 2026We establish the first population risk bounds for Kolmogorov-Arnold Networks (KANs) trained by mini-batch SGD with gradient clipping, covering non-private SGD as well as differentially private SGD (DP-SGD) with Gaussian perturbations that interpolate between independent and temporally correlated noise. This setting is substantially closer to practice than prior KAN theory along two axes: training is by mini-batch SGD, the standard recipe for modern networks, rather than full-batch gradient descent (GD); and correlated-noise mechanisms have empirically shown a more favorable privacy-utility tradeoff than independent-noise mechanisms. Our results cover the corresponding full-batch GD and independent-noise DP-GD results for KANs by Wang et al. (2026), while yielding sharper fixed-second-layer specializations. The technical core is a new analysis route for correlated-noise DP training in the non-convex regime. Temporal dependence breaks the conditional-centering structure underlying standard one-step SGD arguments, and the projection step obstructs the exact cancellation structure of correlated perturbations. We address these difficulties through an auxiliary unprojected dynamics, a shifted iterate that absorbs the current noise perturbation, and a high-probability bootstrap certifying projection inactivity. Combining this optimization analysis with a stability-based generalization argument yields the stated population risk bounds. To the best of our knowledge, this is the first optimization and population risk analysis of a correlated-noise mechanism for DP training beyond convex learning, in particular for neural networks.
Neural Collapse versus Low-rank Bias: Is Deep Neural Collapse Really Optimal?
May 23, 2024



Deep neural networks (DNNs) exhibit a surprising structure in their final layer known as neural collapse (NC), and a growing body of works has currently investigated the propagation of neural collapse to earlier layers of DNNs -- a phenomenon called deep neural collapse (DNC). However, existing theoretical results are restricted to special cases: linear models, only two layers or binary classification. In contrast, we focus on non-linear models of arbitrary depth in multi-class classification and reveal a surprising qualitative shift. As soon as we go beyond two layers or two classes, DNC stops being optimal for the deep unconstrained features model (DUFM) -- the standard theoretical framework for the analysis of collapse. The main culprit is a low-rank bias of multi-layer regularization schemes: this bias leads to optimal solutions of even lower rank than the neural collapse. We support our theoretical findings with experiments on both DUFM and real data, which show the emergence of the low-rank structure in the solution found by gradient descent.
Banded Square Root Matrix Factorization for Differentially Private Model Training
May 22, 2024


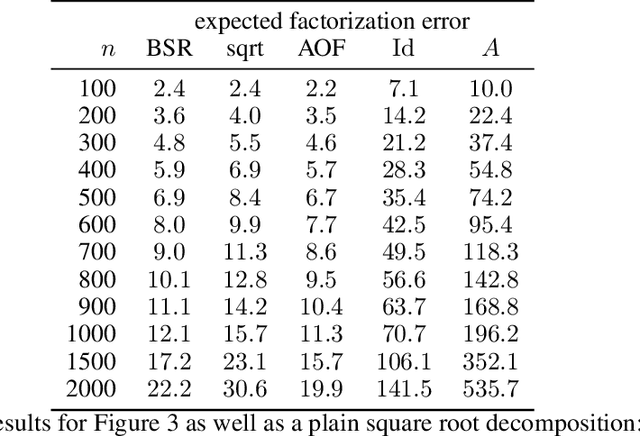
Current state-of-the-art methods for differentially private model training are based on matrix factorization techniques. However, these methods suffer from high computational overhead because they require numerically solving a demanding optimization problem to determine an approximately optimal factorization prior to the actual model training. In this work, we present a new matrix factorization approach, BSR, which overcomes this computational bottleneck. By exploiting properties of the standard matrix square root, BSR allows to efficiently handle also large-scale problems. For the key scenario of stochastic gradient descent with momentum and weight decay, we even derive analytical expressions for BSR that render the computational overhead negligible. We prove bounds on the approximation quality that hold both in the centralized and in the federated learning setting. Our numerical experiments demonstrate that models trained using BSR perform on par with the best existing methods, while completely avoiding their computational overhead.
Deep Neural Collapse Is Provably Optimal for the Deep Unconstrained Features Model
May 22, 2023



Neural collapse (NC) refers to the surprising structure of the last layer of deep neural networks in the terminal phase of gradient descent training. Recently, an increasing amount of experimental evidence has pointed to the propagation of NC to earlier layers of neural networks. However, while the NC in the last layer is well studied theoretically, much less is known about its multi-layered counterpart - deep neural collapse (DNC). In particular, existing work focuses either on linear layers or only on the last two layers at the price of an extra assumption. Our paper fills this gap by generalizing the established analytical framework for NC - the unconstrained features model - to multiple non-linear layers. Our key technical contribution is to show that, in a deep unconstrained features model, the unique global optimum for binary classification exhibits all the properties typical of DNC. This explains the existing experimental evidence of DNC. We also empirically show that (i) by optimizing deep unconstrained features models via gradient descent, the resulting solution agrees well with our theory, and (ii) trained networks recover the unconstrained features suitable for the occurrence of DNC, thus supporting the validity of this modeling principle.
Robust Learning from Untrusted Sources
Jan 29, 2019

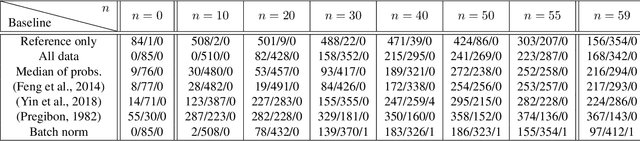
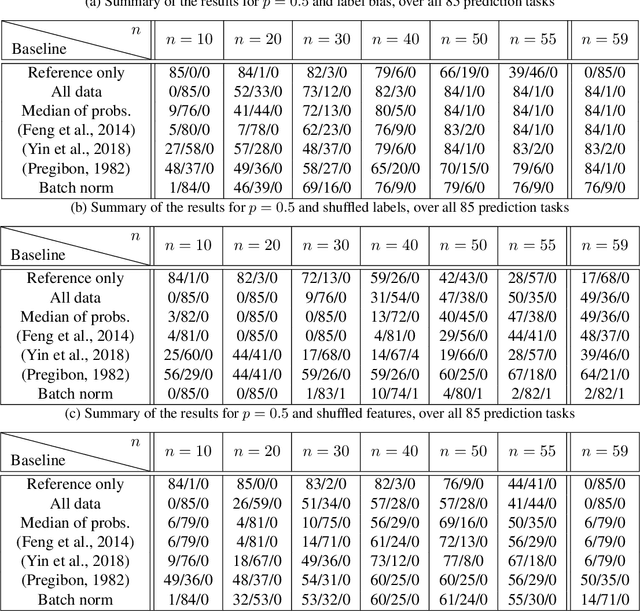
Modern machine learning methods often require more data for training than a single expert can provide. Therefore, it has become a standard procedure to collect data from external sources, e.g. via crowdsourcing. Unfortunately, the quality of these sources is not always guaranteed. As additional complications, the data might be stored in a distributed way, or might even have to remain private. In this work, we address the question of how to learn robustly in such scenarios. Studying the problem through the lens of statistical learning theory, we derive a procedure that allows for learning from all available sources, yet automatically suppresses irrelevant or corrupted data. We show by extensive experiments that our method provides significant improvements over alternative approaches from robust statistics and distributed optimization.
MACRO: A Meta-Algorithm for Conditional Risk Minimization
Nov 03, 2018
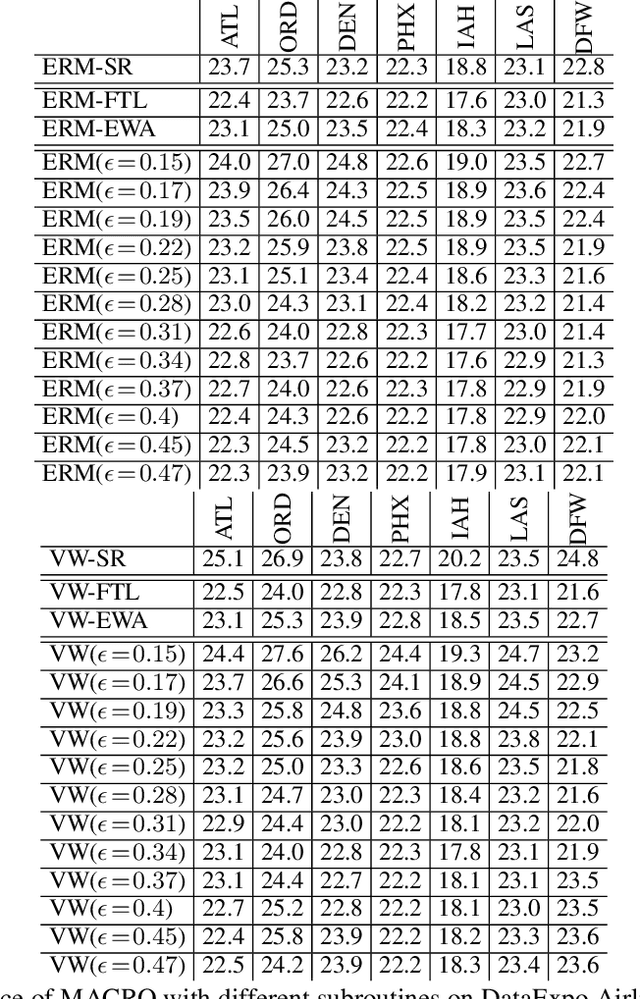

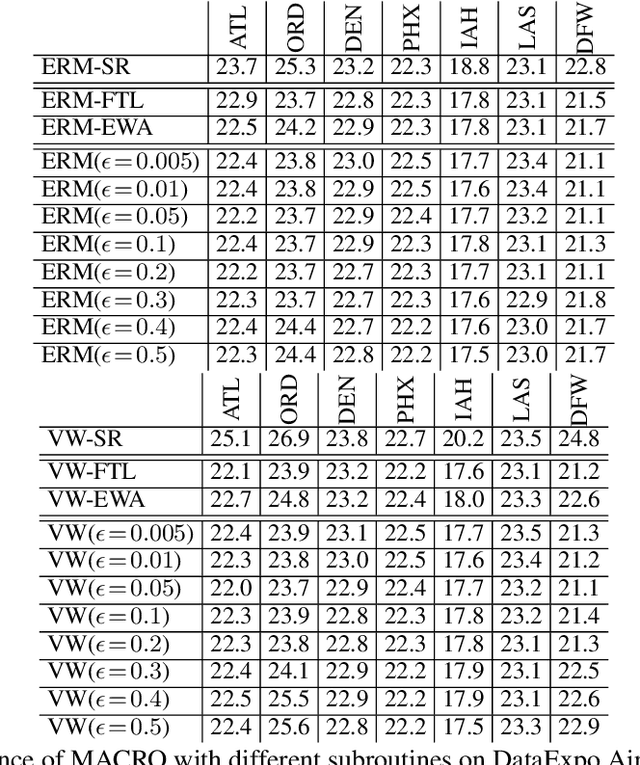
We study conditional risk minimization (CRM), i.e. the problem of learning a hypothesis of minimal risk for prediction at the next step of sequentially arriving dependent data. Despite it being a fundamental problem, successful learning in the CRM sense has so far only been demonstrated using theoretical algorithms that cannot be used for real problems as they would require storing all incoming data. In this work, we introduce MACRO, a meta-algorithm for CRM that does not suffer from this shortcoming, but nevertheless offers learning guarantees. Instead of storing all data it maintains and iteratively updates a set of learning subroutines. With suitable approximations, MACRO applied to real data, yielding improved prediction performance compared to traditional non-conditional learning.
Learning Intelligent Dialogs for Bounding Box Annotation
Mar 28, 2018
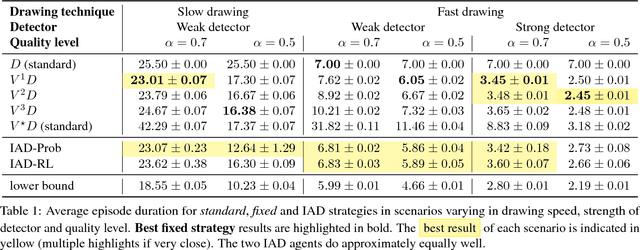
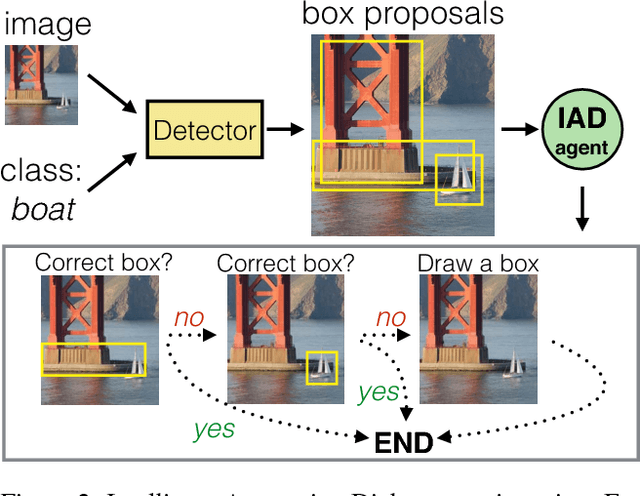
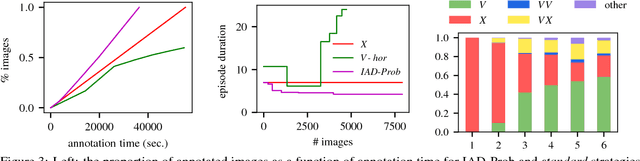
We introduce Intelligent Annotation Dialogs for bounding box annotation. We train an agent to automatically choose a sequence of actions for a human annotator to produce a bounding box in a minimal amount of time. Specifically, we consider two actions: box verification, where the annotator verifies a box generated by an object detector, and manual box drawing. We explore two kinds of agents, one based on predicting the probability that a box will be positively verified, and the other based on reinforcement learning. We demonstrate that (1) our agents are able to learn efficient annotation strategies in several scenarios, automatically adapting to the image difficulty, the desired quality of the boxes, and the detector strength; (2) in all scenarios the resulting annotation dialogs speed up annotation compared to manual box drawing alone and box verification alone, while also outperforming any fixed combination of verification and drawing in most scenarios; (3) in a realistic scenario where the detector is iteratively re-trained, our agents evolve a series of strategies that reflect the shifting trade-off between verification and drawing as the detector grows stronger.
Proceedings of The 38th Annual Workshop of the Austrian Association for Pattern Recognition , 2014
Apr 30, 2014The 38th Annual Workshop of the Austrian Association for Pattern Recognition (\"OAGM) will be held at IST Austria, on May 22-23, 2014. The workshop provides a platform for researchers and industry to discuss traditional and new areas of computer vision. This year the main topic is: Pattern Recognition: interdisciplinary challenges and opportunities.
The Most Persistent Soft-Clique in a Set of Sampled Graphs
Jun 18, 2012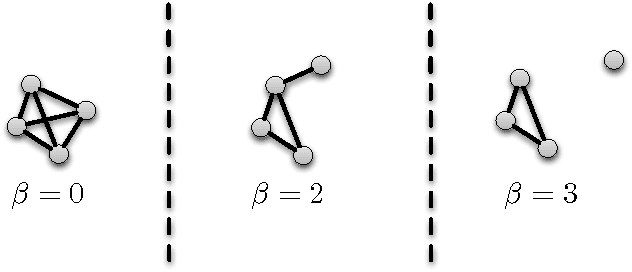
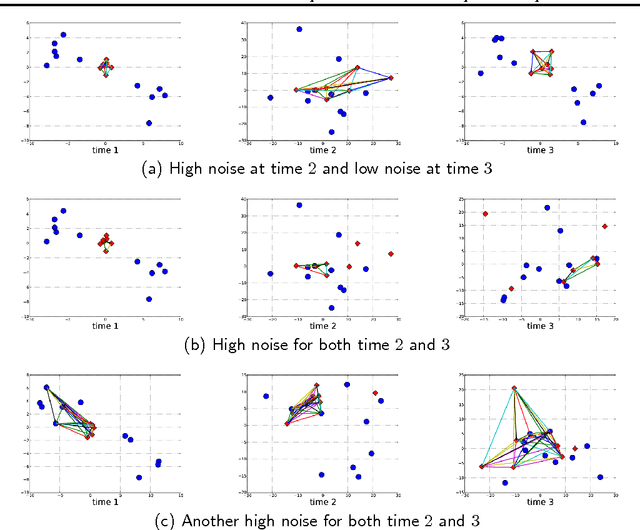
When searching for characteristic subpatterns in potentially noisy graph data, it appears self-evident that having multiple observations would be better than having just one. However, it turns out that the inconsistencies introduced when different graph instances have different edge sets pose a serious challenge. In this work we address this challenge for the problem of finding maximum weighted cliques. We introduce the concept of most persistent soft-clique. This is subset of vertices, that 1) is almost fully or at least densely connected, 2) occurs in all or almost all graph instances, and 3) has the maximum weight. We present a measure of clique-ness, that essentially counts the number of edge missing to make a subset of vertices into a clique. With this measure, we show that the problem of finding the most persistent soft-clique problem can be cast either as: a) a max-min two person game optimization problem, or b) a min-min soft margin optimization problem. Both formulations lead to the same solution when using a partial Lagrangian method to solve the optimization problems. By experiments on synthetic data and on real social network data, we show that the proposed method is able to reliably find soft cliques in graph data, even if that is distorted by random noise or unreliable observations.