 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Study of Optimizations for Fine-tuning Large Language Models
Jun 04, 2024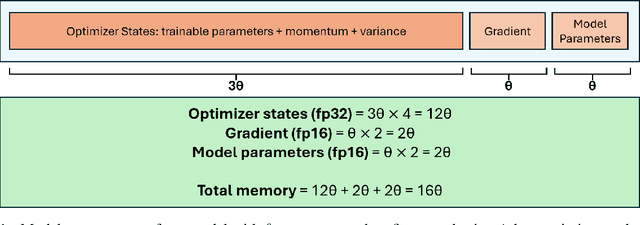
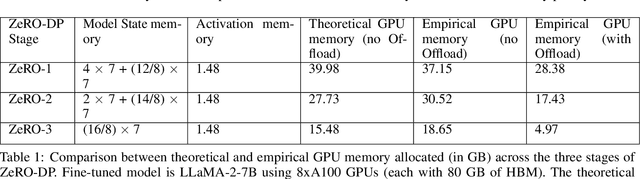
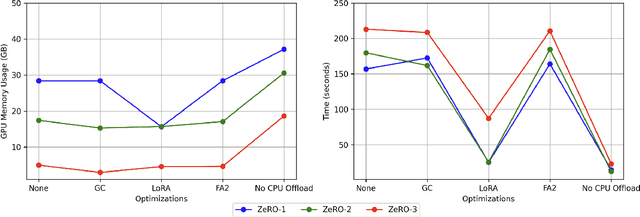

Fine-tuning large language models is a popular choice among users trying to adapt them for specific applications. However, fine-tuning these models is a demanding task because the user has to examine several factors, such as resource budget, runtime, model size and context length among others. A specific challenge is that fine-tuning is memory intensive, imposing constraints on the required hardware memory and context length of training data that can be handled. In this work, we share a detailed study on a variety of fine-tuning optimizations across different fine-tuning scenarios. In particular, we assess Gradient Checkpointing, Low Rank Adaptation, DeepSpeed's ZeRO Redundancy Optimizer and Flash Attention. With a focus on memory and runtime, we examine the impact of different optimization combinations on GPU memory usage and execution runtime during fine-tuning phase. We provide recommendation on best default optimization for balancing memory and runtime across diverse model sizes. We share effective strategies for fine-tuning very large models with tens or hundreds of billions of parameters and enabling large context lengths during fine-tuning. Furthermore, we propose the appropriate optimization mixtures for fine-tuning under GPU resource limitations.