 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAgentNLQ: A General-Purpose Agent for Natural Language to SQL
May 18, 2026Natural language to SQL (NL2SQL) conversion is an important problem for researchers and enterprises due to the ubiquitous importance of relational databases in broad-ranging practical problems. Despite the rapid advancements in the capabilities of LLMs, NL2SQL has not reached parity in accuracy with human expert SQL writers, hence needing additional improvements in NL2SQL algorithms. This study presents a new multi-agent method for NL2SQL that achieves 78.1% semantic accuracy on the BIg Bench for LaRge-scale Database (BIRD) benchmark. Our method leverages a semantically enriched representation of user-provided schema, adds user-provided business rules, and produces accurate SQL queries. The main contributions of this study are (a) We designed an optimized new orchestrator in a multi-agent solution that uses LLMs to plan, orchestrate, reflect, and self-correct to generate accurate SQL queries, (b) We developed an advanced schema enrichment method that creates context-aware metadata to improve accuracy, and (c) We demonstrated the accuracy and generalizability of the method across different domains and datasets by evaluating it on the BIRD-SQL benchmark.
Knowledge Distillation Using Frontier Open-source LLMs: Generalizability and the Role of Synthetic Data
Oct 24, 2024
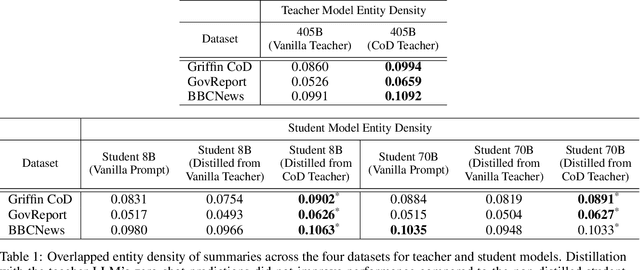
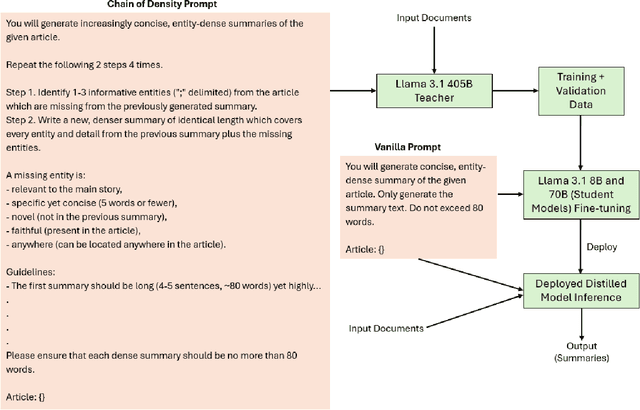

Leading open-source large language models (LLMs) such as Llama-3.1-Instruct-405B are extremely capable at generating text, answering questions, and solving a variety of natural language understanding tasks. However, they incur higher inference cost and latency compared to smaller LLMs. Knowledge distillation provides a way to use outputs from these large, capable teacher models to train smaller student models which can be used for inference at lower cost and latency, while retaining comparable accuracy. We investigate the efficacy of distillation using the Llama-3.1-405B-Instruct teacher and the smaller Llama-3.1-8B-Instruct and Llama-3.1-70B-Instruct student models. Contributions of this work include (a) We evaluate the generalizability of distillation with the above Llama-3.1 teacher-student pairs across different tasks and datasets (b) We show that using synthetic data during distillation significantly improves the accuracy of 8B and 70B models, and when used with reasoning chains, even matches or surpasses the zero-shot accuracy of 405B model on some datasets (c) We empirically show that distillation enables 8B and 70B models to internalize 405B's reasoning ability by using only standard fine-tuning (without customizing any loss function). This allows cost and latency-efficient student model inference. (d) We show pitfalls in evaluation of distillation, and present task-specific evaluation, including both human and LLM-grading, and ground-truth based traditional accuracy benchmarks. This methodical study brings out the fundamental importance of synthetic data quality in knowledge distillation, and of combining multiple, task-specific ways of accuracy and quality evaluation in assessing the effectiveness of distillation.
A Study of Optimizations for Fine-tuning Large Language Models
Jun 04, 2024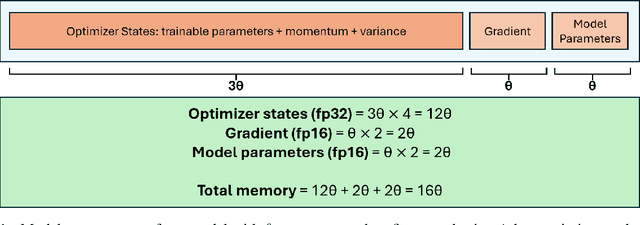
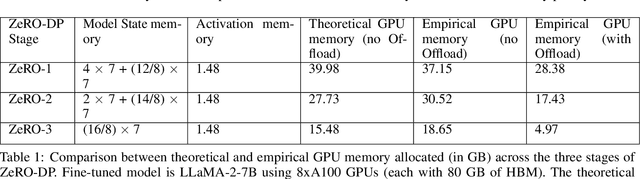
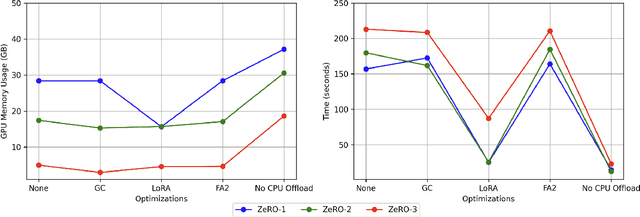

Fine-tuning large language models is a popular choice among users trying to adapt them for specific applications. However, fine-tuning these models is a demanding task because the user has to examine several factors, such as resource budget, runtime, model size and context length among others. A specific challenge is that fine-tuning is memory intensive, imposing constraints on the required hardware memory and context length of training data that can be handled. In this work, we share a detailed study on a variety of fine-tuning optimizations across different fine-tuning scenarios. In particular, we assess Gradient Checkpointing, Low Rank Adaptation, DeepSpeed's ZeRO Redundancy Optimizer and Flash Attention. With a focus on memory and runtime, we examine the impact of different optimization combinations on GPU memory usage and execution runtime during fine-tuning phase. We provide recommendation on best default optimization for balancing memory and runtime across diverse model sizes. We share effective strategies for fine-tuning very large models with tens or hundreds of billions of parameters and enabling large context lengths during fine-tuning. Furthermore, we propose the appropriate optimization mixtures for fine-tuning under GPU resource limitations.