 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMACRO: A Meta-Algorithm for Conditional Risk Minimization
Nov 03, 2018
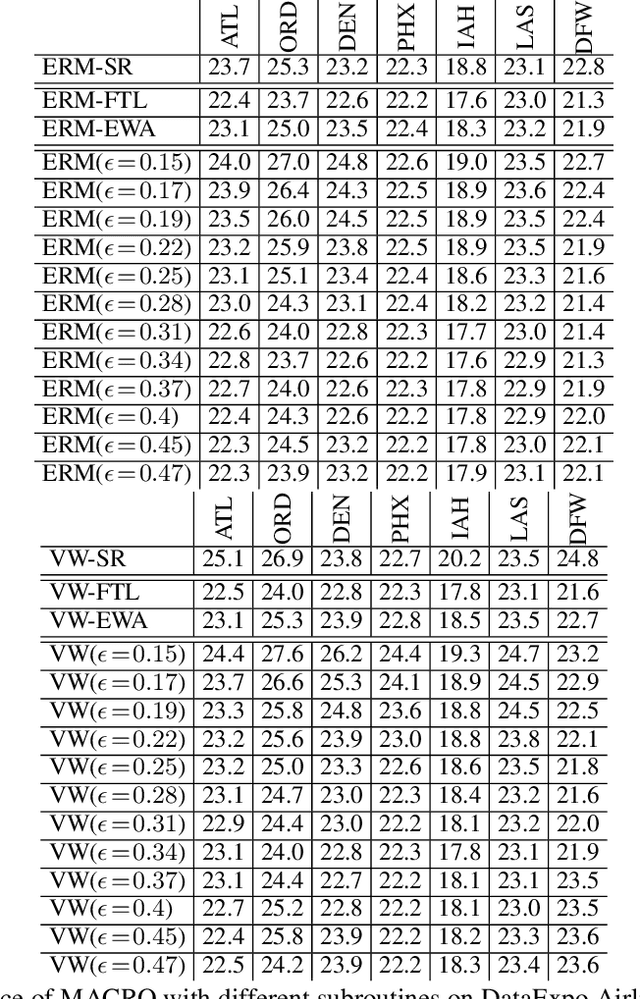

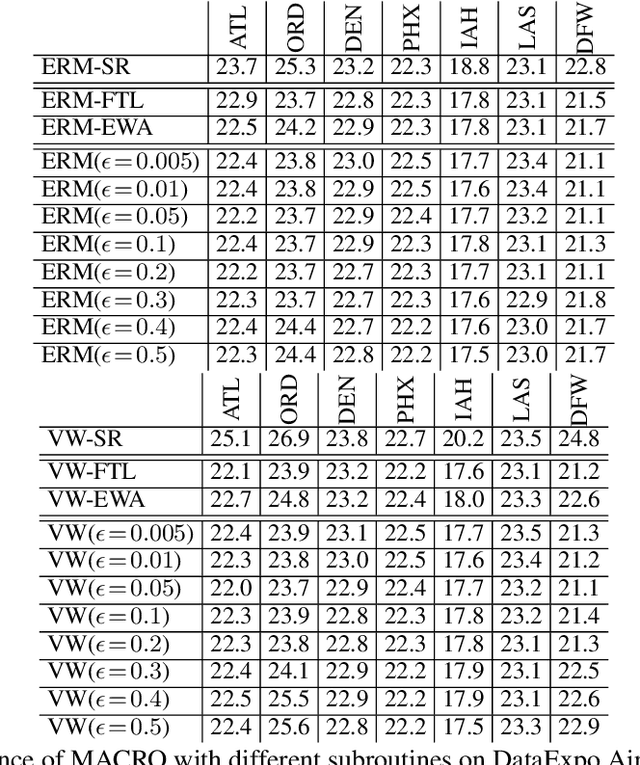
We study conditional risk minimization (CRM), i.e. the problem of learning a hypothesis of minimal risk for prediction at the next step of sequentially arriving dependent data. Despite it being a fundamental problem, successful learning in the CRM sense has so far only been demonstrated using theoretical algorithms that cannot be used for real problems as they would require storing all incoming data. In this work, we introduce MACRO, a meta-algorithm for CRM that does not suffer from this shortcoming, but nevertheless offers learning guarantees. Instead of storing all data it maintains and iteratively updates a set of learning subroutines. With suitable approximations, MACRO applied to real data, yielding improved prediction performance compared to traditional non-conditional learning.
Conditional Risk Minimization for Stochastic Processes
Mar 13, 2016

We study the task of learning from non-i.i.d. data. In particular, we aim at learning predictors that minimize the conditional risk for a stochastic process, i.e. the expected loss of the predictor on the next point conditioned on the set of training samples observed so far. For non-i.i.d. data, the training set contains information about the upcoming samples, so learning with respect to the conditional distribution can be expected to yield better predictors than one obtains from the classical setting of minimizing the marginal risk. Our main contribution is a practical estimator for the conditional risk based on the theory of non-parametric time-series prediction, and a finite sample concentration bound that establishes uniform convergence of the estimator to the true conditional risk under certain regularity assumptions on the process.
Generalized Risk-Aversion in Stochastic Multi-Armed Bandits
May 05, 2014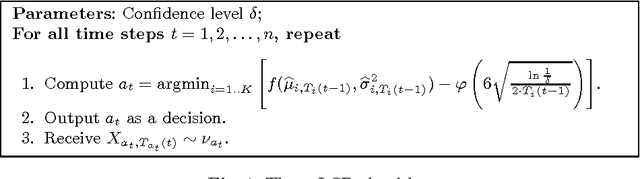

We consider the problem of minimizing the regret in stochastic multi-armed bandit, when the measure of goodness of an arm is not the mean return, but some general function of the mean and the variance.We characterize the conditions under which learning is possible and present examples for which no natural algorithm can achieve sublinear regret.