 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation Using Frontier Open-source LLMs: Generalizability and the Role of Synthetic Data
Oct 24, 2024
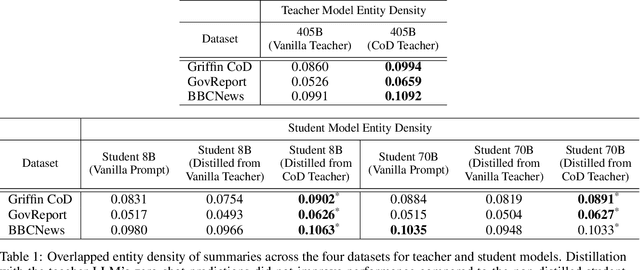
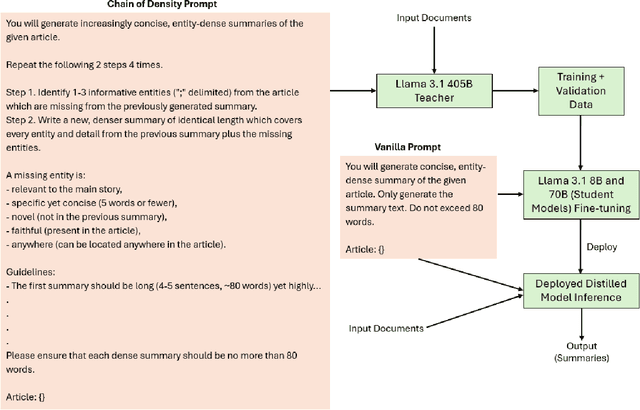

Leading open-source large language models (LLMs) such as Llama-3.1-Instruct-405B are extremely capable at generating text, answering questions, and solving a variety of natural language understanding tasks. However, they incur higher inference cost and latency compared to smaller LLMs. Knowledge distillation provides a way to use outputs from these large, capable teacher models to train smaller student models which can be used for inference at lower cost and latency, while retaining comparable accuracy. We investigate the efficacy of distillation using the Llama-3.1-405B-Instruct teacher and the smaller Llama-3.1-8B-Instruct and Llama-3.1-70B-Instruct student models. Contributions of this work include (a) We evaluate the generalizability of distillation with the above Llama-3.1 teacher-student pairs across different tasks and datasets (b) We show that using synthetic data during distillation significantly improves the accuracy of 8B and 70B models, and when used with reasoning chains, even matches or surpasses the zero-shot accuracy of 405B model on some datasets (c) We empirically show that distillation enables 8B and 70B models to internalize 405B's reasoning ability by using only standard fine-tuning (without customizing any loss function). This allows cost and latency-efficient student model inference. (d) We show pitfalls in evaluation of distillation, and present task-specific evaluation, including both human and LLM-grading, and ground-truth based traditional accuracy benchmarks. This methodical study brings out the fundamental importance of synthetic data quality in knowledge distillation, and of combining multiple, task-specific ways of accuracy and quality evaluation in assessing the effectiveness of distillation.
Injecting New Knowledge into Large Language Models via Supervised Fine-Tuning
Apr 02, 2024

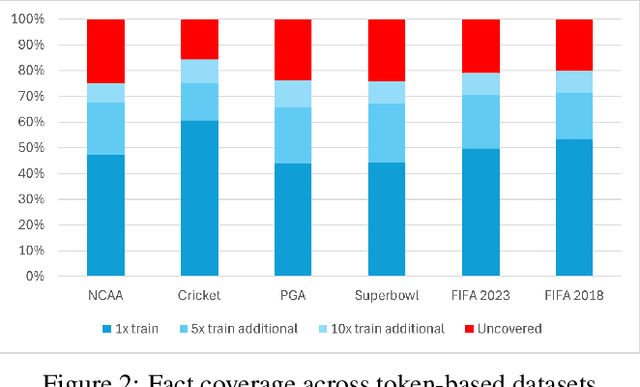

In recent years, Large Language Models (LLMs) have shown remarkable performance in generating human-like text, proving to be a valuable asset across various applications. However, adapting these models to incorporate new, out-of-domain knowledge remains a challenge, particularly for facts and events that occur after the model's knowledge cutoff date. This paper investigates the effectiveness of Supervised Fine-Tuning (SFT) as a method for knowledge injection in LLMs, specifically focusing on the domain of recent sporting events. We compare different dataset generation strategies -- token-based and fact-based scaling -- to create training data that helps the model learn new information. Our experiments on GPT-4 demonstrate that while token-based scaling can lead to improvements in Q&A accuracy, it may not provide uniform coverage of new knowledge. Fact-based scaling, on the other hand, offers a more systematic approach to ensure even coverage across all facts. We present a novel dataset generation process that leads to more effective knowledge ingestion through SFT, and our results show considerable performance improvements in Q&A tasks related to out-of-domain knowledge. This study contributes to the understanding of domain adaptation for LLMs and highlights the potential of SFT in enhancing the factuality of LLM responses in specific knowledge domains.
Mi YouTube es Su YouTube? Analyzing the Cultures using YouTube Thumbnails of Popular Videos
Jan 27, 2020

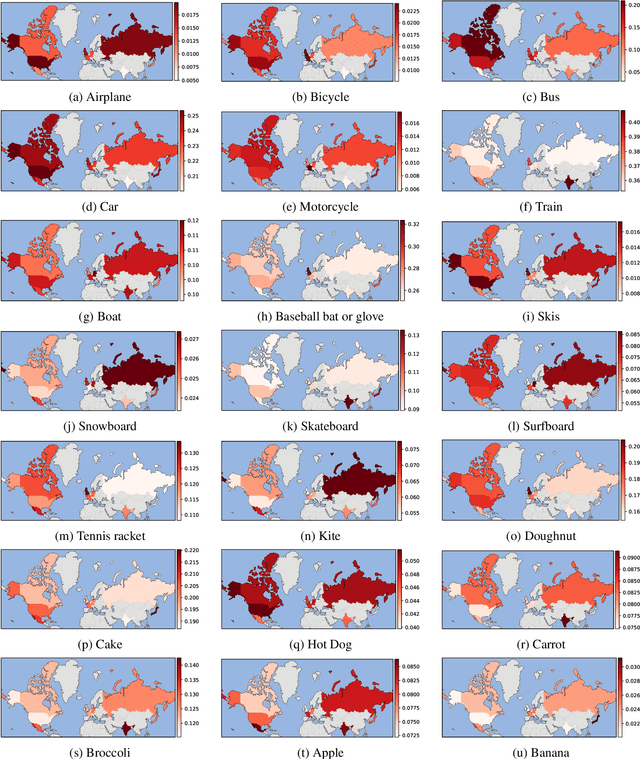

YouTube, a world-famous video sharing website, maintains a list of the top trending videos on the platform. Due to its huge amount of users, it enables researchers to understand people's preference by analyzing the trending videos. Trending videos vary from country to country. By analyzing such differences and changes, we can tell how users' preferences differ over locations. Previous work focuses on analyzing such culture preferences from videos' metadata, while the culture information hidden within the visual content has not been discovered. In this study, we explore culture preferences among countries using the thumbnails of YouTube trending videos. We first process the thumbnail images of the videos using object detectors. The collected object information is then used for various statistical analysis. In particular, we examine the data from three perspectives: geographical locations, video genres and users' reactions. Experimental results indicate that the users from similar cultures shares interests in watching similar videos on YouTube. Our study demonstrates that discovering the culture preference through the thumbnails can be an effective mechanism for video social media analysis.