 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOpenScene: 3D Scene Understanding with Open Vocabularies
Nov 28, 2022



Traditional 3D scene understanding approaches rely on labeled 3D datasets to train a model for a single task with supervision. We propose OpenScene, an alternative approach where a model predicts dense features for 3D scene points that are co-embedded with text and image pixels in CLIP feature space. This zero-shot approach enables task-agnostic training and open-vocabulary queries. For example, to perform SOTA zero-shot 3D semantic segmentation it first infers CLIP features for every 3D point and later classifies them based on similarities to embeddings of arbitrary class labels. More interestingly, it enables a suite of open-vocabulary scene understanding applications that have never been done before. For example, it allows a user to enter an arbitrary text query and then see a heat map indicating which parts of a scene match. Our approach is effective at identifying objects, materials, affordances, activities, and room types in complex 3D scenes, all using a single model trained without any labeled 3D data.
Shape As Points: A Differentiable Poisson Solver
Jun 07, 2021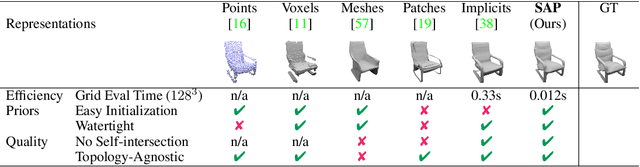
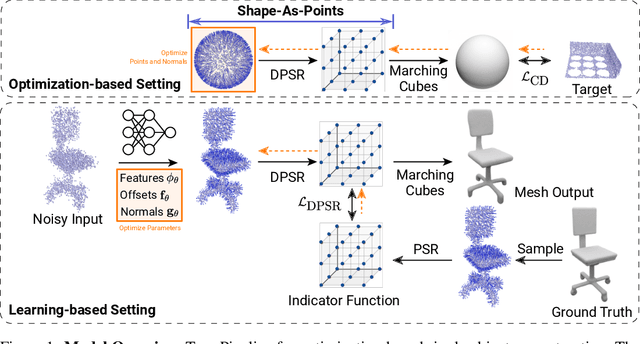

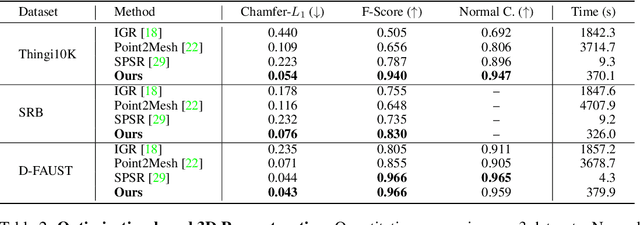
In recent years, neural implicit representations gained popularity in 3D reconstruction due to their expressiveness and flexibility. However, the implicit nature of neural implicit representations results in slow inference time and requires careful initialization. In this paper, we revisit the classic yet ubiquitous point cloud representation and introduce a differentiable point-to-mesh layer using a differentiable formulation of Poisson Surface Reconstruction (PSR) that allows for a GPU-accelerated fast solution of the indicator function given an oriented point cloud. The differentiable PSR layer allows us to efficiently and differentiably bridge the explicit 3D point representation with the 3D mesh via the implicit indicator field, enabling end-to-end optimization of surface reconstruction metrics such as Chamfer distance. This duality between points and meshes hence allows us to represent shapes as oriented point clouds, which are explicit, lightweight and expressive. Compared to neural implicit representations, our Shape-As-Points (SAP) model is more interpretable, lightweight, and accelerates inference time by one order of magnitude. Compared to other explicit representations such as points, patches, and meshes, SAP produces topology-agnostic, watertight manifold surfaces. We demonstrate the effectiveness of SAP on the task of surface reconstruction from unoriented point clouds and learning-based reconstruction.
ShapeFlow: Learnable Deformations Among 3D Shapes
Jun 14, 2020


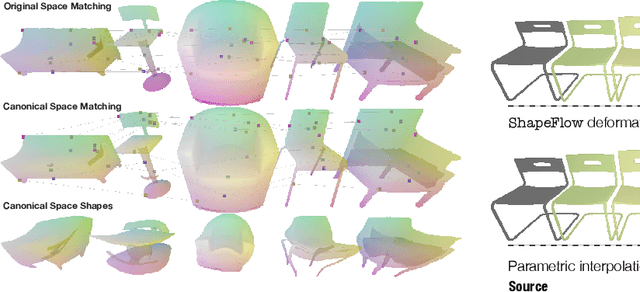
We present ShapeFlow, a flow-based model for learning a deformation space for entire classes of 3D shapes with large intra-class variations. ShapeFlow allows learning a multi-template deformation space that is agnostic to shape topology, yet preserves fine geometric details. Different from a generative space where a latent vector is directly decoded into a shape, a deformation space decodes a vector into a continuous flow that can advect a source shape towards a target. Such a space naturally allows the disentanglement of geometric style (coming from the source) and structural pose (conforming to the target). We parametrize the deformation between geometries as a learned continuous flow field via a neural network and show that such deformations can be guaranteed to have desirable properties, such as be bijectivity, freedom from self-intersections, or volume preservation. We illustrate the effectiveness of this learned deformation space for various downstream applications, including shape generation via deformation, geometric style transfer, unsupervised learning of a consistent parameterization for entire classes of shapes, and shape interpolation.
DDSL: Deep Differentiable Simplex Layer for Learning Geometric Signals
Mar 22, 2019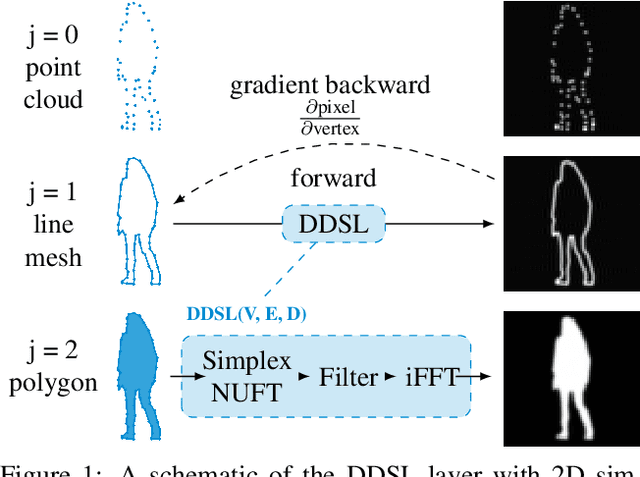

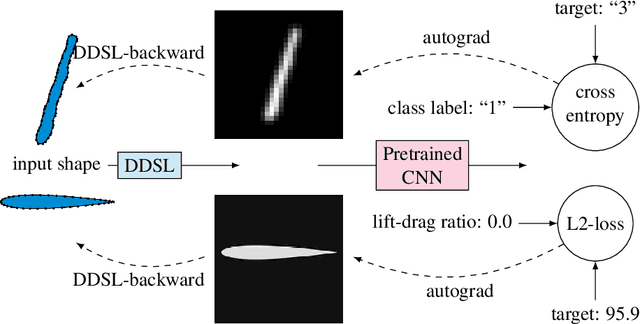

We present a Deep Differentiable Simplex Layer (DDSL) for neural networks for geometric deep learning. The DDSL is a differentiable layer compatible with deep neural networks for bridging simplex mesh-based geometry representations (point clouds, line mesh, triangular mesh, tetrahedral mesh) with raster images (e.g., 2D/3D grids). The DDSL uses Non-Uniform Fourier Transform (NUFT) to perform differentiable, efficient, anti-aliased rasterization of simplex-based signals. We present a complete theoretical framework for the process as well as an efficient backpropagation algorithm. Compared to previous differentiable renderers and rasterizers, the DDSL generalizes to arbitrary simplex degrees and dimensions. In particular, we explore its applications to 2D shapes and illustrate two applications of this method: (1) mesh editing and optimization guided by neural network outputs, and (2) using DDSL for a differentiable rasterization loss to facilitate end-to-end training of polygon generators. We are able to validate the effectiveness of gradient-based shape optimization with the example of airfoil optimization, and using the differentiable rasterization loss to facilitate end-to-end training, we surpass state of the art for polygonal image segmentation given ground-truth bounding boxes.
Convolutional Neural Networks on non-uniform geometrical signals using Euclidean spectral transformation
Jan 07, 2019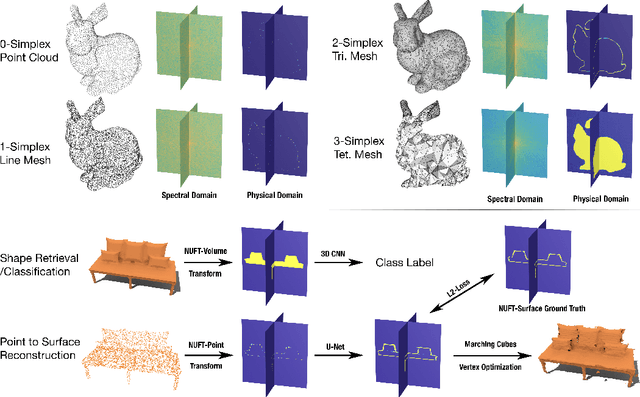
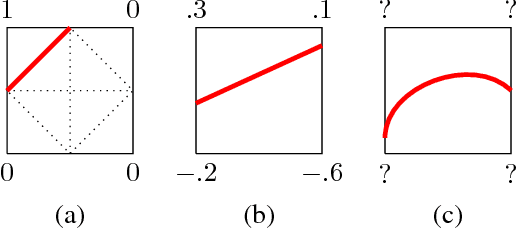
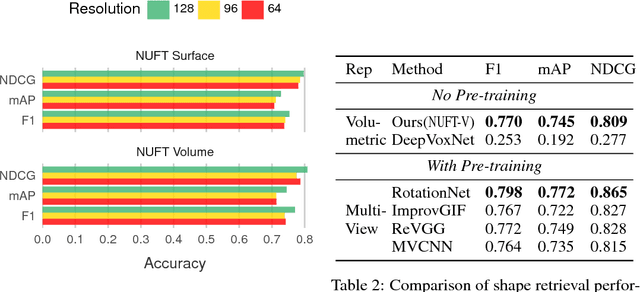
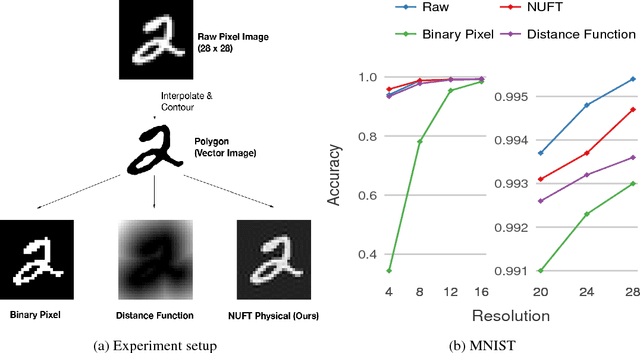
Convolutional Neural Networks (CNN) have been successful in processing data signals that are uniformly sampled in the spatial domain (e.g., images). However, most data signals do not natively exist on a grid, and in the process of being sampled onto a uniform physical grid suffer significant aliasing error and information loss. Moreover, signals can exist in different topological structures as, for example, points, lines, surfaces and volumes. It has been challenging to analyze signals with mixed topologies (for example, point cloud with surface mesh). To this end, we develop mathematical formulations for Non-Uniform Fourier Transforms (NUFT) to directly, and optimally, sample nonuniform data signals of different topologies defined on a simplex mesh into the spectral domain with no spatial sampling error. The spectral transform is performed in the Euclidean space, which removes the translation ambiguity from works on the graph spectrum. Our representation has four distinct advantages: (1) the process causes no spatial sampling error during the initial sampling, (2) the generality of this approach provides a unified framework for using CNNs to analyze signals of mixed topologies, (3) it allows us to leverage state-of-the-art backbone CNN architectures for effective learning without having to design a particular architecture for a particular data structure in an ad-hoc fashion, and (4) the representation allows weighted meshes where each element has a different weight (i.e., texture) indicating local properties. We achieve results on par with the state-of-the-art for the 3D shape retrieval task, and a new state-of-the-art for the point cloud to surface reconstruction task.
Spherical CNNs on Unstructured Grids
Jan 07, 2019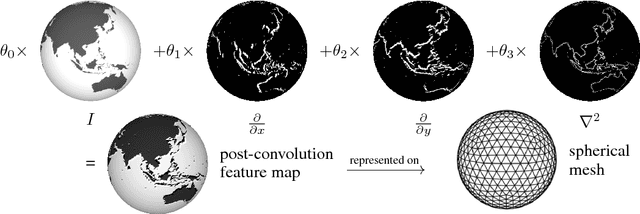
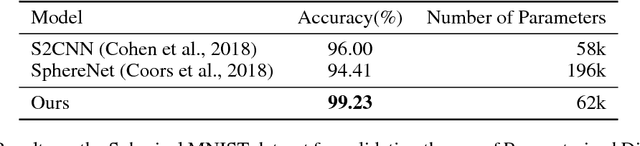
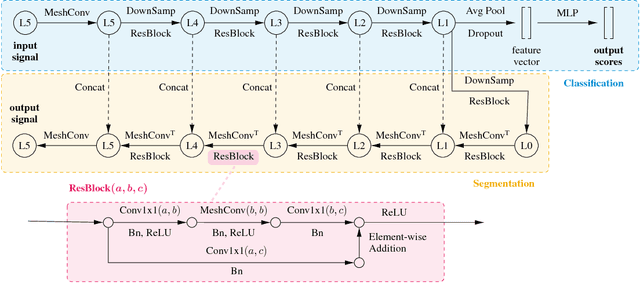

We present an efficient convolution kernel for Convolutional Neural Networks (CNNs) on unstructured grids using parameterized differential operators while focusing on spherical signals such as panorama images or planetary signals. To this end, we replace conventional convolution kernels with linear combinations of differential operators that are weighted by learnable parameters. Differential operators can be efficiently estimated on unstructured grids using one-ring neighbors, and learnable parameters can be optimized through standard back-propagation. As a result, we obtain extremely efficient neural networks that match or outperform state-of-the-art network architectures in terms of performance but with a significantly lower number of network parameters. We evaluate our algorithm in an extensive series of experiments on a variety of computer vision and climate science tasks, including shape classification, climate pattern segmentation, and omnidirectional image semantic segmentation. Overall, we present (1) a novel CNN approach on unstructured grids using parameterized differential operators for spherical signals, and (2) we show that our unique kernel parameterization allows our model to achieve the same or higher accuracy with significantly fewer network parameters.
Hierarchical Detail Enhancing Mesh-Based Shape Generation with 3D Generative Adversarial Network
Sep 22, 2017

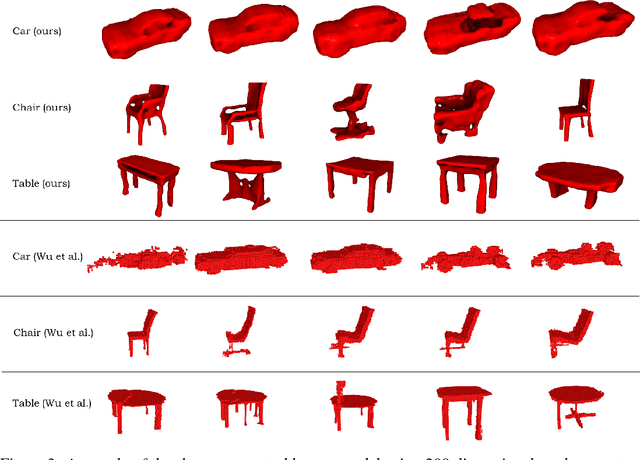

Automatic mesh-based shape generation is of great interest across a wide range of disciplines, from industrial design to gaming, computer graphics and various other forms of digital art. While most traditional methods focus on primitive based model generation, advances in deep learning made it possible to learn 3-dimensional geometric shape representations in an end-to-end manner. However, most current deep learning based frameworks focus on the representation and generation of voxel and point-cloud based shapes, making it not directly applicable to design and graphics communities. This study addresses the needs for automatic generation of mesh-based geometries, and propose a novel framework that utilizes signed distance function representation that generates detail preserving three-dimensional surface mesh by a deep learning based approach.