 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniversality of high-dimensional scaling limits of stochastic gradient descent
Dec 20, 2025We consider statistical tasks in high dimensions whose loss depends on the data only through its projection into a fixed-dimensional subspace spanned by the parameter vectors and certain ground truth vectors. This includes classifying mixture distributions with cross-entropy loss with one and two-layer networks, and learning single and multi-index models with one and two-layer networks. When the data is drawn from an isotropic Gaussian mixture distribution, it is known that the evolution of a finite family of summary statistics under stochastic gradient descent converges to an autonomous ordinary differential equation (ODE), as the dimension and sample size go to $\infty$ and the step size goes to $0$ commensurately. Our main result is that these ODE limits are universal in that this limit is the same whenever the data is drawn from mixtures of arbitrary product distributions whose first two moments match the corresponding Gaussian distribution, provided the initialization and ground truth vectors are coordinate-delocalized. We complement this by proving two corresponding non-universality results. We provide a simple example where the ODE limits are non-universal if the initialization is coordinate aligned. We also show that the stochastic differential equation limits arising as fluctuations of the summary statistics around their ODE's fixed points are not universal.
Provable Benefits of Unsupervised Pre-training and Transfer Learning via Single-Index Models
Feb 24, 2025Unsupervised pre-training and transfer learning are commonly used techniques to initialize training algorithms for neural networks, particularly in settings with limited labeled data. In this paper, we study the effects of unsupervised pre-training and transfer learning on the sample complexity of high-dimensional supervised learning. Specifically, we consider the problem of training a single-layer neural network via online stochastic gradient descent. We establish that pre-training and transfer learning (under concept shift) reduce sample complexity by polynomial factors (in the dimension) under very general assumptions. We also uncover some surprising settings where pre-training grants exponential improvement over random initialization in terms of sample complexity.
Local geometry of high-dimensional mixture models: Effective spectral theory and dynamical transitions
Feb 21, 2025We study the local geometry of empirical risks in high dimensions via the spectral theory of their Hessian and information matrices. We focus on settings where the data, $(Y_\ell)_{\ell =1}^n\in \mathbb R^d$, are i.i.d. draws of a $k$-component Gaussian mixture model, and the loss depends on the projection of the data into a fixed number of vectors, namely $\mathbf{x}^\top Y$, where $\mathbf{x}\in \mathbb{R}^{d\times C}$ are the parameters, and $C$ need not equal $k$. This setting captures a broad class of problems such as classification by one and two-layer networks and regression on multi-index models. We prove exact formulas for the limits of the empirical spectral distribution and outlier eigenvalues and eigenvectors of such matrices in the proportional asymptotics limit, where the number of samples and dimension $n,d\to\infty$ and $n/d=\phi \in (0,\infty)$. These limits depend on the parameters $\mathbf{x}$ only through the summary statistic of the $(C+k)\times (C+k)$ Gram matrix of the parameters and class means, $\mathbf{G} = (\mathbf{x},\mathbf{\mu})^\top(\mathbf{x},\mathbf{\mu})$. It is known that under general conditions, when $\mathbf{x}$ is trained by stochastic gradient descent, the evolution of these same summary statistics along training converges to the solution of an autonomous system of ODEs, called the effective dynamics. This enables us to connect the spectral theory to the training dynamics. We demonstrate our general results by analyzing the effective spectrum along the effective dynamics in the case of multi-class logistic regression. In this setting, the empirical Hessian and information matrices have substantially different spectra, each with their own static and even dynamical spectral transitions.
High-dimensional SGD aligns with emerging outlier eigenspaces
Oct 04, 2023We rigorously study the joint evolution of training dynamics via stochastic gradient descent (SGD) and the spectra of empirical Hessian and gradient matrices. We prove that in two canonical classification tasks for multi-class high-dimensional mixtures and either 1 or 2-layer neural networks, the SGD trajectory rapidly aligns with emerging low-rank outlier eigenspaces of the Hessian and gradient matrices. Moreover, in multi-layer settings this alignment occurs per layer, with the final layer's outlier eigenspace evolving over the course of training, and exhibiting rank deficiency when the SGD converges to sub-optimal classifiers. This establishes some of the rich predictions that have arisen from extensive numerical studies in the last decade about the spectra of Hessian and information matrices over the course of training in overparametrized networks.
Optimality of Message-Passing Architectures for Sparse Graphs
May 17, 2023We study the node classification problem on feature-decorated graphs in the sparse setting, i.e., when the expected degree of a node is $O(1)$ in the number of nodes. Such graphs are typically known to be locally tree-like. We introduce a notion of Bayes optimality for node classification tasks, called asymptotic local Bayes optimality, and compute the optimal classifier according to this criterion for a fairly general statistical data model with arbitrary distributions of the node features and edge connectivity. The optimal classifier is implementable using a message-passing graph neural network architecture. We then compute the generalization error of this classifier and compare its performance against existing learning methods theoretically on a well-studied statistical model with naturally identifiable signal-to-noise ratios (SNRs) in the data. We find that the optimal message-passing architecture interpolates between a standard MLP in the regime of low graph signal and a typical convolution in the regime of high graph signal. Furthermore, we prove a corresponding non-asymptotic result.
Concentration of the exponential mechanism and differentially private multivariate medians
Oct 12, 2022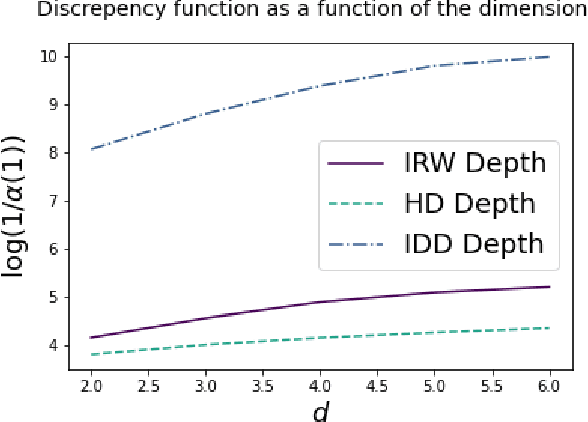

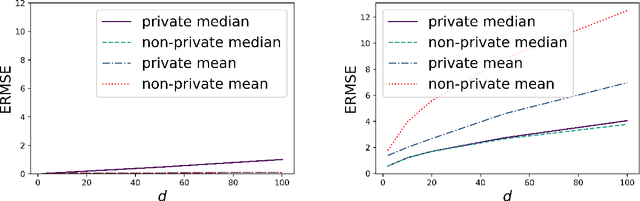
We prove concentration inequalities for the output of the exponential mechanism about the maximizer of the population objective function. This bound applies to objective functions that satisfy a mild regularity condition. To illustrate our result, we study the problem of differentially private multivariate median estimation. We present novel finite-sample performance guarantees for differentially private multivariate depth-based medians which are essentially sharp. Our results cover commonly used depth functions, such as the halfspace (or Tukey) depth, spatial depth, and the integrated dual depth. We show that under Cauchy marginals, the cost of heavy-tailed location estimation outweighs the cost of privacy. We demonstrate our results numerically using a Gaussian contamination model in dimensions up to $d = 100$, and compare them to a state-of-the-art private mean estimation algorithm.
High-dimensional limit theorems for SGD: Effective dynamics and critical scaling
Jun 08, 2022



We study the scaling limits of stochastic gradient descent (SGD) with constant step-size in the high-dimensional regime. We prove limit theorems for the trajectories of summary statistics (i.e., finite-dimensional functions) of SGD as the dimension goes to infinity. Our approach allows one to choose the summary statistics that are tracked, the initialization, and the step-size. It yields both ballistic (ODE) and diffusive (SDE) limits, with the limit depending dramatically on the former choices. Interestingly, we find a critical scaling regime for the step-size below which the effective ballistic dynamics matches gradient flow for the population loss, but at which, a new correction term appears which changes the phase diagram. About the fixed points of this effective dynamics, the corresponding diffusive limits can be quite complex and even degenerate. We demonstrate our approach on popular examples including estimation for spiked matrix and tensor models and classification via two-layer networks for binary and XOR-type Gaussian mixture models. These examples exhibit surprising phenomena including multimodal timescales to convergence as well as convergence to sub-optimal solutions with probability bounded away from zero from random (e.g., Gaussian) initializations.
Effects of Graph Convolutions in Deep Networks
Apr 20, 2022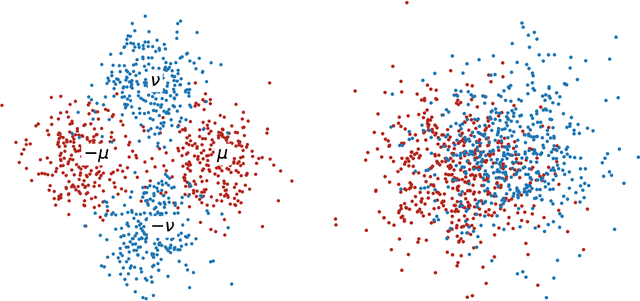
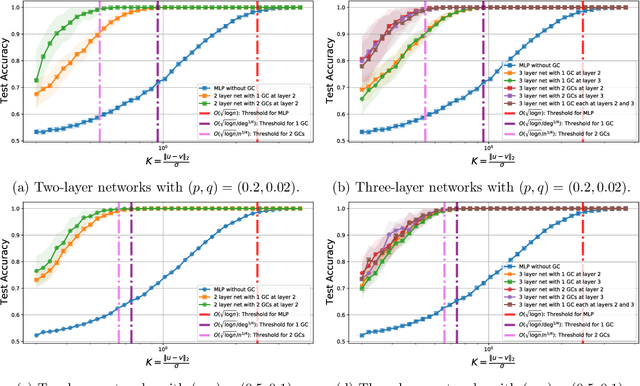
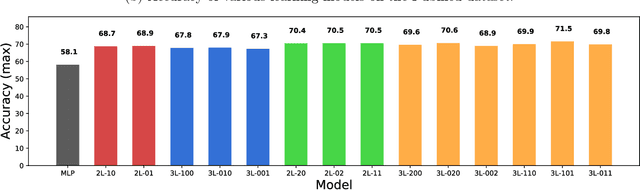
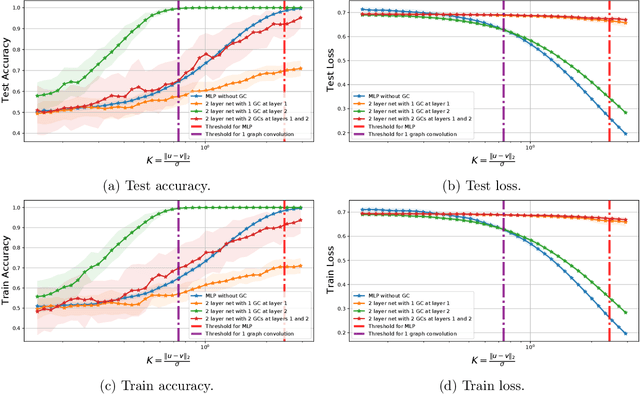
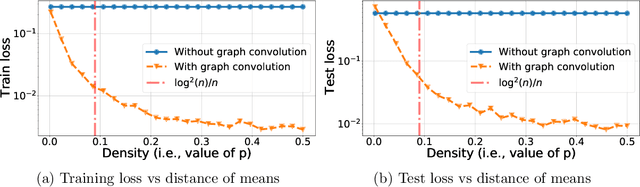
Graph Convolutional Networks (GCNs) are one of the most popular architectures that are used to solve classification problems accompanied by graphical information. We present a rigorous theoretical understanding of the effects of graph convolutions in multi-layer networks. We study these effects through the node classification problem of a non-linearly separable Gaussian mixture model coupled with a stochastic block model. First, we show that a single graph convolution expands the regime of the distance between the means where multi-layer networks can classify the data by a factor of at least $1/\sqrt[4]{\mathbb{E}{\rm deg}}$, where $\mathbb{E}{\rm deg}$ denotes the expected degree of a node. Second, we show that with a slightly stronger graph density, two graph convolutions improve this factor to at least $1/\sqrt[4]{n}$, where $n$ is the number of nodes in the graph. Finally, we provide both theoretical and empirical insights into the performance of graph convolutions placed in different combinations among the layers of a network, concluding that the performance is mutually similar for all combinations of the placement. We present extensive experiments on both synthetic and real-world data that illustrate our results.
Graph Attention Retrospective
Apr 02, 2022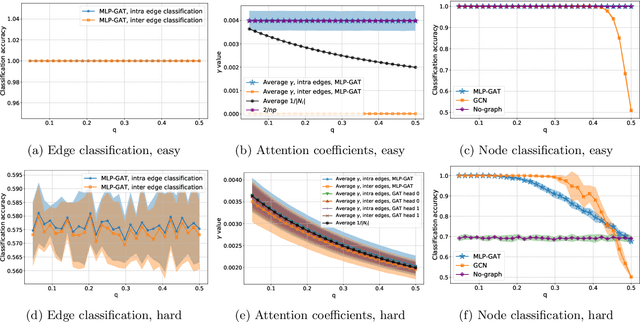
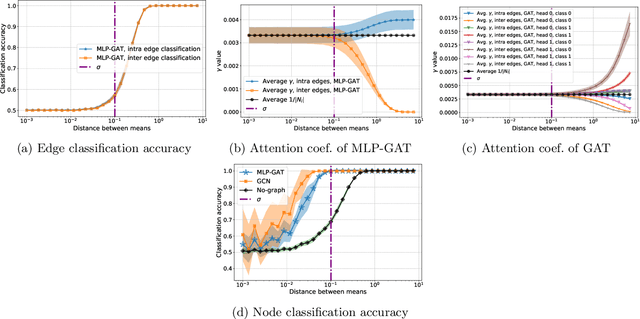
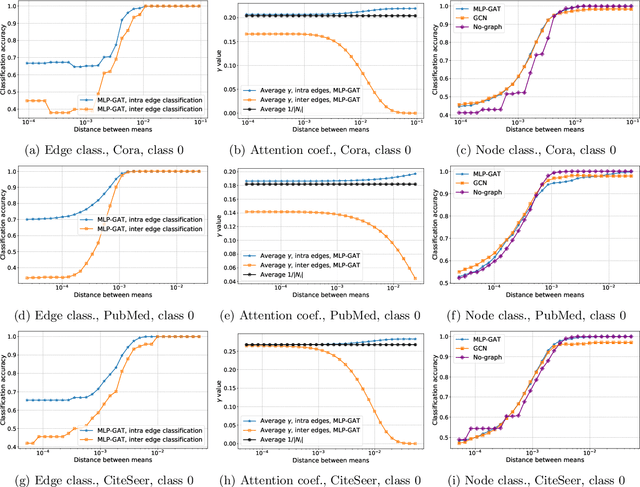
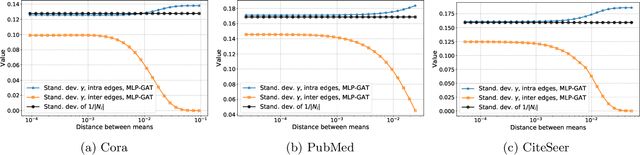
Graph-based learning is a rapidly growing sub-field of machine learning with applications in social networks, citation networks, and bioinformatics. One of the most popular type of models is graph attention networks. These models were introduced to allow a node to aggregate information from the features of neighbor nodes in a non-uniform way in contrast to simple graph convolution which does not distinguish the neighbors of a node. In this paper, we study theoretically this expected behaviour of graph attention networks. We prove multiple results on the performance of the graph attention mechanism for the problem of node classification for a contextual stochastic block model. Here the features of the nodes are obtained from a mixture of Gaussians and the edges from a stochastic block model where the features and the edges are coupled in a natural way. First, we show that in an "easy" regime, where the distance between the means of the Gaussians is large enough, graph attention maintains the weights of intra-class edges and significantly reduces the weights of the inter-class edges. As a corollary, we show that this implies perfect node classification independent of the weights of inter-class edges. However, a classical argument shows that in the "easy" regime, the graph is not needed at all to classify the data with high probability. In the "hard" regime, we show that every attention mechanism fails to distinguish intra-class from inter-class edges. We evaluate our theoretical results on synthetic and real-world data.
Graph Convolution for Semi-Supervised Classification: Improved Linear Separability and Out-of-Distribution Generalization
Feb 22, 2021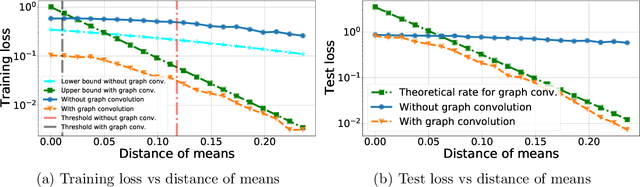
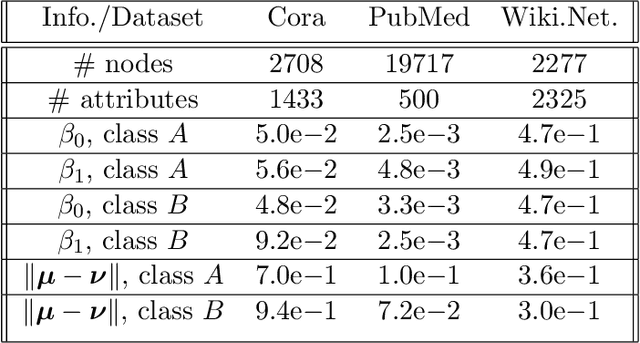
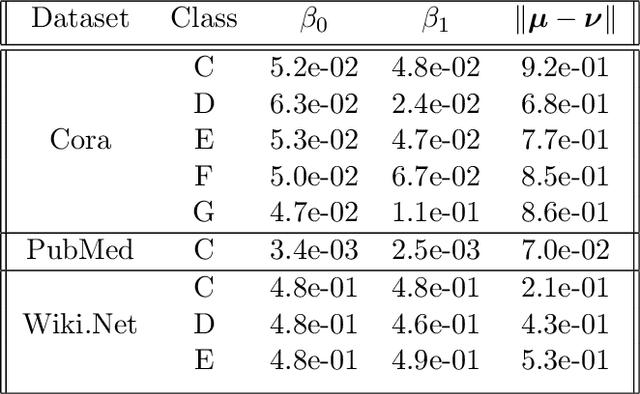
Recently there has been increased interest in semi-supervised classification in the presence of graphical information. A new class of learning models has emerged that relies, at its most basic level, on classifying the data after first applying a graph convolution. To understand the merits of this approach, we study the classification of a mixture of Gaussians, where the data corresponds to the node attributes of a stochastic block model. We show that graph convolution extends the regime in which the data is linearly separable by a factor of roughly $1/\sqrt{D}$, where $D$ is the expected degree of a node, as compared to the mixture model data on its own. Furthermore, we find that the linear classifier obtained by minimizing the cross-entropy loss after the graph convolution generalizes to out-of-distribution data where the unseen data can have different intra- and inter-class edge probabilities from the training data.