 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo-stage Sampling, Prediction and Adaptive Regression via Correlation Screening (SPARCS)
Oct 02, 2016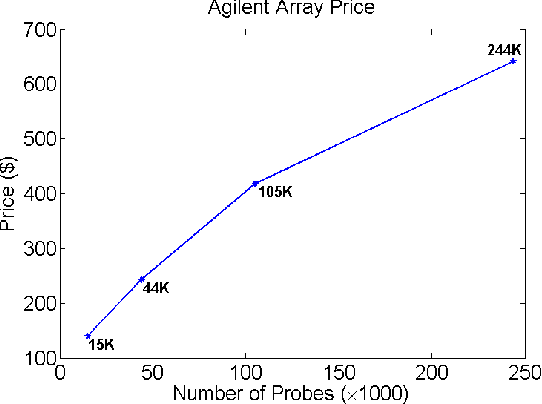

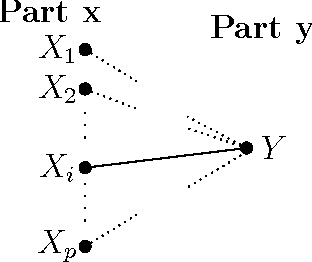
This paper proposes a general adaptive procedure for budget-limited predictor design in high dimensions called two-stage Sampling, Prediction and Adaptive Regression via Correlation Screening (SPARCS). SPARCS can be applied to high dimensional prediction problems in experimental science, medicine, finance, and engineering, as illustrated by the following. Suppose one wishes to run a sequence of experiments to learn a sparse multivariate predictor of a dependent variable $Y$ (disease prognosis for instance) based on a $p$ dimensional set of independent variables $\mathbf X=[X_1,\ldots, X_p]^T$ (assayed biomarkers). Assume that the cost of acquiring the full set of variables $\mathbf X$ increases linearly in its dimension. SPARCS breaks the data collection into two stages in order to achieve an optimal tradeoff between sampling cost and predictor performance. In the first stage we collect a few ($n$) expensive samples $\{y_i,\mathbf x_i\}_{i=1}^n$, at the full dimension $p\gg n$ of $\mathbf X$, winnowing the number of variables down to a smaller dimension $l < p$ using a type of cross-correlation or regression coefficient screening. In the second stage we collect a larger number $(t-n)$ of cheaper samples of the $l$ variables that passed the screening of the first stage. At the second stage, a low dimensional predictor is constructed by solving the standard regression problem using all $t$ samples of the selected variables. SPARCS is an adaptive online algorithm that implements false positive control on the selected variables, is well suited to small sample sizes, and is scalable to high dimensions. We establish asymptotic bounds for the Familywise Error Rate (FWER), specify high dimensional convergence rates for support recovery, and establish optimal sample allocation rules to the first and second stages.
Spectral Correlation Hub Screening of Multivariate Time Series
Apr 09, 2014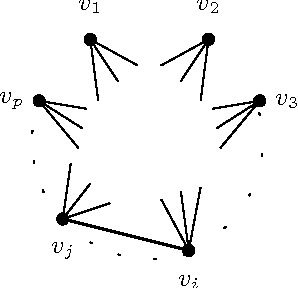



This chapter discusses correlation analysis of stationary multivariate Gaussian time series in the spectral or Fourier domain. The goal is to identify the hub time series, i.e., those that are highly correlated with a specified number of other time series. We show that Fourier components of the time series at different frequencies are asymptotically statistically independent. This property permits independent correlation analysis at each frequency, alleviating the computational and statistical challenges of high-dimensional time series. To detect correlation hubs at each frequency, an existing correlation screening method is extended to the complex numbers to accommodate complex-valued Fourier components. We characterize the number of hub discoveries at specified correlation and degree thresholds in the regime of increasing dimension and fixed sample size. The theory specifies appropriate thresholds to apply to sample correlation matrices to detect hubs and also allows statistical significance to be attributed to hub discoveries. Numerical results illustrate the accuracy of the theory and the usefulness of the proposed spectral framework.
Predictive Correlation Screening: Application to Two-stage Predictor Design in High Dimension
Apr 10, 2013

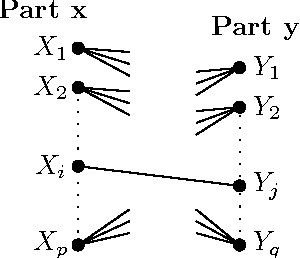

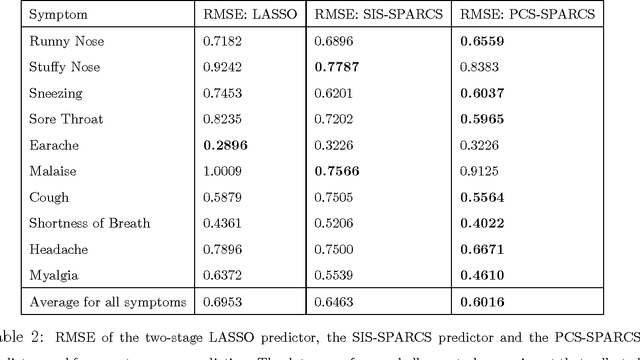
We introduce a new approach to variable selection, called Predictive Correlation Screening, for predictor design. Predictive Correlation Screening (PCS) implements false positive control on the selected variables, is well suited to small sample sizes, and is scalable to high dimensions. We establish asymptotic bounds for Familywise Error Rate (FWER), and resultant mean square error of a linear predictor on the selected variables. We apply Predictive Correlation Screening to the following two-stage predictor design problem. An experimenter wants to learn a multivariate predictor of gene expressions based on successive biological samples assayed on mRNA arrays. She assays the whole genome on a few samples and from these assays she selects a small number of variables using Predictive Correlation Screening. To reduce assay cost, she subsequently assays only the selected variables on the remaining samples, to learn the predictor coefficients. We show superiority of Predictive Correlation Screening relative to LASSO and correlation learning (sometimes popularly referred to in the literature as marginal regression or simple thresholding) in terms of performance and computational complexity.