 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEvaluation of Winning Solutions of 2025 Low Power Computer Vision Challenge
Apr 22, 2026The IEEE Low-Power Computer Vision Challenge (LPCVC) aims to promote the development of efficient vision models for edge devices, balancing accuracy with constraints such as latency, memory capacity, and energy use. The 2025 challenge featured three tracks: (1) Image classification under various lighting conditions and styles, (2) Open-Vocabulary Segmentation with Text Prompt, and (3) Monocular Depth Estimation. This paper presents the design of LPCVC 2025, including its competition structure and evaluation framework, which integrates the Qualcomm AI Hub for consistent and reproducible benchmarking. The paper also introduces the top-performing solutions from each track and outlines key trends and observations. The paper concludes with suggestions for future computer vision competitions.
PredMapNet: Future and Historical Reasoning for Consistent Online HD Vectorized Map Construction
Feb 18, 2026High-definition (HD) maps are crucial to autonomous driving, providing structured representations of road elements to support navigation and planning. However, existing query-based methods often employ random query initialization and depend on implicit temporal modeling, which lead to temporal inconsistencies and instabilities during the construction of a global map. To overcome these challenges, we introduce a novel end-to-end framework for consistent online HD vectorized map construction, which jointly performs map instance tracking and short-term prediction. First, we propose a Semantic-Aware Query Generator that initializes queries with spatially aligned semantic masks to capture scene-level context globally. Next, we design a History Rasterized Map Memory to store fine-grained instance-level maps for each tracked instance, enabling explicit historical priors. A History-Map Guidance Module then integrates rasterized map information into track queries, improving temporal continuity. Finally, we propose a Short-Term Future Guidance module to forecast the immediate motion of map instances based on the stored history trajectories. These predicted future locations serve as hints for tracked instances to further avoid implausible predictions and keep temporal consistency. Extensive experiments on the nuScenes and Argoverse2 datasets demonstrate that our proposed method outperforms state-of-the-art (SOTA) methods with good efficiency.
CIS-BA: Continuous Interaction Space Based Backdoor Attack for Object Detection in the Real-World
Dec 16, 2025Object detection models deployed in real-world applications such as autonomous driving face serious threats from backdoor attacks. Despite their practical effectiveness,existing methods are inherently limited in both capability and robustness due to their dependence on single-trigger-single-object mappings and fragile pixel-level cues. We propose CIS-BA, a novel backdoor attack paradigm that redefines trigger design by shifting from static object features to continuous inter-object interaction patterns that describe how objects co-occur and interact in a scene. By modeling these patterns as a continuous interaction space, CIS-BA introduces space triggers that, for the first time, enable a multi-trigger-multi-object attack mechanism while achieving robustness through invariant geometric relations. To implement this paradigm, we design CIS-Frame, which constructs space triggers via interaction analysis, formalizes them as class-geometry constraints for sample poisoning, and embeds the backdoor during detector training. CIS-Frame supports both single-object attacks (object misclassification and disappearance) and multi-object simultaneous attacks, enabling complex and coordinated effects across diverse interaction states. Experiments on MS-COCO and real-world videos show that CIS-BA achieves over 97% attack success under complex environments and maintains over 95% effectiveness under dynamic multi-trigger conditions, while evading three state-of-the-art defenses. In summary, CIS-BA extends the landscape of backdoor attacks in interaction-intensive scenarios and provides new insights into the security of object detection systems.
APT-MMF: An advanced persistent threat actor attribution method based on multimodal and multilevel feature fusion
Feb 20, 2024



Threat actor attribution is a crucial defense strategy for combating advanced persistent threats (APTs). Cyber threat intelligence (CTI), which involves analyzing multisource heterogeneous data from APTs, plays an important role in APT actor attribution. The current attribution methods extract features from different CTI perspectives and employ machine learning models to classify CTI reports according to their threat actors. However, these methods usually extract only one kind of feature and ignore heterogeneous information, especially the attributes and relations of indicators of compromise (IOCs), which form the core of CTI. To address these problems, we propose an APT actor attribution method based on multimodal and multilevel feature fusion (APT-MMF). First, we leverage a heterogeneous attributed graph to characterize APT reports and their IOC information. Then, we extract and fuse multimodal features, including attribute type features, natural language text features and topological relationship features, to construct comprehensive node representations. Furthermore, we design multilevel heterogeneous graph attention networks to learn the deep hidden features of APT report nodes; these networks integrate IOC type-level, metapath-based neighbor node-level, and metapath semantic-level attention. Utilizing multisource threat intelligence, we construct a heterogeneous attributed graph dataset for verification purposes. The experimental results show that our method not only outperforms the existing methods but also demonstrates its good interpretability for attribution analysis tasks.
Student-friendly Knowledge Distillation
May 18, 2023In knowledge distillation, the knowledge from the teacher model is often too complex for the student model to thoroughly process. However, good teachers in real life always simplify complex material before teaching it to students. Inspired by this fact, we propose student-friendly knowledge distillation (SKD) to simplify teacher output into new knowledge representations, which makes the learning of the student model easier and more effective. SKD contains a softening processing and a learning simplifier. First, the softening processing uses the temperature hyperparameter to soften the output logits of the teacher model, which simplifies the output to some extent and makes it easier for the learning simplifier to process. The learning simplifier utilizes the attention mechanism to further simplify the knowledge of the teacher model and is jointly trained with the student model using the distillation loss, which means that the process of simplification is correlated with the training objective of the student model and ensures that the simplified new teacher knowledge representation is more suitable for the specific student model. Furthermore, since SKD does not change the form of the distillation loss, it can be easily combined with other distillation methods that are based on the logits or features of intermediate layers to enhance its effectiveness. Therefore, SKD has wide applicability. The experimental results on the CIFAR-100 and ImageNet datasets show that our method achieves state-of-the-art performance while maintaining high training efficiency.
MG-SAGC: A multiscale graph and its self-adaptive graph convolution network for 3D point clouds
Dec 23, 2020


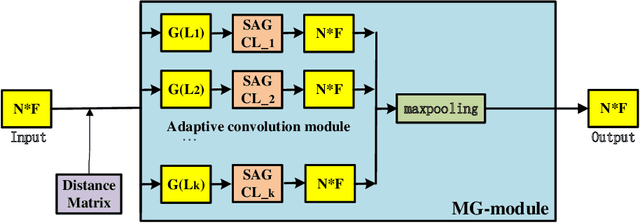
To enhance the ability of neural networks to extract local point cloud features and improve their quality, in this paper, we propose a multiscale graph generation method and a self-adaptive graph convolution method. First, we propose a multiscale graph generation method for point clouds. This approach transforms point clouds into a structured multiscale graph form that supports multiscale analysis of point clouds in the scale space and can obtain the dimensional features of point cloud data at different scales, thus making it easier to obtain the best point cloud features. Because traditional convolutional neural networks are not applicable to graph data with irregular vertex neighborhoods, this paper presents an sef-adaptive graph convolution kernel that uses the Chebyshev polynomial to fit an irregular convolution filter based on the theory of optimal approximation. In this paper, we adopt max pooling to synthesize the features of different scale maps and generate the point cloud features. In experiments conducted on three widely used public datasets, the proposed method significantly outperforms other state-of-the-art models, demonstrating its effectiveness and generalizability.
Query-Adaptive Hash Code Ranking for Large-Scale Multi-View Visual Search
Apr 18, 2019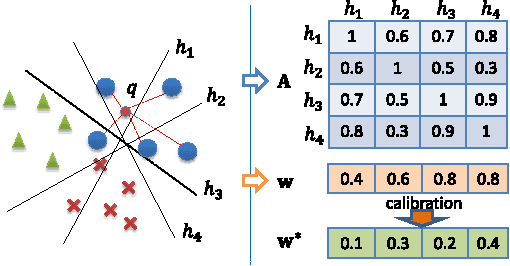

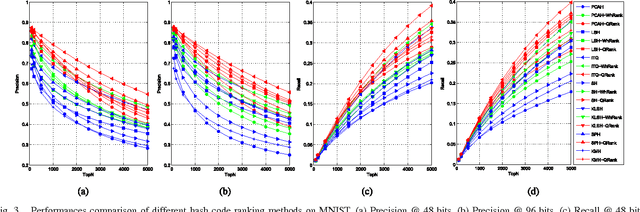

Hash based nearest neighbor search has become attractive in many applications. However, the quantization in hashing usually degenerates the discriminative power when using Hamming distance ranking. Besides, for large-scale visual search, existing hashing methods cannot directly support the efficient search over the data with multiple sources, and while the literature has shown that adaptively incorporating complementary information from diverse sources or views can significantly boost the search performance. To address the problems, this paper proposes a novel and generic approach to building multiple hash tables with multiple views and generating fine-grained ranking results at bitwise and tablewise levels. For each hash table, a query-adaptive bitwise weighting is introduced to alleviate the quantization loss by simultaneously exploiting the quality of hash functions and their complement for nearest neighbor search. From the tablewise aspect, multiple hash tables are built for different data views as a joint index, over which a query-specific rank fusion is proposed to rerank all results from the bitwise ranking by diffusing in a graph. Comprehensive experiments on image search over three well-known benchmarks show that the proposed method achieves up to 17.11% and 20.28% performance gains on single and multiple table search over state-of-the-art methods.
Decorrelated Batch Normalization
Apr 23, 2018

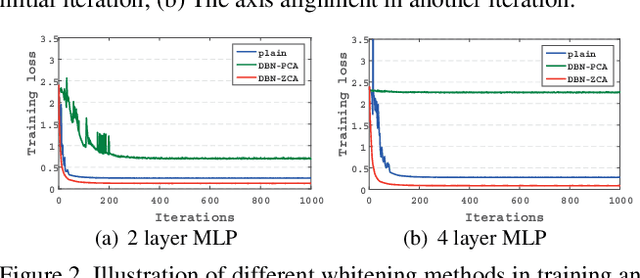

Batch Normalization (BN) is capable of accelerating the training of deep models by centering and scaling activations within mini-batches. In this work, we propose Decorrelated Batch Normalization (DBN), which not just centers and scales activations but whitens them. We explore multiple whitening techniques, and find that PCA whitening causes a problem we call stochastic axis swapping, which is detrimental to learning. We show that ZCA whitening does not suffer from this problem, permitting successful learning. DBN retains the desirable qualities of BN and further improves BN's optimization efficiency and generalization ability. We design comprehensive experiments to show that DBN can improve the performance of BN on multilayer perceptrons and convolutional neural networks. Furthermore, we consistently improve the accuracy of residual networks on CIFAR-10, CIFAR-100, and ImageNet.
DGCNN: Disordered Graph Convolutional Neural Network Based on the Gaussian Mixture Model
Dec 10, 2017
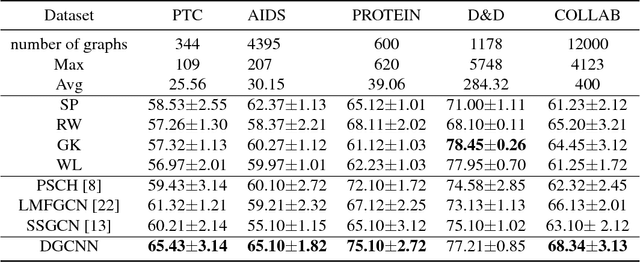

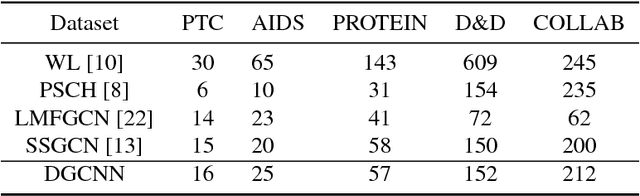
Convolutional neural networks (CNNs) can be applied to graph similarity matching, in which case they are called graph CNNs. Graph CNNs are attracting increasing attention due to their effectiveness and efficiency. However, the existing convolution approaches focus only on regular data forms and require the transfer of the graph or key node neighborhoods of the graph into the same fixed form. During this transfer process, structural information of the graph can be lost, and some redundant information can be incorporated. To overcome this problem, we propose the disordered graph convolutional neural network (DGCNN) based on the mixed Gaussian model, which extends the CNN by adding a preprocessing layer called the disordered graph convolutional layer (DGCL). The DGCL uses a mixed Gaussian function to realize the mapping between the convolution kernel and the nodes in the neighborhood of the graph. The output of the DGCL is the input of the CNN. We further implement a backward-propagation optimization process of the convolutional layer by which we incorporate the feature-learning model of the irregular node neighborhood structure into the network. Thereafter, the optimization of the convolution kernel becomes part of the neural network learning process. The DGCNN can accept arbitrary scaled and disordered neighborhood graph structures as the receptive fields of CNNs, which reduces information loss during graph transformation. Finally, we perform experiments on multiple standard graph datasets. The results show that the proposed method outperforms the state-of-the-art methods in graph classification and retrieval.
Calculating Semantic Similarity between Academic Articles using Topic Event and Ontology
Nov 30, 2017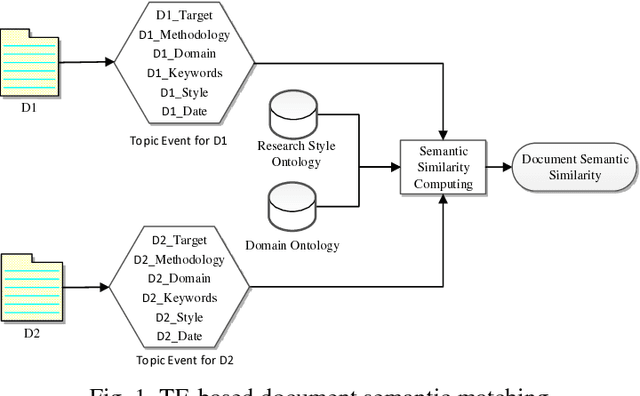
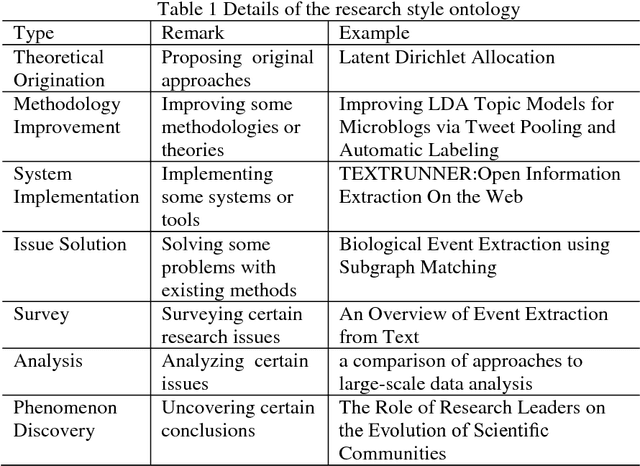

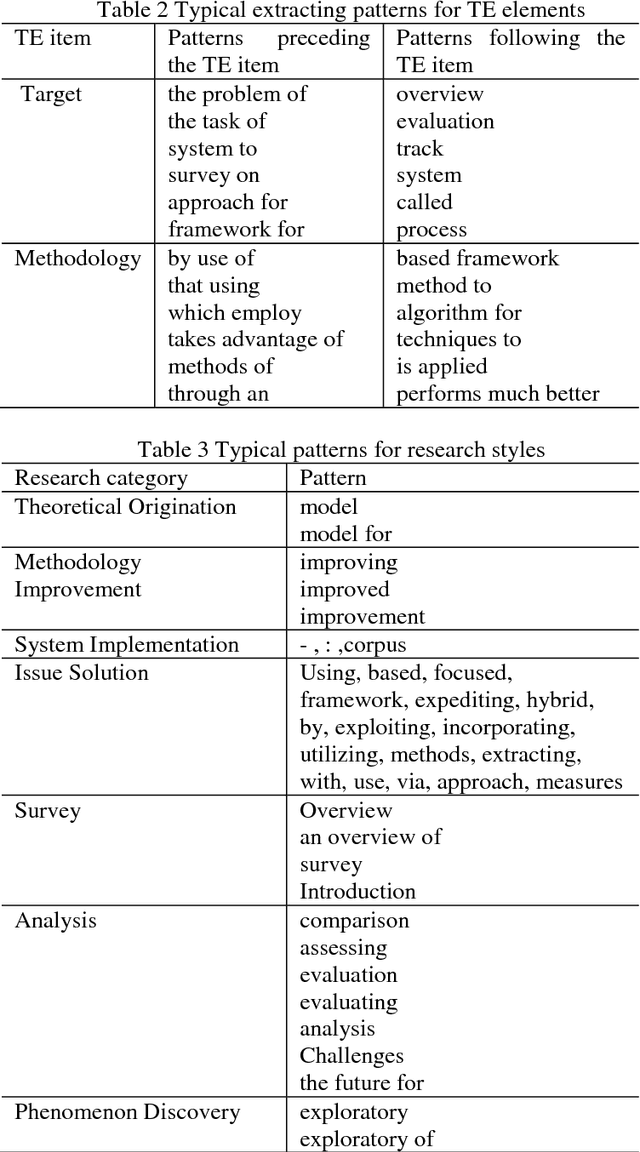
Determining semantic similarity between academic documents is crucial to many tasks such as plagiarism detection, automatic technical survey and semantic search. Current studies mostly focus on semantic similarity between concepts, sentences and short text fragments. However, document-level semantic matching is still based on statistical information in surface level, neglecting article structures and global semantic meanings, which may cause the deviation in document understanding. In this paper, we focus on the document-level semantic similarity issue for academic literatures with a novel method. We represent academic articles with topic events that utilize multiple information profiles, such as research purposes, methodologies and domains to integrally describe the research work, and calculate the similarity between topic events based on the domain ontology to acquire the semantic similarity between articles. Experiments show that our approach achieves significant performance compared to state-of-the-art methods.