 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScalable and non-iterative graphical model estimation
Aug 21, 2024



Graphical models have found widespread applications in many areas of modern statistics and machine learning. Iterative Proportional Fitting (IPF) and its variants have become the default method for undirected graphical model estimation, and are thus ubiquitous in the field. As the IPF is an iterative approach, it is not always readily scalable to modern high-dimensional data regimes. In this paper we propose a novel and fast non-iterative method for positive definite graphical model estimation in high dimensions, one that directly addresses the shortcomings of IPF and its variants. In addition, the proposed method has a number of other attractive properties. First, we show formally that as the dimension p grows, the proportion of graphs for which the proposed method will outperform the state-of-the-art in terms of computational complexity and performance tends to 1, affirming its efficacy in modern settings. Second, the proposed approach can be readily combined with scalable non-iterative thresholding-based methods for high-dimensional sparsity selection. Third, the proposed method has high-dimensional statistical guarantees. Moreover, our numerical experiments also show that the proposed method achieves scalability without compromising on statistical precision. Fourth, unlike the IPF, which depends on the Gaussian likelihood, the proposed method is much more robust.
Hierarchical Relational Learning for Few-Shot Knowledge Graph Completion
Sep 16, 2022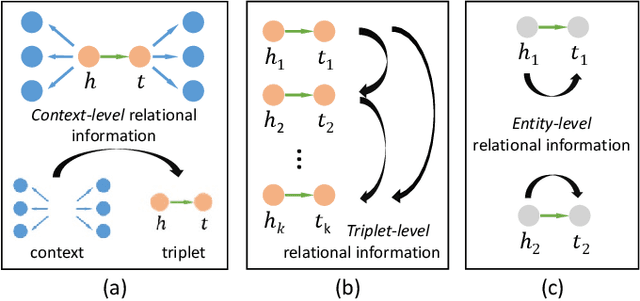


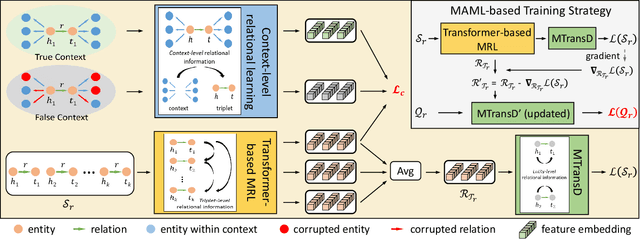
Knowledge graphs (KGs) are known for their large scale and knowledge inference ability, but are also notorious for the incompleteness associated with them. Due to the long-tail distribution of the relations in KGs, few-shot KG completion has been proposed as a solution to alleviate incompleteness and expand the coverage of KGs. It aims to make predictions for triplets involving novel relations when only a few training triplets are provided as reference. Previous methods have mostly focused on designing local neighbor aggregators to learn entity-level information and/or imposing sequential dependency assumption at the triplet level to learn meta relation information. However, valuable pairwise triplet-level interactions and context-level relational information have been largely overlooked for learning meta representations of few-shot relations. In this paper, we propose a hierarchical relational learning method (HiRe) for few-shot KG completion. By jointly capturing three levels of relational information (entity-level, triplet-level and context-level), HiRe can effectively learn and refine the meta representation of few-shot relations, and consequently generalize very well to new unseen relations. Extensive experiments on two benchmark datasets validate the superiority of HiRe against other state-of-the-art methods.
Two-stage Sampling, Prediction and Adaptive Regression via Correlation Screening (SPARCS)
Oct 02, 2016

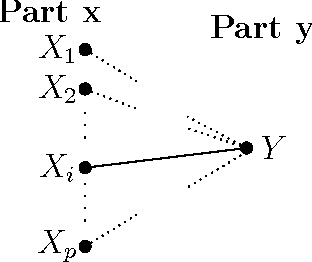
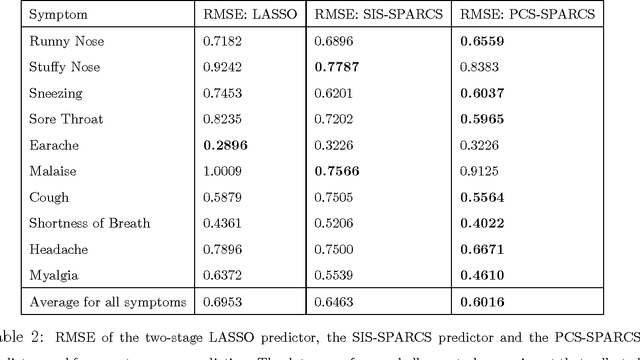
This paper proposes a general adaptive procedure for budget-limited predictor design in high dimensions called two-stage Sampling, Prediction and Adaptive Regression via Correlation Screening (SPARCS). SPARCS can be applied to high dimensional prediction problems in experimental science, medicine, finance, and engineering, as illustrated by the following. Suppose one wishes to run a sequence of experiments to learn a sparse multivariate predictor of a dependent variable $Y$ (disease prognosis for instance) based on a $p$ dimensional set of independent variables $\mathbf X=[X_1,\ldots, X_p]^T$ (assayed biomarkers). Assume that the cost of acquiring the full set of variables $\mathbf X$ increases linearly in its dimension. SPARCS breaks the data collection into two stages in order to achieve an optimal tradeoff between sampling cost and predictor performance. In the first stage we collect a few ($n$) expensive samples $\{y_i,\mathbf x_i\}_{i=1}^n$, at the full dimension $p\gg n$ of $\mathbf X$, winnowing the number of variables down to a smaller dimension $l < p$ using a type of cross-correlation or regression coefficient screening. In the second stage we collect a larger number $(t-n)$ of cheaper samples of the $l$ variables that passed the screening of the first stage. At the second stage, a low dimensional predictor is constructed by solving the standard regression problem using all $t$ samples of the selected variables. SPARCS is an adaptive online algorithm that implements false positive control on the selected variables, is well suited to small sample sizes, and is scalable to high dimensions. We establish asymptotic bounds for the Familywise Error Rate (FWER), specify high dimensional convergence rates for support recovery, and establish optimal sample allocation rules to the first and second stages.
Foundational principles for large scale inference: Illustrations through correlation mining
May 18, 2015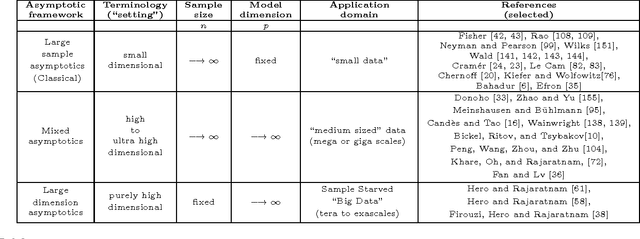


When can reliable inference be drawn in the "Big Data" context? This paper presents a framework for answering this fundamental question in the context of correlation mining, with implications for general large scale inference. In large scale data applications like genomics, connectomics, and eco-informatics the dataset is often variable-rich but sample-starved: a regime where the number $n$ of acquired samples (statistical replicates) is far fewer than the number $p$ of observed variables (genes, neurons, voxels, or chemical constituents). Much of recent work has focused on understanding the computational complexity of proposed methods for "Big Data." Sample complexity however has received relatively less attention, especially in the setting when the sample size $n$ is fixed, and the dimension $p$ grows without bound. To address this gap, we develop a unified statistical framework that explicitly quantifies the sample complexity of various inferential tasks. Sampling regimes can be divided into several categories: 1) the classical asymptotic regime where the variable dimension is fixed and the sample size goes to infinity; 2) the mixed asymptotic regime where both variable dimension and sample size go to infinity at comparable rates; 3) the purely high dimensional asymptotic regime where the variable dimension goes to infinity and the sample size is fixed. Each regime has its niche but only the latter regime applies to exa-scale data dimension. We illustrate this high dimensional framework for the problem of correlation mining, where it is the matrix of pairwise and partial correlations among the variables that are of interest. We demonstrate various regimes of correlation mining based on the unifying perspective of high dimensional learning rates and sample complexity for different structured covariance models and different inference tasks.
Optimization Methods for Sparse Pseudo-Likelihood Graphical Model Selection
Sep 12, 2014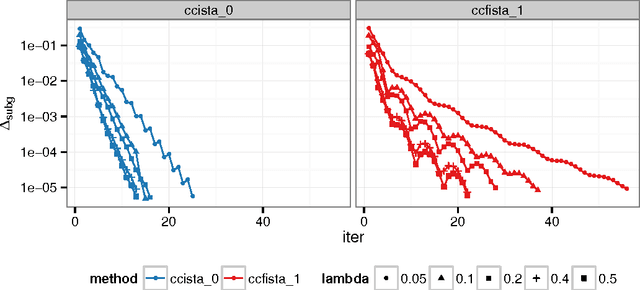

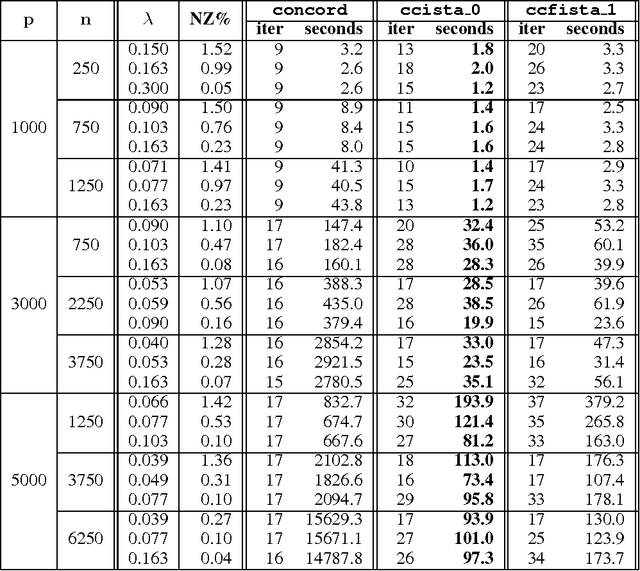
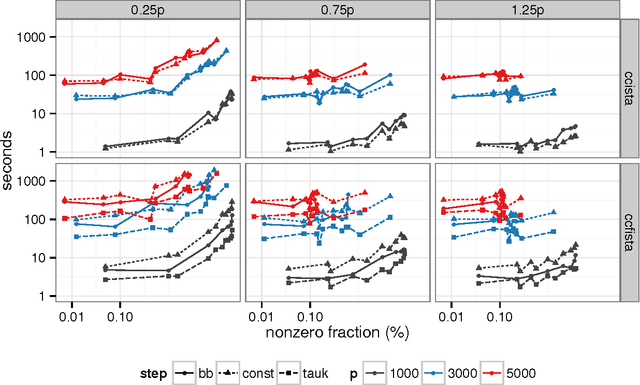
Sparse high dimensional graphical model selection is a popular topic in contemporary machine learning. To this end, various useful approaches have been proposed in the context of $\ell_1$-penalized estimation in the Gaussian framework. Though many of these inverse covariance estimation approaches are demonstrably scalable and have leveraged recent advances in convex optimization, they still depend on the Gaussian functional form. To address this gap, a convex pseudo-likelihood based partial correlation graph estimation method (CONCORD) has been recently proposed. This method uses coordinate-wise minimization of a regression based pseudo-likelihood, and has been shown to have robust model selection properties in comparison with the Gaussian approach. In direct contrast to the parallel work in the Gaussian setting however, this new convex pseudo-likelihood framework has not leveraged the extensive array of methods that have been proposed in the machine learning literature for convex optimization. In this paper, we address this crucial gap by proposing two proximal gradient methods (CONCORD-ISTA and CONCORD-FISTA) for performing $\ell_1$-regularized inverse covariance matrix estimation in the pseudo-likelihood framework. We present timing comparisons with coordinate-wise minimization and demonstrate that our approach yields tremendous payoffs for $\ell_1$-penalized partial correlation graph estimation outside the Gaussian setting, thus yielding the fastest and most scalable approach for such problems. We undertake a theoretical analysis of our approach and rigorously demonstrate convergence, and also derive rates thereof.
A convex pseudo-likelihood framework for high dimensional partial correlation estimation with convergence guarantees
Aug 14, 2014
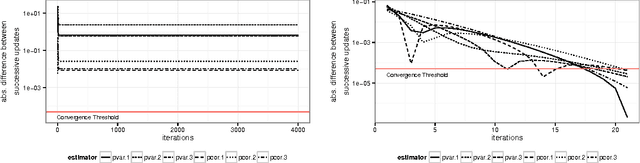

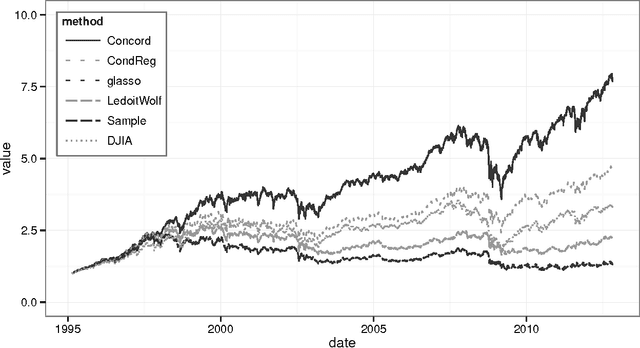
Sparse high dimensional graphical model selection is a topic of much interest in modern day statistics. A popular approach is to apply l1-penalties to either (1) parametric likelihoods, or, (2) regularized regression/pseudo-likelihoods, with the latter having the distinct advantage that they do not explicitly assume Gaussianity. As none of the popular methods proposed for solving pseudo-likelihood based objective functions have provable convergence guarantees, it is not clear if corresponding estimators exist or are even computable, or if they actually yield correct partial correlation graphs. This paper proposes a new pseudo-likelihood based graphical model selection method that aims to overcome some of the shortcomings of current methods, but at the same time retain all their respective strengths. In particular, we introduce a novel framework that leads to a convex formulation of the partial covariance regression graph problem, resulting in an objective function comprised of quadratic forms. The objective is then optimized via a coordinate-wise approach. The specific functional form of the objective function facilitates rigorous convergence analysis leading to convergence guarantees; an important property that cannot be established using standard results, when the dimension is larger than the sample size, as is often the case in high dimensional applications. These convergence guarantees ensure that estimators are well-defined under very general conditions, and are always computable. In addition, the approach yields estimators that have good large sample properties and also respect symmetry. Furthermore, application to simulated/real data, timing comparisons and numerical convergence is demonstrated. We also present a novel unifying framework that places all graphical pseudo-likelihood methods as special cases of a more general formulation, leading to important insights.
G-AMA: Sparse Gaussian graphical model estimation via alternating minimization
May 14, 2014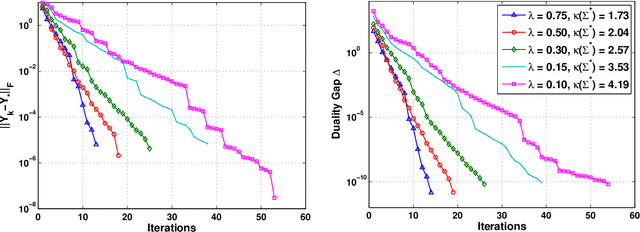
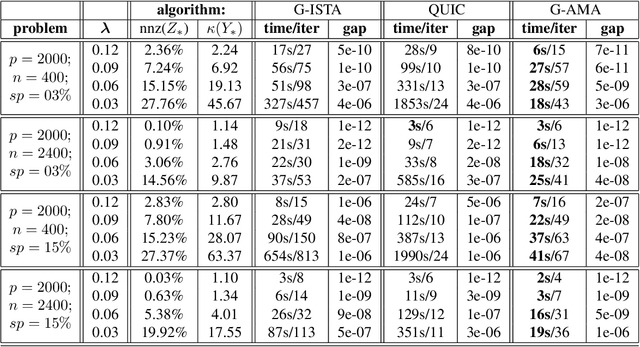
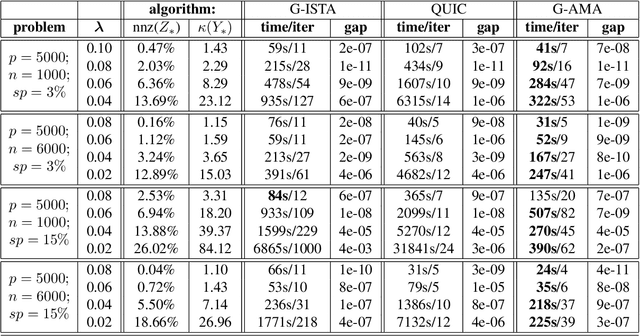
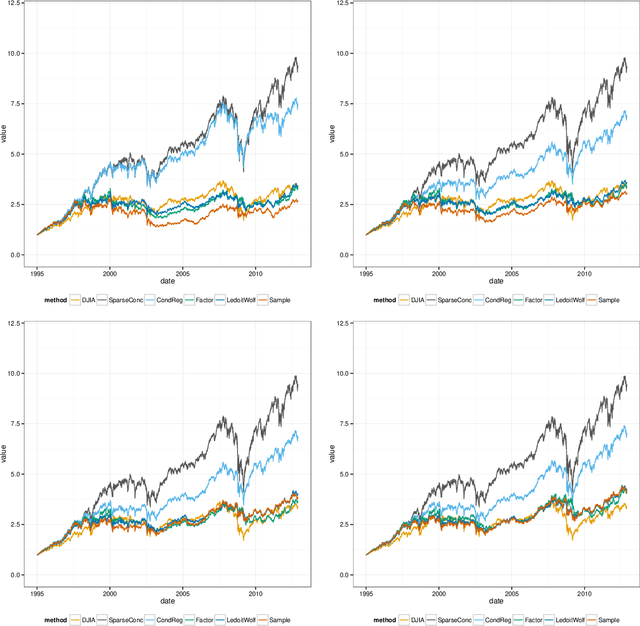
Several methods have been recently proposed for estimating sparse Gaussian graphical models using $\ell_{1}$ regularization on the inverse covariance matrix. Despite recent advances, contemporary applications require methods that are even faster in order to handle ill-conditioned high dimensional modern day datasets. In this paper, we propose a new method, G-AMA, to solve the sparse inverse covariance estimation problem using Alternating Minimization Algorithm (AMA), that effectively works as a proximal gradient algorithm on the dual problem. Our approach has several novel advantages over existing methods. First, we demonstrate that G-AMA is faster than the previous best algorithms by many orders of magnitude and is thus an ideal approach for modern high throughput applications. Second, global linear convergence of G-AMA is demonstrated rigorously, underscoring its good theoretical properties. Third, the dual algorithm operates on the covariance matrix, and thus easily facilitates incorporating additional constraints on pairwise/marginal relationships between feature pairs based on domain specific knowledge. Over and above estimating a sparse inverse covariance matrix, we also illustrate how to (1) incorporate constraints on the (bivariate) correlations and, (2) incorporate equality (equisparsity) or linear constraints between individual inverse covariance elements. Fourth, we also show that G-AMA is better adept at handling extremely ill-conditioned problems, as is often the case with real data. The methodology is demonstrated on both simulated and real datasets to illustrate its superior performance over recently proposed methods.
Duality in Graphical Models
Oct 09, 2013Graphical models have proven to be powerful tools for representing high-dimensional systems of random variables. One example of such a model is the undirected graph, in which lack of an edge represents conditional independence between two random variables given the rest. Another example is the bidirected graph, in which absence of edges encodes pairwise marginal independence. Both of these classes of graphical models have been extensively studied, and while they are considered to be dual to one another, except in a few instances this duality has not been thoroughly investigated. In this paper, we demonstrate how duality between undirected and bidirected models can be used to transport results for one class of graphical models to the dual model in a transparent manner. We proceed to apply this technique to extend previously existing results as well as to prove new ones, in three important domains. First, we discuss the pairwise and global Markov properties for undirected and bidirected models, using the pseudographoid and reverse-pseudographoid rules which are weaker conditions than the typically used intersection and composition rules. Second, we investigate these pseudographoid and reverse pseudographoid rules in the context of probability distributions, using the concept of duality in the process. Duality allows us to quickly relate them to the more familiar intersection and composition properties. Third and finally, we apply the dualization method to understand the implications of faithfulness, which in turn leads to a more general form of an existing result.
Predictive Correlation Screening: Application to Two-stage Predictor Design in High Dimension
Apr 10, 2013


We introduce a new approach to variable selection, called Predictive Correlation Screening, for predictor design. Predictive Correlation Screening (PCS) implements false positive control on the selected variables, is well suited to small sample sizes, and is scalable to high dimensions. We establish asymptotic bounds for Familywise Error Rate (FWER), and resultant mean square error of a linear predictor on the selected variables. We apply Predictive Correlation Screening to the following two-stage predictor design problem. An experimenter wants to learn a multivariate predictor of gene expressions based on successive biological samples assayed on mRNA arrays. She assays the whole genome on a few samples and from these assays she selects a small number of variables using Predictive Correlation Screening. To reduce assay cost, she subsequently assays only the selected variables on the remaining samples, to learn the predictor coefficients. We show superiority of Predictive Correlation Screening relative to LASSO and correlation learning (sometimes popularly referred to in the literature as marginal regression or simple thresholding) in terms of performance and computational complexity.
Iterative Thresholding Algorithm for Sparse Inverse Covariance Estimation
Nov 27, 2012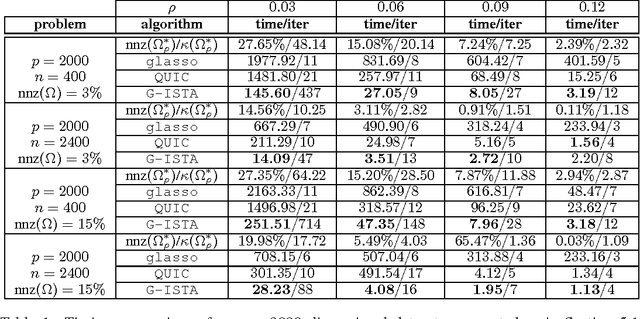
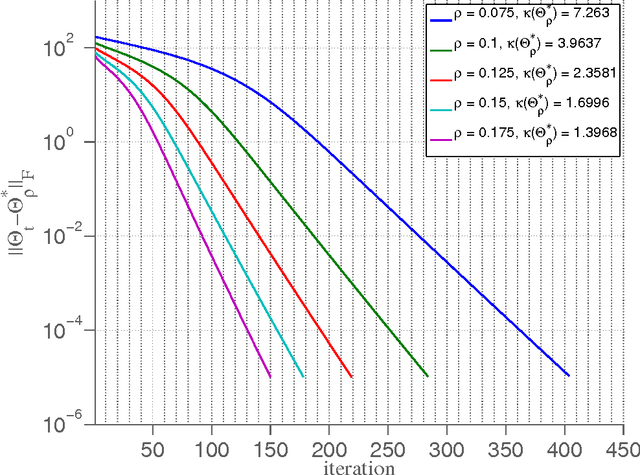
The L1-regularized maximum likelihood estimation problem has recently become a topic of great interest within the machine learning, statistics, and optimization communities as a method for producing sparse inverse covariance estimators. In this paper, a proximal gradient method (G-ISTA) for performing L1-regularized covariance matrix estimation is presented. Although numerous algorithms have been proposed for solving this problem, this simple proximal gradient method is found to have attractive theoretical and numerical properties. G-ISTA has a linear rate of convergence, resulting in an O(log e) iteration complexity to reach a tolerance of e. This paper gives eigenvalue bounds for the G-ISTA iterates, providing a closed-form linear convergence rate. The rate is shown to be closely related to the condition number of the optimal point. Numerical convergence results and timing comparisons for the proposed method are presented. G-ISTA is shown to perform very well, especially when the optimal point is well-conditioned.