 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeConditional KRR: Injecting Unpenalized Features into Kernel Methods with Applications to Kernel Thresholding
May 25, 2026Conditionally positive definite (CPD) kernels are defined with respect to a function class $\mathcal{F}$. It is well known that such a kernel $K$ is associated with its native space (defined analogously to an RKHS), which in turn gives rise to a learning method -- called conditional kernel ridge regression (conditional KRR) due to its analogy with KRR -- where the estimated regression function is penalized by the square of its native space norm. This method is of interest because it can be viewed as classical linear regression, with features specified by $\mathcal{F}$, followed by the application of standard KRR to the residual (unexplained) component of the target variable. Methods of this type have recently attracted increasing attention. We study the statistical properties of this method by reducing its behavior to that of KRR with another fixed kernel, called the residual kernel. Our main theoretical result shows that such a reduction is indeed possible, at the cost of an additional term in the expected test risk, bounded by $\mathcal{O}(1/\sqrt{N})$, where $N$ is the sample size and the hidden constant depends on the class $\mathcal{F}$ and the input distribution. This reduction enables us to analyze conditional KRR in the case where $K$ is positive definite and $\mathcal{F}$ is given by the first $k$ principal eigenfunctions in the Mercer decomposition of $K$. We also consider the setting where $\mathcal{F}$ consists of $k$ random features from a random feature representation of $K$. It turns out that these two settings are closely related. Both our theoretical analysis and experiments confirm that conditional KRR outperforms standard KRR in these cases whenever the $\mathcal{F}$-component of the regression function is more pronounced than the residual part.
On the Intrinsic Dimensions of Data in Kernel Learning
Jan 22, 2026The manifold hypothesis suggests that the generalization performance of machine learning methods improves significantly when the intrinsic dimension of the input distribution's support is low. In the context of KRR, we investigate two alternative notions of intrinsic dimension. The first, denoted $d_ρ$, is the upper Minkowski dimension defined with respect to the canonical metric induced by a kernel function $K$ on a domain $Ω$. The second, denoted $d_K$, is the effective dimension, derived from the decay rate of Kolmogorov $n$-widths associated with $K$ on $Ω$. Given a probability measure $μ$ on $Ω$, we analyze the relationship between these $n$-widths and eigenvalues of the integral operator $φ\to \int_ΩK(\cdot,x)φ(x)dμ(x)$. We show that, for a fixed domain $Ω$, the Kolmogorov $n$-widths characterize the worst-case eigenvalue decay across all probability measures $μ$ supported on $Ω$. These eigenvalues are central to understanding the generalization behavior of constrained KRR, enabling us to derive an excess error bound of order $O(n^{-\frac{2+d_K}{2+2d_K} + ε})$ for any $ε> 0$, when the training set size $n$ is large. We also propose an algorithm that estimates upper bounds on the $n$-widths using only a finite sample from $μ$. For distributions close to uniform, we prove that $ε$-accurate upper bounds on all $n$-widths can be computed with high probability using at most $O\left(ε^{-d_ρ}\log\frac{1}ε\right)$ samples, with fewer required for small $n$. Finally, we compute the effective dimension $d_K$ for various fractal sets and present additional numerical experiments. Our results show that, for kernels such as the Laplace kernel, the effective dimension $d_K$ can be significantly smaller than the Minkowski dimension $d_ρ$, even though $d_K = d_ρ$ provably holds on regular domains.
Deep Linear Discriminant Analysis Revisited
Jan 04, 2026We show that for unconstrained Deep Linear Discriminant Analysis (LDA) classifiers, maximum-likelihood training admits pathological solutions in which class means drift together, covariances collapse, and the learned representation becomes almost non-discriminative. Conversely, cross-entropy training yields excellent accuracy but decouples the head from the underlying generative model, leading to highly inconsistent parameter estimates. To reconcile generative structure with discriminative performance, we introduce the \emph{Discriminative Negative Log-Likelihood} (DNLL) loss, which augments the LDA log-likelihood with a simple penalty on the mixture density. DNLL can be interpreted as standard LDA NLL plus a term that explicitly discourages regions where several classes are simultaneously likely. Deep LDA trained with DNLL produces clean, well-separated latent spaces, matches the test accuracy of softmax classifiers on synthetic data and standard image benchmarks, and yields substantially better calibrated predictive probabilities, restoring a coherent probabilistic interpretation to deep discriminant models.
The informativeness of the gradient revisited
May 28, 2025In the past decade gradient-based deep learning has revolutionized several applications. However, this rapid advancement has highlighted the need for a deeper theoretical understanding of its limitations. Research has shown that, in many practical learning tasks, the information contained in the gradient is so minimal that gradient-based methods require an exceedingly large number of iterations to achieve success. The informativeness of the gradient is typically measured by its variance with respect to the random selection of a target function from a hypothesis class. We use this framework and give a general bound on the variance in terms of a parameter related to the pairwise independence of the target function class and the collision entropy of the input distribution. Our bound scales as $ \tilde{\mathcal{O}}(\varepsilon+e^{-\frac{1}{2}\mathcal{E}_c}) $, where $ \tilde{\mathcal{O}} $ hides factors related to the regularity of the learning model and the loss function, $ \varepsilon $ measures the pairwise independence of the target function class and $\mathcal{E}_c$ is the collision entropy of the input distribution. To demonstrate the practical utility of our bound, we apply it to the class of Learning with Errors (LWE) mappings and high-frequency functions. In addition to the theoretical analysis, we present experiments to understand better the nature of recent deep learning-based attacks on LWE.
Multi-layer random features and the approximation power of neural networks
Apr 26, 2024



A neural architecture with randomly initialized weights, in the infinite width limit, is equivalent to a Gaussian Random Field whose covariance function is the so-called Neural Network Gaussian Process kernel (NNGP). We prove that a reproducing kernel Hilbert space (RKHS) defined by the NNGP contains only functions that can be approximated by the architecture. To achieve a certain approximation error the required number of neurons in each layer is defined by the RKHS norm of the target function. Moreover, the approximation can be constructed from a supervised dataset by a random multi-layer representation of an input vector, together with training of the last layer's weights. For a 2-layer NN and a domain equal to an $n-1$-dimensional sphere in ${\mathbb R}^n$, we compare the number of neurons required by Barron's theorem and by the multi-layer features construction. We show that if eigenvalues of the integral operator of the NNGP decay slower than $k^{-n-\frac{2}{3}}$ where $k$ is an order of an eigenvalue, then our theorem guarantees a more succinct neural network approximation than Barron's theorem. We also make some computational experiments to verify our theoretical findings. Our experiments show that realistic neural networks easily learn target functions even when both theorems do not give any guarantees.
Gradient Descent Fails to Learn High-frequency Functions and Modular Arithmetic
Oct 19, 2023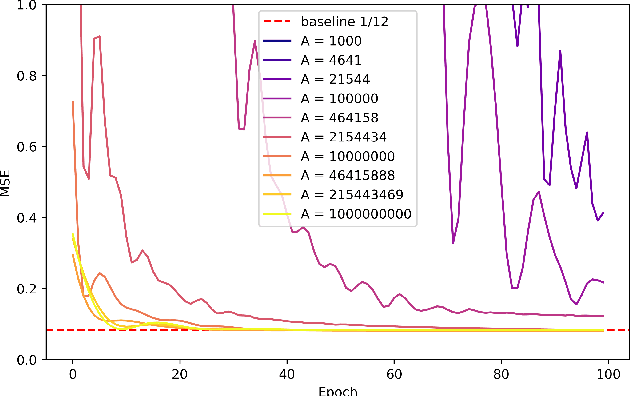

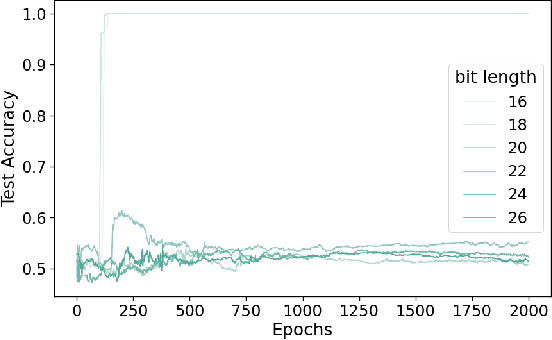
Classes of target functions containing a large number of approximately orthogonal elements are known to be hard to learn by the Statistical Query algorithms. Recently this classical fact re-emerged in a theory of gradient-based optimization of neural networks. In the novel framework, the hardness of a class is usually quantified by the variance of the gradient with respect to a random choice of a target function. A set of functions of the form $x\to ax \bmod p$, where $a$ is taken from ${\mathbb Z}_p$, has attracted some attention from deep learning theorists and cryptographers recently. This class can be understood as a subset of $p$-periodic functions on ${\mathbb Z}$ and is tightly connected with a class of high-frequency periodic functions on the real line. We present a mathematical analysis of limitations and challenges associated with using gradient-based learning techniques to train a high-frequency periodic function or modular multiplication from examples. We highlight that the variance of the gradient is negligibly small in both cases when either a frequency or the prime base $p$ is large. This in turn prevents such a learning algorithm from being successful.
Intractability of Learning the Discrete Logarithm with Gradient-Based Methods
Oct 02, 2023



The discrete logarithm problem is a fundamental challenge in number theory with significant implications for cryptographic protocols. In this paper, we investigate the limitations of gradient-based methods for learning the parity bit of the discrete logarithm in finite cyclic groups of prime order. Our main result, supported by theoretical analysis and empirical verification, reveals the concentration of the gradient of the loss function around a fixed point, independent of the logarithm's base used. This concentration property leads to a restricted ability to learn the parity bit efficiently using gradient-based methods, irrespective of the complexity of the network architecture being trained. Our proof relies on Boas-Bellman inequality in inner product spaces and it involves establishing approximate orthogonality of discrete logarithm's parity bit functions through the spectral norm of certain matrices. Empirical experiments using a neural network-based approach further verify the limitations of gradient-based learning, demonstrating the decreasing success rate in predicting the parity bit as the group order increases.
Autoencoders for a manifold learning problem with a Jacobian rank constraint
Jun 25, 2023We formulate the manifold learning problem as the problem of finding an operator that maps any point to a close neighbor that lies on a ``hidden'' $k$-dimensional manifold. We call this operator the correcting function. Under this formulation, autoencoders can be viewed as a tool to approximate the correcting function. Given an autoencoder whose Jacobian has rank $k$, we deduce from the classical Constant Rank Theorem that its range has a structure of a $k$-dimensional manifold. A $k$-dimensionality of the range can be forced by the architecture of an autoencoder (by fixing the dimension of the code space), or alternatively, by an additional constraint that the rank of the autoencoder mapping is not greater than $k$. This constraint is included in the objective function as a new term, namely a squared Ky-Fan $k$-antinorm of the Jacobian function. We claim that this constraint is a factor that effectively reduces the dimension of the range of an autoencoder, additionally to the reduction defined by the architecture. We also add a new curvature term into the objective. To conclude, we experimentally compare our approach with the CAE+H method on synthetic and real-world datasets.
Computing a partition function of a generalized pattern-based energy over a semiring
May 27, 2023Valued constraint satisfaction problems with ordered variables (VCSPO) are a special case of Valued CSPs in which variables are totally ordered and soft constraints are imposed on tuples of variables that do not violate the order. We study a restriction of VCSPO, in which soft constraints are imposed on a segment of adjacent variables and a constraint language $\Gamma$ consists of $\{0,1\}$-valued characteristic functions of predicates. This kind of potentials generalizes the so-called pattern-based potentials, which were applied in many tasks of structured prediction. For a constraint language $\Gamma$ we introduce a closure operator, $ \overline{\Gamma^{\cap}}\supseteq \Gamma$, and give examples of constraint languages for which $|\overline{\Gamma^{\cap}}|$ is small. If all predicates in $\Gamma$ are cartesian products, we show that the minimization of a generalized pattern-based potential (or, the computation of its partition function) can be made in ${\mathcal O}(|V|\cdot |D|^2 \cdot |\overline{\Gamma^{\cap}}|^2 )$ time, where $V$ is a set of variables, $D$ is a domain set. If, additionally, only non-positive weights of constraints are allowed, the complexity of the minimization task drops to ${\mathcal O}(|V|\cdot |\overline{\Gamma^{\cap}}| \cdot |D| \cdot \max_{\rho\in \Gamma}\|\rho\|^2 )$ where $\|\rho\|$ is the arity of $\rho\in \Gamma$. For a general language $\Gamma$ and non-positive weights, the minimization task can be carried out in ${\mathcal O}(|V|\cdot |\overline{\Gamma^{\cap}}|^2)$ time. We argue that in many natural cases $\overline{\Gamma^{\cap}}$ is of moderate size, though in the worst case $|\overline{\Gamma^{\cap}}|$ can blow up and depend exponentially on $\max_{\rho\in \Gamma}\|\rho\|$.
On the speed of uniform convergence in Mercer's theorem
May 01, 2022The classical Mercer's theorem claims that a continuous positive definite kernel $K({\mathbf x}, {\mathbf y})$ on a compact set can be represented as $\sum_{i=1}^\infty \lambda_i\phi_i({\mathbf x})\phi_i({\mathbf y})$ where $\{(\lambda_i,\phi_i)\}$ are eigenvalue-eigenvector pairs of the corresponding integral operator. This infinite representation is known to converge uniformly to the kernel $K$. We estimate the speed of this convergence in terms of the decay rate of eigenvalues and demonstrate that for $3m$ times differentiable kernels the first $N$ terms of the series approximate $K$ as $\mathcal{O}\big((\sum_{i=N+1}^\infty\lambda_i)^{\frac{m}{m+n}}\big)$ or $\mathcal{O}\big((\sum_{i=N+1}^\infty\lambda^2_i)^{\frac{m}{2m+n}}\big)$.