 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeKnowledge Distillation Using Frontier Open-source LLMs: Generalizability and the Role of Synthetic Data
Oct 24, 2024
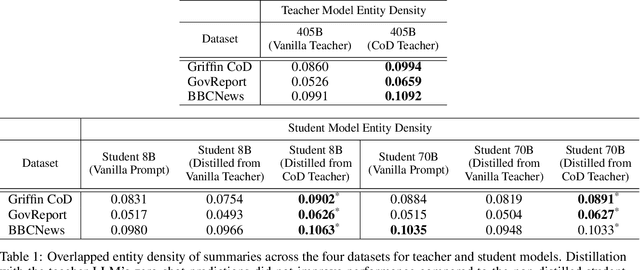
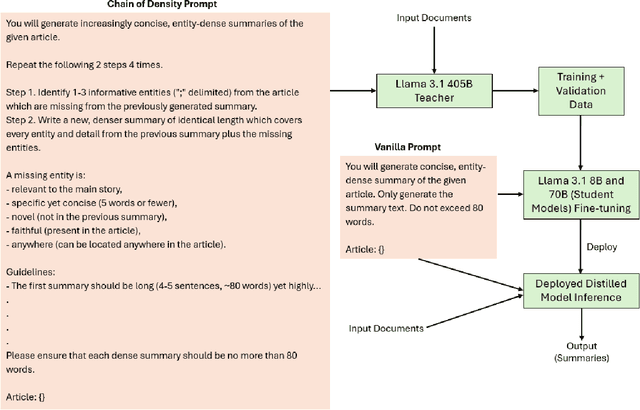

Leading open-source large language models (LLMs) such as Llama-3.1-Instruct-405B are extremely capable at generating text, answering questions, and solving a variety of natural language understanding tasks. However, they incur higher inference cost and latency compared to smaller LLMs. Knowledge distillation provides a way to use outputs from these large, capable teacher models to train smaller student models which can be used for inference at lower cost and latency, while retaining comparable accuracy. We investigate the efficacy of distillation using the Llama-3.1-405B-Instruct teacher and the smaller Llama-3.1-8B-Instruct and Llama-3.1-70B-Instruct student models. Contributions of this work include (a) We evaluate the generalizability of distillation with the above Llama-3.1 teacher-student pairs across different tasks and datasets (b) We show that using synthetic data during distillation significantly improves the accuracy of 8B and 70B models, and when used with reasoning chains, even matches or surpasses the zero-shot accuracy of 405B model on some datasets (c) We empirically show that distillation enables 8B and 70B models to internalize 405B's reasoning ability by using only standard fine-tuning (without customizing any loss function). This allows cost and latency-efficient student model inference. (d) We show pitfalls in evaluation of distillation, and present task-specific evaluation, including both human and LLM-grading, and ground-truth based traditional accuracy benchmarks. This methodical study brings out the fundamental importance of synthetic data quality in knowledge distillation, and of combining multiple, task-specific ways of accuracy and quality evaluation in assessing the effectiveness of distillation.
ChainNet: Learning on Blockchain Graphs with Topological Features
Aug 18, 2019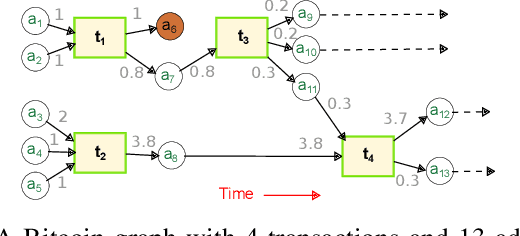
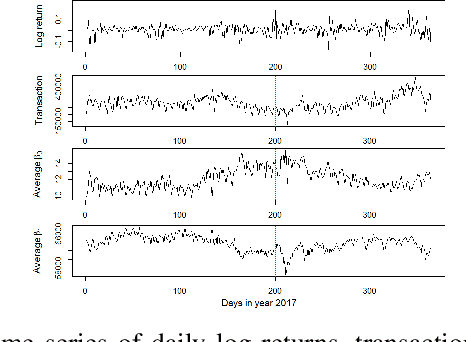
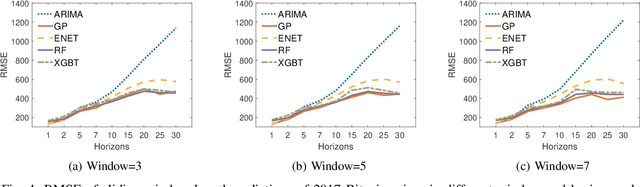
With emergence of blockchain technologies and the associated cryptocurrencies, such as Bitcoin, understanding network dynamics behind Blockchain graphs has become a rapidly evolving research direction. Unlike other financial networks, such as stock and currency trading, blockchain based cryptocurrencies have the entire transaction graph accessible to the public (i.e., all transactions can be downloaded and analyzed). A natural question is then to ask whether the dynamics of the transaction graph impacts the price of the underlying cryptocurrency. We show that standard graph features such as degree distribution of the transaction graph may not be sufficient to capture network dynamics and its potential impact on fluctuations of Bitcoin price. In contrast, the new graph associated topological features computed using the tools of persistent homology, are found to exhibit a high utility for predicting Bitcoin price dynamics. %explain higher order interactions among the nodes in Blockchain graphs and can be used to build much more accurate price prediction models. Using the proposed persistent homology-based techniques, we offer a new elegant, easily extendable and computationally light approach for graph representation learning on Blockchain.