 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvent-VStream: Event-Driven Real-Time Understanding for Long Video Streams
Jan 22, 2026Real-time understanding of long video streams remains challenging for multimodal large language models (VLMs) due to redundant frame processing and rapid forgetting of past context. Existing streaming systems rely on fixed-interval decoding or cache pruning, which either produce repetitive outputs or discard crucial temporal information. We introduce Event-VStream, an event-aware framework that represents continuous video as a sequence of discrete, semantically coherent events. Our system detects meaningful state transitions by integrating motion, semantic, and predictive cues, and triggers language generation only at those boundaries. Each event embedding is consolidated into a persistent memory bank, enabling long-horizon reasoning while maintaining low latency. Across OVOBench-Realtime, and long-form Ego4D evaluations, Event-VStream achieves competitive performance. It improves over a VideoLLM-Online-8B baseline by +10.4 points on OVOBench-Realtime, achieves performance close to Flash-VStream-7B despite using only a general-purpose LLaMA-3-8B text backbone, and maintains around 70% GPT-5 win rate on 2-hour Ego4D streams.
SDiT: Semantic Region-Adaptive for Diffusion Transformers
Jan 18, 2026Diffusion Transformers (DiTs) achieve state-of-the-art performance in text-to-image synthesis but remain computationally expensive due to the iterative nature of denoising and the quadratic cost of global attention. In this work, we observe that denoising dynamics are spatially non-uniform-background regions converge rapidly while edges and textured areas evolve much more actively. Building on this insight, we propose SDiT, a Semantic Region-Adaptive Diffusion Transformer that allocates computation according to regional complexity. SDiT introduces a training-free framework combining (1) semantic-aware clustering via fast Quickshift-based segmentation, (2) complexity-driven regional scheduling to selectively update informative areas, and (3) boundary-aware refinement to maintain spatial coherence. Without any model retraining or architectural modification, SDiT achieves up to 3.0x acceleration while preserving nearly identical perceptual and semantic quality to full-attention inference.
DNP-Guided Contrastive Reconstruction with a Reverse Distillation Transformer for Medical Anomaly Detection
Aug 27, 2025Anomaly detection in medical images is challenging due to limited annotations and a domain gap compared to natural images. Existing reconstruction methods often rely on frozen pre-trained encoders, which limits adaptation to domain-specific features and reduces localization accuracy. Prototype-based learning offers interpretability and clustering benefits but suffers from prototype collapse, where few prototypes dominate training, harming diversity and generalization. To address this, we propose a unified framework combining a trainable encoder with prototype-guided reconstruction and a novel Diversity-Aware Alignment Loss. The trainable encoder, enhanced by a momentum branch, enables stable domain-adaptive feature learning. A lightweight Prototype Extractor mines informative normal prototypes to guide the decoder via attention for precise reconstruction. Our loss enforces balanced prototype use through diversity constraints and per-prototype normalization, effectively preventing collapse. Experiments on multiple medical imaging benchmarks show significant improvements in representation quality and anomaly localization, outperforming prior methods. Visualizations and prototype assignment analyses further validate the effectiveness of our anti-collapse mechanism and enhanced interpretability.
Fast LLMMSE filter for low-dose CT imaging
Mar 23, 2019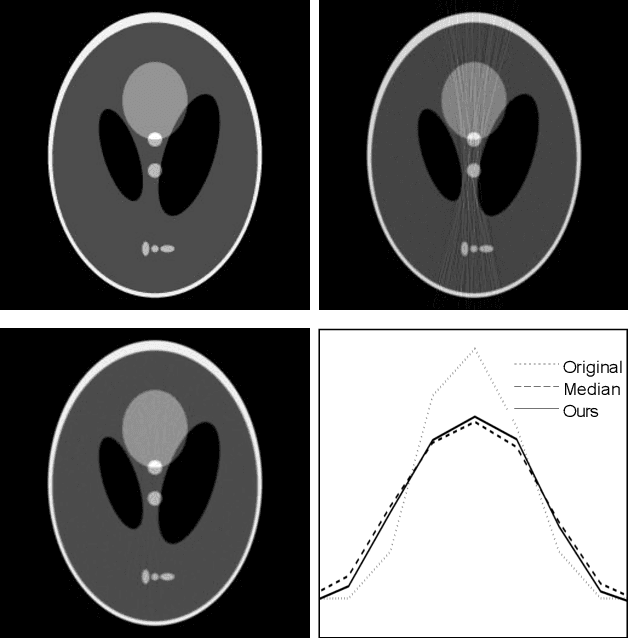

Low-dose X-ray CT technology is one of important directions of current research and development of medical imaging equipment. A fast algorithm of blockwise sinogram filtering is presented for realtime low-dose CT imaging. A nonstationary Gaussian noise model of low-dose sinogram data is proposed in the low-mA (tube current) CT protocol. Then, according to the linear minimum mean square error principle, an adaptive blockwise algorithm is built to filter contaminated sinogram data caused by photon starvation. A moving sum technique is used to speed the algorithm into a linear time one, regardless of the block size and thedata range. The proposedfast filtering givesa better performance in noise reduction and detail preservation in the reconstructed images,which is verified in experiments on simulated and real data compared with some related filtering methods.
Optical Fringe Patterns Filtering Based on Multi-Stage Convolution Neural Network
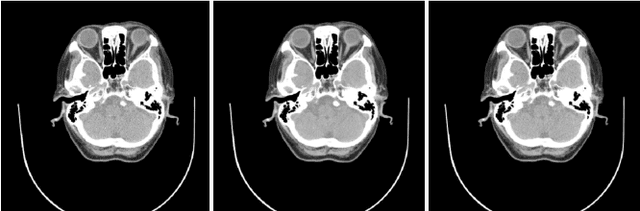
Jan 02, 2019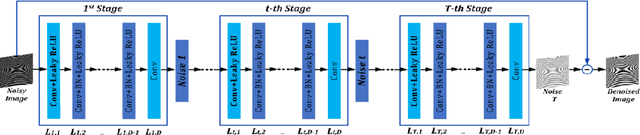
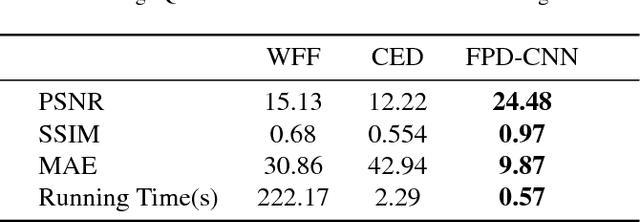


Optical fringe patterns are often contaminated by speckle noise, making it difficult to accurately and robustly extract their phase fields. Thereupon we propose a filtering method based on deep learning, called optical fringe patterns denoising convolutional neural network (FPD-CNN), for directly removing speckle from the input noisy fringe patterns. The FPD-CNN method is divided into multiple stages, each stage consists of a set of convolutional layers along with batch normalization and leaky rectified linear unit (Leaky ReLU) activation function. The end-to-end joint training is carried out using the Euclidean loss. Extensive experiments on simulated and experimental optical fringe patterns, specially finer ones with high density, show that the proposed method is superior to some state-of-the-art denoising techniques in spatial or transform domains, efficiently preserving main features of fringe at a fairly fast speed.