 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChanging Data Sources in the Age of Machine Learning for Official Statistics
Jun 07, 2023Data science has become increasingly essential for the production of official statistics, as it enables the automated collection, processing, and analysis of large amounts of data. With such data science practices in place, it enables more timely, more insightful and more flexible reporting. However, the quality and integrity of data-science-driven statistics rely on the accuracy and reliability of the data sources and the machine learning techniques that support them. In particular, changes in data sources are inevitable to occur and pose significant risks that are crucial to address in the context of machine learning for official statistics. This paper gives an overview of the main risks, liabilities, and uncertainties associated with changing data sources in the context of machine learning for official statistics. We provide a checklist of the most prevalent origins and causes of changing data sources; not only on a technical level but also regarding ownership, ethics, regulation, and public perception. Next, we highlight the repercussions of changing data sources on statistical reporting. These include technical effects such as concept drift, bias, availability, validity, accuracy and completeness, but also the neutrality and potential discontinuation of the statistical offering. We offer a few important precautionary measures, such as enhancing robustness in both data sourcing and statistical techniques, and thorough monitoring. In doing so, machine learning-based official statistics can maintain integrity, reliability, consistency, and relevance in policy-making, decision-making, and public discourse.
* Presented at UNECE Machine Learning for Official Statistics Workshop 2023
Neural Bayesian Network Understudy
Nov 15, 2022



Bayesian Networks may be appealing for clinical decision-making due to their inclusion of causal knowledge, but their practical adoption remains limited as a result of their inability to deal with unstructured data. While neural networks do not have this limitation, they are not interpretable and are inherently unable to deal with causal structure in the input space. Our goal is to build neural networks that combine the advantages of both approaches. Motivated by the perspective to inject causal knowledge while training such neural networks, this work presents initial steps in that direction. We demonstrate how a neural network can be trained to output conditional probabilities, providing approximately the same functionality as a Bayesian Network. Additionally, we propose two training strategies that allow encoding the independence relations inferred from a given causal structure into the neural network. We present initial results in a proof-of-concept setting, showing that the neural model acts as an understudy to its Bayesian Network counterpart, approximating its probabilistic and causal properties.
Audio-guided Album Cover Art Generation with Genetic Algorithms
Jul 14, 2022

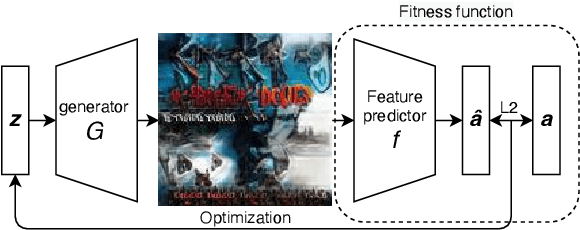
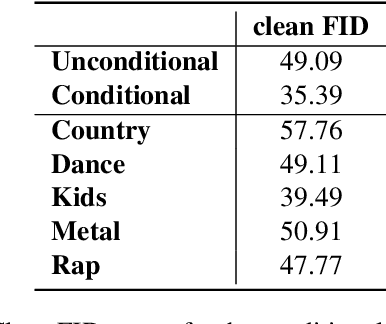
Over 60,000 songs are released on Spotify every day, and the competition for the listener's attention is immense. In that regard, the importance of captivating and inviting cover art cannot be underestimated, because it is deeply entangled with a song's character and the artist's identity, and remains one of the most important gateways to lead people to discover music. However, designing cover art is a highly creative, lengthy and sometimes expensive process that can be daunting, especially for non-professional artists. For this reason, we propose a novel deep-learning framework to generate cover art guided by audio features. Inspired by VQGAN-CLIP, our approach is highly flexible because individual components can easily be replaced without the need for any retraining. This paper outlines the architectural details of our models and discusses the optimization challenges that emerge from them. More specifically, we will exploit genetic algorithms to overcome bad local minima and adversarial examples. We find that our framework can generate suitable cover art for most genres, and that the visual features adapt themselves to audio feature changes. Given these results, we believe that our framework paves the road for extensions and more advanced applications in audio-guided visual generation tasks.
A learning gap between neuroscience and reinforcement learning
May 04, 2021



Historically, artificial intelligence has drawn much inspiration from neuroscience to fuel advances in the field. However, current progress in reinforcement learning is largely focused on benchmark problems that fail to capture many of the aspects that are of interest in neuroscience today. We illustrate this point by extending a T-maze task from neuroscience for use with reinforcement learning algorithms, and show that state-of-the-art algorithms are not capable of solving this problem. Finally, we point out where insights from neuroscience could help explain some of the issues encountered.
Dynamic Narrowing of VAE Bottlenecks Using GECO and $L_0$ Regularization
Mar 25, 2020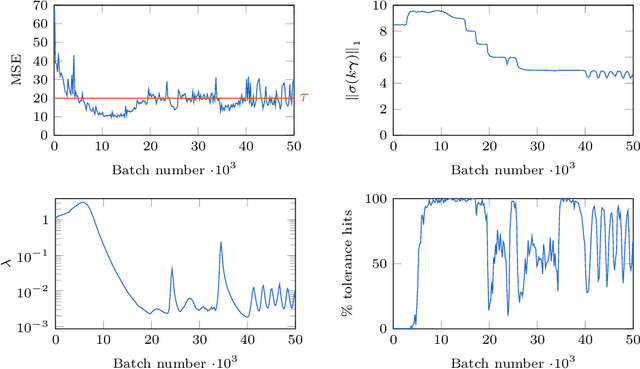
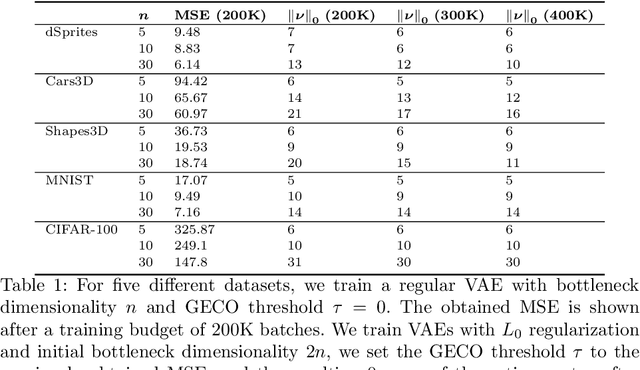
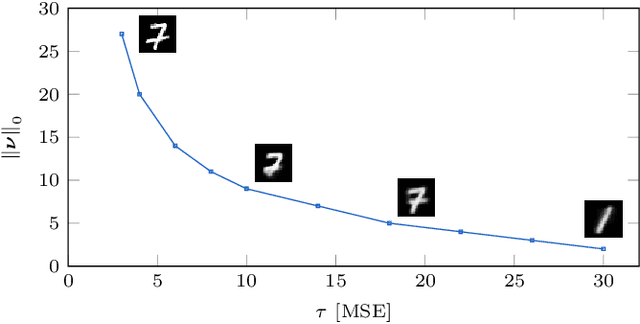

When designing variational autoencoders (VAEs) or other types of latent space models, the dimensionality of the latent space is typically defined upfront. In this process, it is possible that the number of dimensions is under- or overprovisioned for the application at hand. In case the dimensionality is not predefined, this parameter is usually determined using time- and resource-consuming cross-validation. For these reasons we have developed a technique to shrink the latent space dimensionality of VAEs automatically and on-the-fly during training using Generalized ELBO with Constrained Optimization (GECO) and the $L_0$-Augment-REINFORCE-Merge ($L_0$-ARM) gradient estimator. The GECO optimizer ensures that we are not violating a predefined upper bound on the reconstruction error. This paper presents the algorithmic details of our method along with experimental results on five different datasets. We find that our training procedure is stable and that the latent space can be pruned effectively without violating the GECO constraints.
Deep Active Inference for Autonomous Robot Navigation
Mar 06, 2020



Active inference is a theory that underpins the way biological agent's perceive and act in the real world. At its core, active inference is based on the principle that the brain is an approximate Bayesian inference engine, building an internal generative model to drive agents towards minimal surprise. Although this theory has shown interesting results with grounding in cognitive neuroscience, its application remains limited to simulations with small, predefined sensor and state spaces. In this paper, we leverage recent advances in deep learning to build more complex generative models that can work without a predefined states space. State representations are learned end-to-end from real-world, high-dimensional sensory data such as camera frames. We also show that these generative models can be used to engage in active inference. To the best of our knowledge this is the first application of deep active inference for a real-world robot navigation task.
Learning Perception and Planning with Deep Active Inference
Feb 24, 2020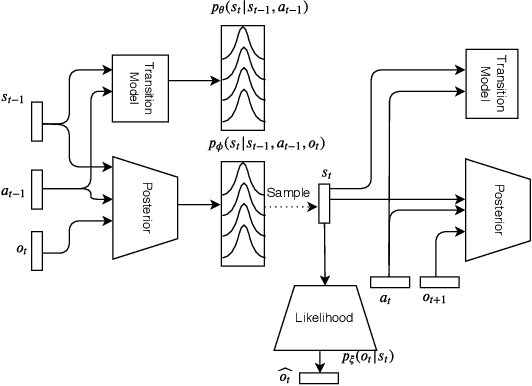
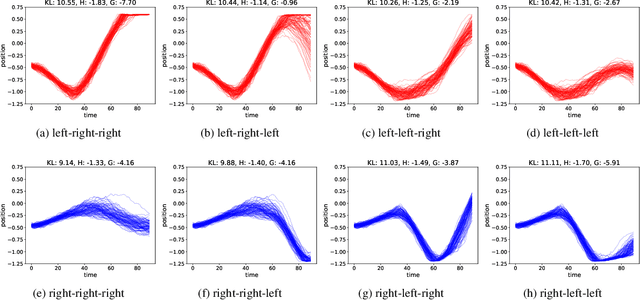
Active inference is a process theory of the brain that states that all living organisms infer actions in order to minimize their (expected) free energy. However, current experiments are limited to predefined, often discrete, state spaces. In this paper we use recent advances in deep learning to learn the state space and approximate the necessary probability distributions to engage in active inference.
Rhythm, Chord and Melody Generation for Lead Sheets using Recurrent Neural Networks
Feb 21, 2020



Music that is generated by recurrent neural networks often lacks a sense of direction and coherence. We therefore propose a two-stage LSTM-based model for lead sheet generation, in which the harmonic and rhythmic templates of the song are produced first, after which, in a second stage, a sequence of melody notes is generated conditioned on these templates. A subjective listening test shows that our approach outperforms the baselines and increases perceived musical coherence.
Learning to Grasp from a Single Demonstration
Jun 09, 2018
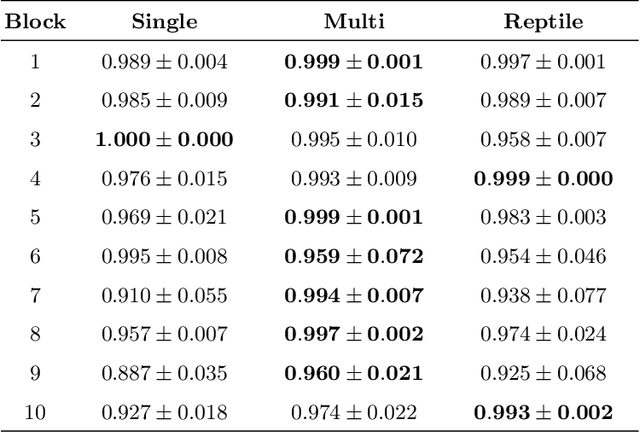


Learning-based approaches for robotic grasping using visual sensors typically require collecting a large size dataset, either manually labeled or by many trial and errors of a robotic manipulator in the real or simulated world. We propose a simpler learning-from-demonstration approach that is able to detect the object to grasp from merely a single demonstration using a convolutional neural network we call GraspNet. In order to increase robustness and decrease the training time even further, we leverage data from previous demonstrations to quickly fine-tune a GrapNet for each new demonstration. We present some preliminary results on a grasping experiment with the Franka Panda cobot for which we can train a GraspNet with only hundreds of train iterations.
Character-level Recurrent Neural Networks in Practice: Comparing Training and Sampling Schemes
Jan 09, 2018
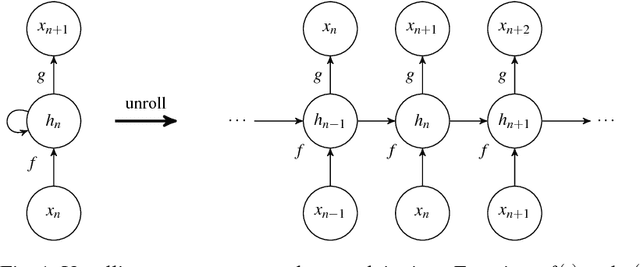
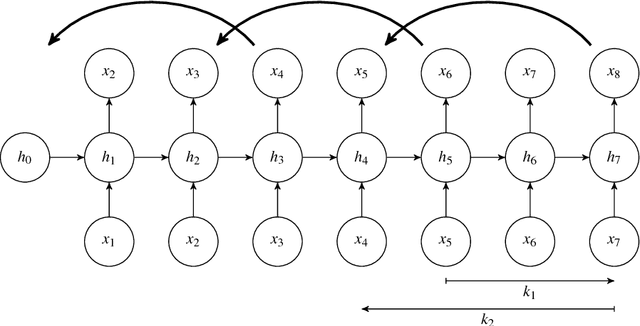
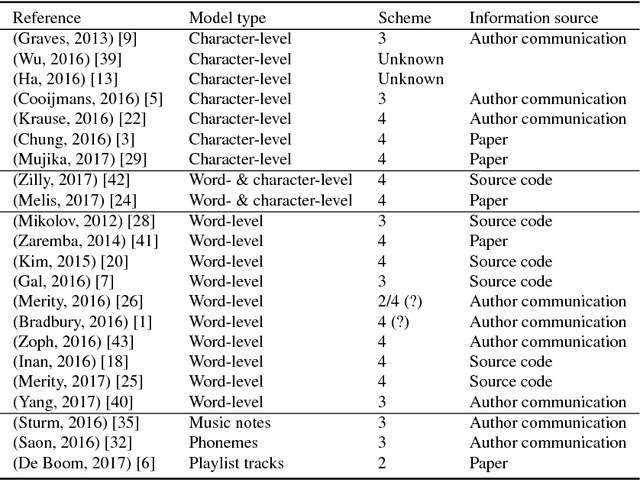
Recurrent neural networks are nowadays successfully used in an abundance of applications, going from text, speech and image processing to recommender systems. Backpropagation through time is the algorithm that is commonly used to train these networks on specific tasks. Many deep learning frameworks have their own implementation of training and sampling procedures for recurrent neural networks, while there are in fact multiple other possibilities to choose from and other parameters to tune. In existing literature this is very often overlooked or ignored. In this paper we therefore give an overview of possible training and sampling schemes for character-level recurrent neural networks to solve the task of predicting the next token in a given sequence. We test these different schemes on a variety of datasets, neural network architectures and parameter settings, and formulate a number of take-home recommendations. The choice of training and sampling scheme turns out to be subject to a number of trade-offs, such as training stability, sampling time, model performance and implementation effort, but is largely independent of the data. Perhaps the most surprising result is that transferring hidden states for correctly initializing the model on subsequences often leads to unstable training behavior depending on the dataset.