 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePretraining Federated Text Models for Next Word Prediction
Paper and Code

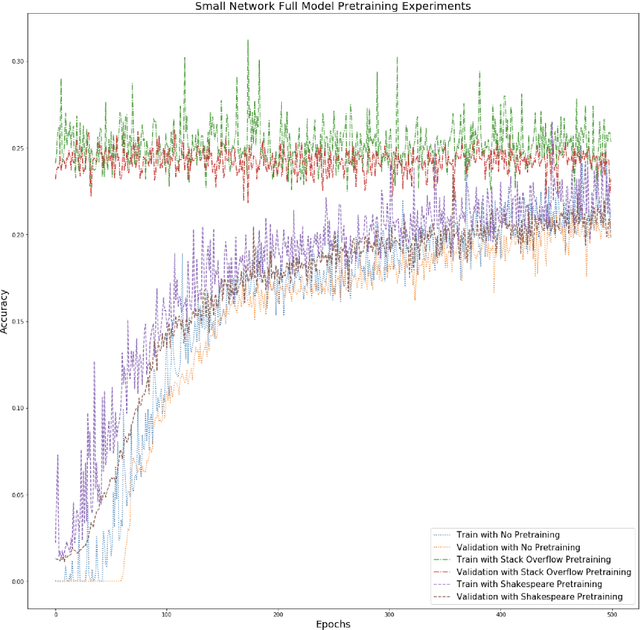
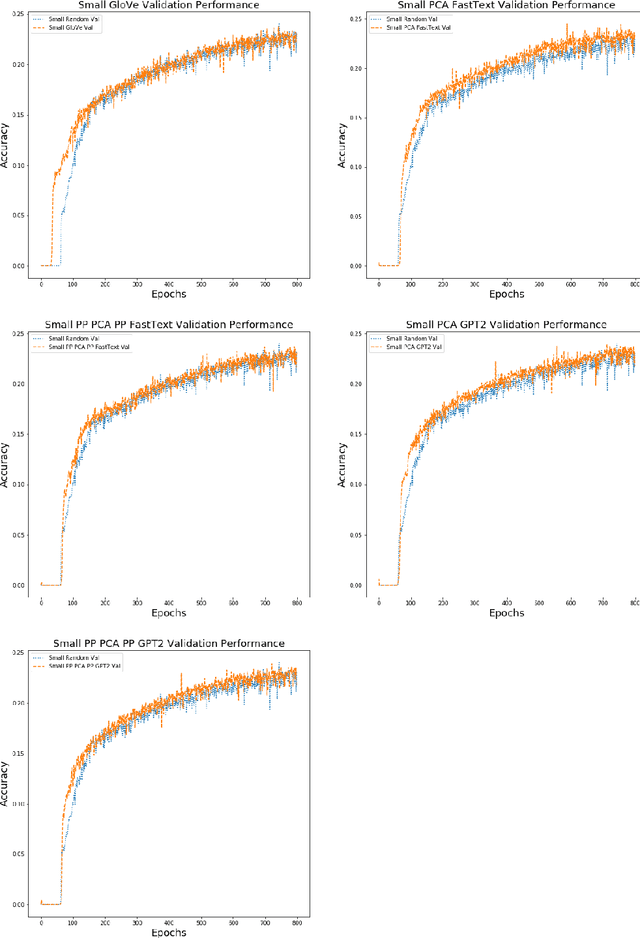
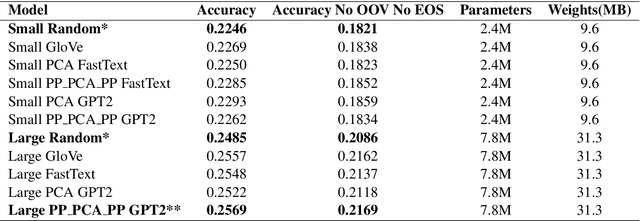
Federated learning is a decentralized approach for training models on distributed devices, by summarizing local changes and sending aggregate parameters from local models to the cloud rather than the data itself. In this research we employ the idea of transfer learning to federated training for next word prediction (NWP) and conduct a number of experiments demonstrating enhancements to current baselines for which federated NWP models have been successful. Specifically, we compare federated training baselines from randomly initialized models to various combinations of pretraining approaches including pretrained word embeddings and whole model pretraining followed by federated fine tuning for NWP on a dataset of Stack Overflow posts. We realize lift in performance using pretrained embeddings without exacerbating the number of required training rounds or memory footprint. We also observe notable differences using centrally pretrained networks, especially depending on the datasets used. Our research offers effective, yet inexpensive, improvements to federated NWP and paves the way for more rigorous experimentation of transfer learning techniques for federated learning.