 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Optimizations for Fine-tuning Large Language Models
Jun 04, 2024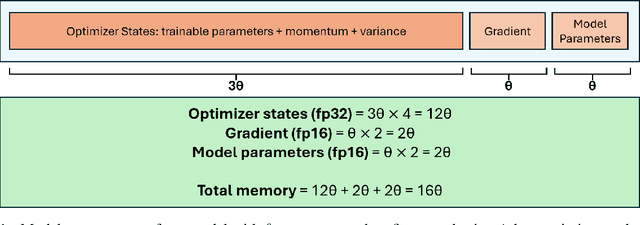
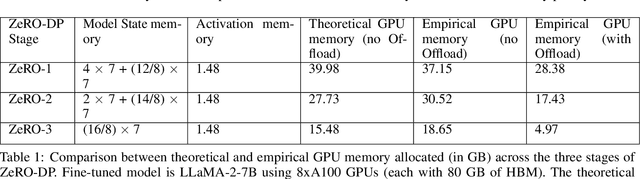
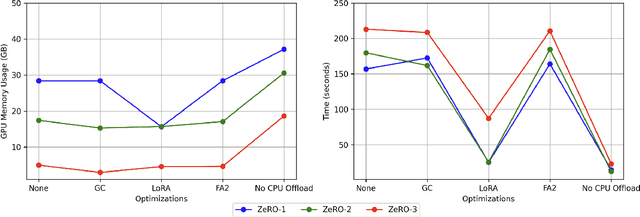

Fine-tuning large language models is a popular choice among users trying to adapt them for specific applications. However, fine-tuning these models is a demanding task because the user has to examine several factors, such as resource budget, runtime, model size and context length among others. A specific challenge is that fine-tuning is memory intensive, imposing constraints on the required hardware memory and context length of training data that can be handled. In this work, we share a detailed study on a variety of fine-tuning optimizations across different fine-tuning scenarios. In particular, we assess Gradient Checkpointing, Low Rank Adaptation, DeepSpeed's ZeRO Redundancy Optimizer and Flash Attention. With a focus on memory and runtime, we examine the impact of different optimization combinations on GPU memory usage and execution runtime during fine-tuning phase. We provide recommendation on best default optimization for balancing memory and runtime across diverse model sizes. We share effective strategies for fine-tuning very large models with tens or hundreds of billions of parameters and enabling large context lengths during fine-tuning. Furthermore, we propose the appropriate optimization mixtures for fine-tuning under GPU resource limitations.
Impact of the Antenna on the Sub-Terahertz Indoor Channel Characteristics: An Experimental Approach
Mar 07, 2024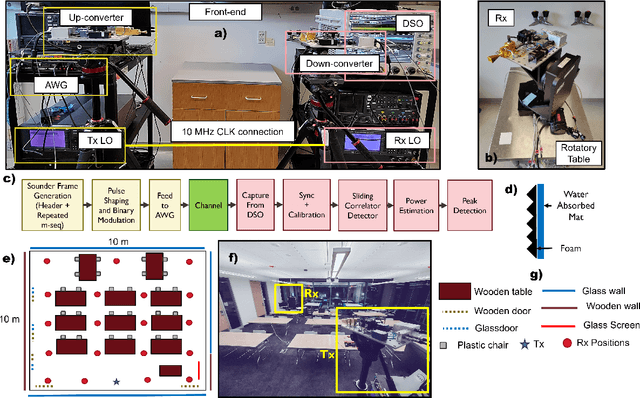
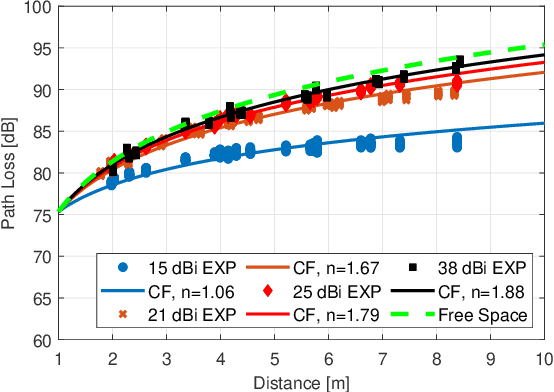
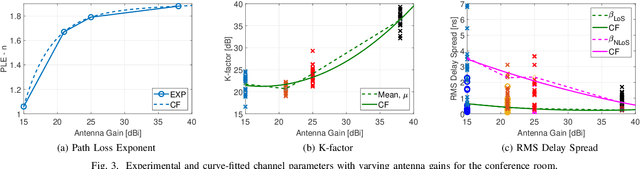
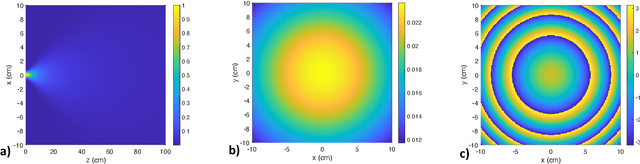
Terahertz-band (100 GHz-10 THz) communication is a promising radio technology envisioned to enable ultra-high data rate, reliable and low-latency wireless connectivity in next-generation wireless systems. However, the low transmission power of THz transmitters, the need for high gain directional antennas, and the complex interaction of THz radiation with common objects along the propagation path make crucial the understanding of the THz channel. In this paper, we conduct an extensive channel measurement campaign in an indoor setting (i.e., a conference room) through a channel sounder with 0.1 ns time resolution and 20 GHz bandwidth at 140 GHz. Particularly, the impact of different antenna directivities (and, thus, beam widths) on the channel characteristics is extensively studied. The experimentally obtained dataset is processed to develop the path loss model and, subsequently, derive key channel metrics such as the path loss exponent, delay spread, and K-factor. The results highlight the multi-faceted impact of the antenna gain on the channel and, by extension, the wireless system and, thus, show that an antenna-agnostic channel model cannot capture the propagation characteristics of the THz channel.
SymNoise: Advancing Language Model Fine-tuning with Symmetric Noise
Dec 08, 2023



In this paper, we introduce a novel fine-tuning technique for language models, which involves incorporating symmetric noise into the embedding process. This method aims to enhance the model's function by more stringently regulating its local curvature, demonstrating superior performance over the current method, NEFTune. When fine-tuning the LLaMA-2-7B model using Alpaca, standard techniques yield a 29.79% score on AlpacaEval. However, our approach, SymNoise, increases this score significantly to 69.04%, using symmetric noisy embeddings. This is a 6.7% improvement over the state-of-the-art method, NEFTune~(64.69%). Furthermore, when tested on various models and stronger baseline instruction datasets, such as Evol-Instruct, ShareGPT, OpenPlatypus, SymNoise consistently outperforms NEFTune. The current literature, including NEFTune, has underscored the importance of more in-depth research into the application of noise-based strategies in the fine-tuning of language models. Our approach, SymNoise, is another significant step towards this direction, showing notable improvement over the existing state-of-the-art method.
Coexistence and Spectrum Sharing Above 100 GHz
Oct 28, 2021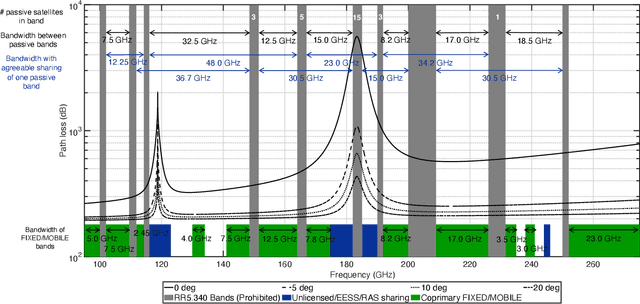
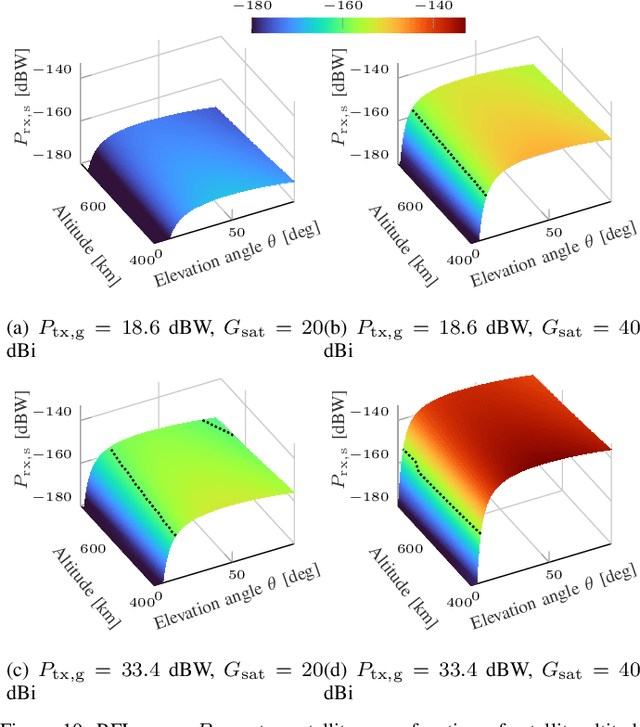
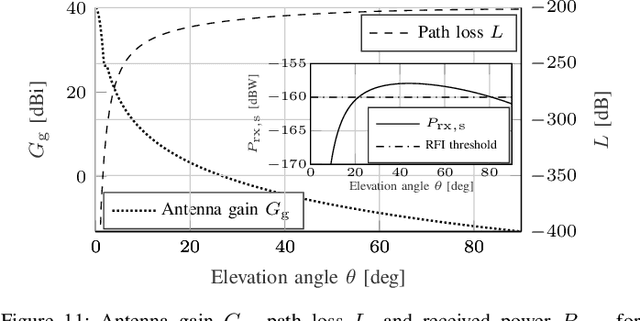
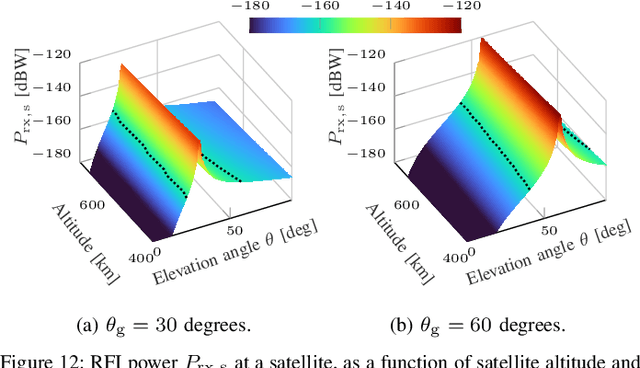
[...] This paper explores how spectrum policy and spectrum technologies can evolve to enable sharing among different stakeholders in the above 100 GHz spectrum, without introducing harmful interference or disrupting either security applications or fundamental science exploration. This portion of the spectrum presents new opportunities to design spectrum sharing schemes, based on novel antenna designs, directional ultra-high-rate communications, and active/passive user coordination. The paper provides a tutorial on current regulations above 100 GHz, and highlights how sharing is central to allowing each stakeholder to make the most out of this spectrum. It then defines - through detailed simulations based on standard International Telecommunications Union (ITU) channel and antenna models - scenarios in which active users may introduce harmful interference to passive sensing. Based on this evaluation, it reviews a number of promising techniques that can enable active/passive sharing above 100 GHz. The critical review and tutorial on policy and technologies of this paper have the potential to kickstart future research and regulations that promote safe coexistence between active and passive users above 100 GHz, further benefiting the development of digital technologies and scientific exploration.
Pretraining Federated Text Models for Next Word Prediction
May 12, 2020
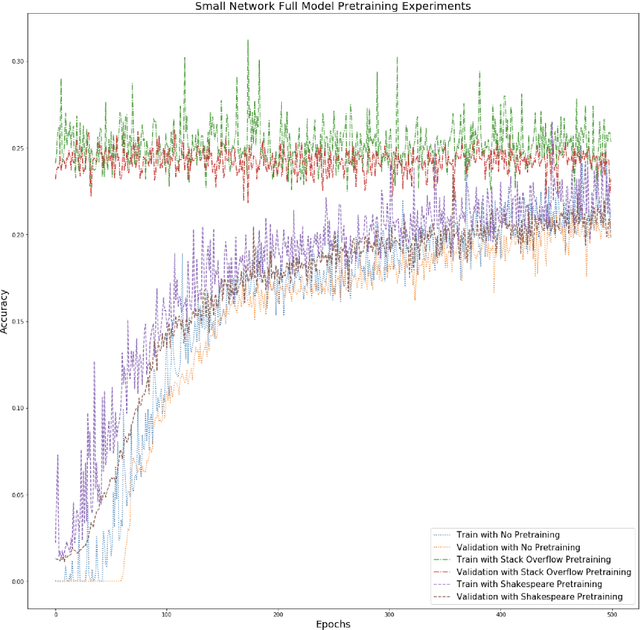
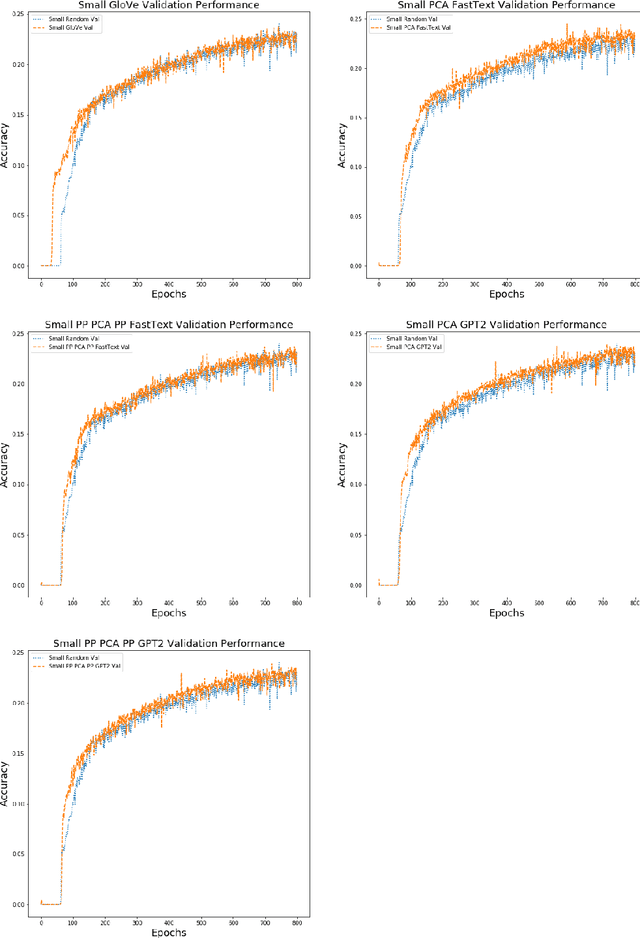
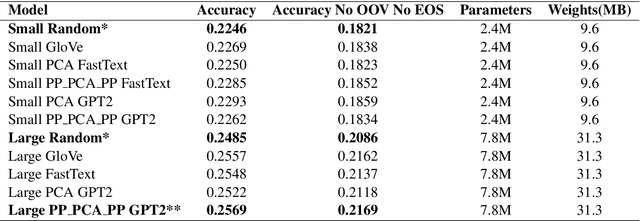
Federated learning is a decentralized approach for training models on distributed devices, by summarizing local changes and sending aggregate parameters from local models to the cloud rather than the data itself. In this research we employ the idea of transfer learning to federated training for next word prediction (NWP) and conduct a number of experiments demonstrating enhancements to current baselines for which federated NWP models have been successful. Specifically, we compare federated training baselines from randomly initialized models to various combinations of pretraining approaches including pretrained word embeddings and whole model pretraining followed by federated fine tuning for NWP on a dataset of Stack Overflow posts. We realize lift in performance using pretrained embeddings without exacerbating the number of required training rounds or memory footprint. We also observe notable differences using centrally pretrained networks, especially depending on the datasets used. Our research offers effective, yet inexpensive, improvements to federated NWP and paves the way for more rigorous experimentation of transfer learning techniques for federated learning.
Benchmarking in Manipulation Research: The YCB Object and Model Set and Benchmarking Protocols
Feb 10, 2015

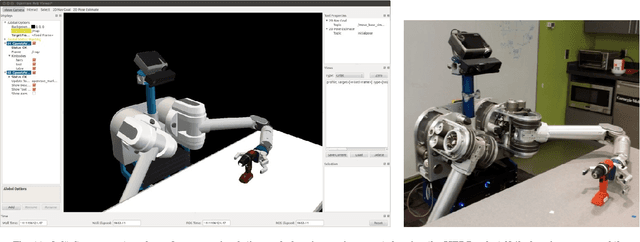

In this paper we present the Yale-CMU-Berkeley (YCB) Object and Model set, intended to be used to facilitate benchmarking in robotic manipulation, prosthetic design and rehabilitation research. The objects in the set are designed to cover a wide range of aspects of the manipulation problem; it includes objects of daily life with different shapes, sizes, textures, weight and rigidity, as well as some widely used manipulation tests. The associated database provides high-resolution RGBD scans, physical properties, and geometric models of the objects for easy incorporation into manipulation and planning software platforms. In addition to describing the objects and models in the set along with how they were chosen and derived, we provide a framework and a number of example task protocols, laying out how the set can be used to quantitatively evaluate a range of manipulation approaches including planning, learning, mechanical design, control, and many others. A comprehensive literature survey on existing benchmarks and object datasets is also presented and their scope and limitations are discussed. The set will be freely distributed to research groups worldwide at a series of tutorials at robotics conferences, and will be otherwise available at a reasonable purchase cost. It is our hope that the ready availability of this set along with the ground laid in terms of protocol templates will enable the community of manipulation researchers to more easily compare approaches as well as continually evolve benchmarking tests as the field matures.
* Submitted to Robotics and Automation Magazine (RAM) Special Issue on Replicable and Measurable Robotics Research. 35 Pages