 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrajectory-Based Off-Policy Deep Reinforcement Learning
May 14, 2019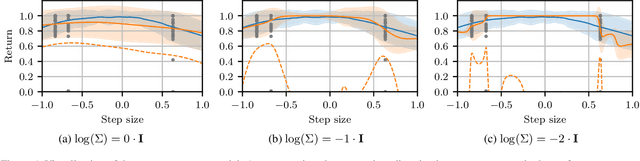

Policy gradient methods are powerful reinforcement learning algorithms and have been demonstrated to solve many complex tasks. However, these methods are also data-inefficient, afflicted with high variance gradient estimates, and frequently get stuck in local optima. This work addresses these weaknesses by combining recent improvements in the reuse of off-policy data and exploration in parameter space with deterministic behavioral policies. The resulting objective is amenable to standard neural network optimization strategies like stochastic gradient descent or stochastic gradient Hamiltonian Monte Carlo. Incorporation of previous rollouts via importance sampling greatly improves data-efficiency, whilst stochastic optimization schemes facilitate the escape from local optima. We evaluate the proposed approach on a series of continuous control benchmark tasks. The results show that the proposed algorithm is able to successfully and reliably learn solutions using fewer system interactions than standard policy gradient methods.
Meta-Learning Acquisition Functions for Bayesian Optimization
Apr 09, 2019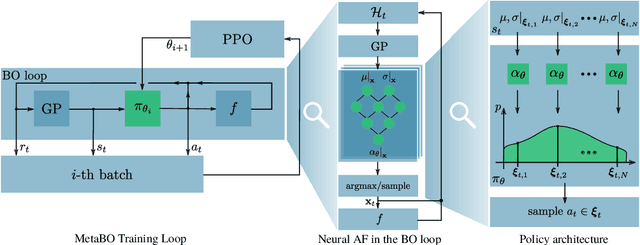
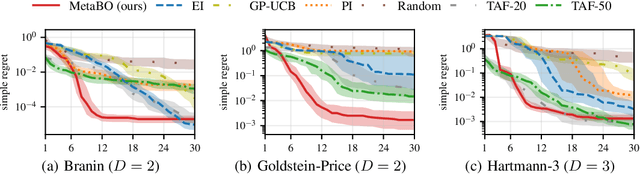

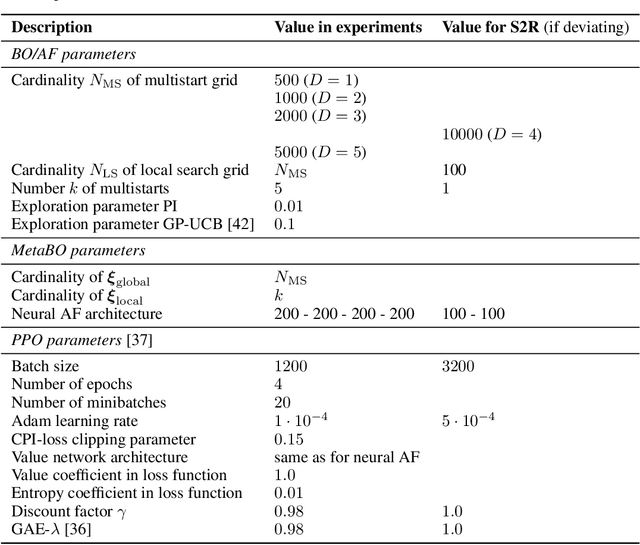
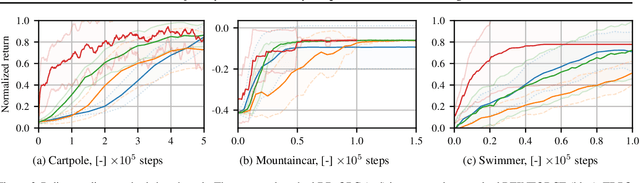
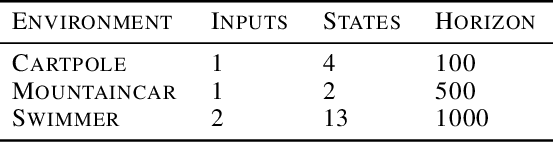
Many practical applications of machine learning require data-efficient black-box function optimization, e.g., to identify hyperparameters or process settings. However, readily available algorithms are typically designed to be universal optimizers and are, thus, often suboptimal for specific tasks. We therefore propose a method to learn optimizers which are automatically adapted to a given class of objective functions, e.g., in the context of sim-to-real applications. Instead of learning optimization from scratch, the proposed approach is firmly based within the famous Bayesian optimization framework. Only the acquisition function (AF) is replaced by a learned neural network and therefore the resulting algorithm is still able to exploit the proven generalization capabilities of Gaussian processes. We present experiments on several simulated as well as on a sim-to-real transfer task. The results show that the learned optimizers (1) consistently perform better than or on-par with known AFs on general function classes and (2) can automatically identify structural properties of a function class using cheap simulations and transfer this knowledge to adapt rapidly to real hardware tasks, thereby significantly outperforming existing problem-agnostic AFs.
Learning Gaussian Processes by Minimizing PAC-Bayesian Generalization Bounds
Oct 29, 2018
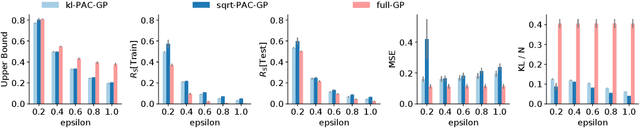
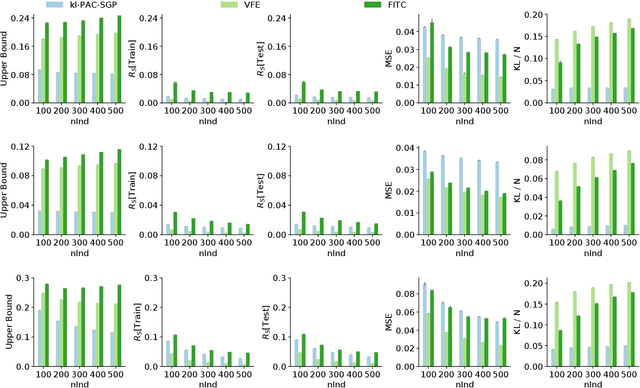
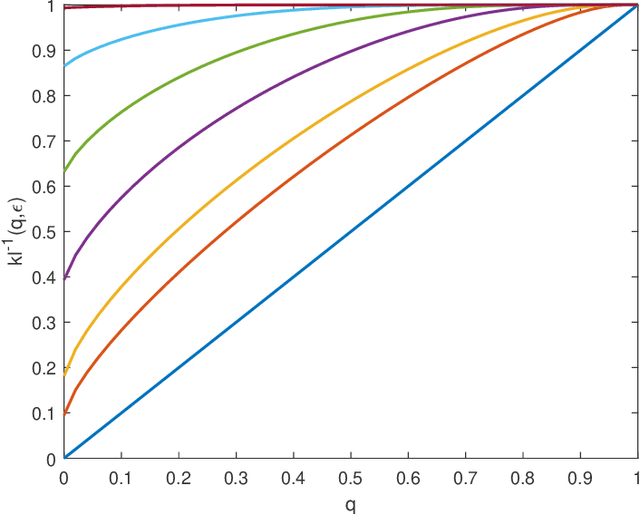
Gaussian Processes (GPs) are a generic modelling tool for supervised learning. While they have been successfully applied on large datasets, their use in safety-critical applications is hindered by the lack of good performance guarantees. To this end, we propose a method to learn GPs and their sparse approximations by directly optimizing a PAC-Bayesian bound on their generalization performance, instead of maximizing the marginal likelihood. Besides its theoretical appeal, we find in our evaluation that our learning method is robust and yields significantly better generalization guarantees than other common GP approaches on several regression benchmark datasets.
Probabilistic Recurrent State-Space Models
Feb 10, 2018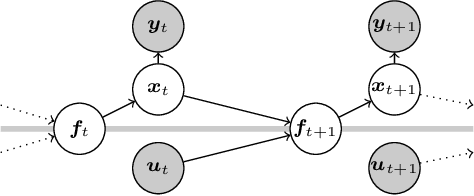
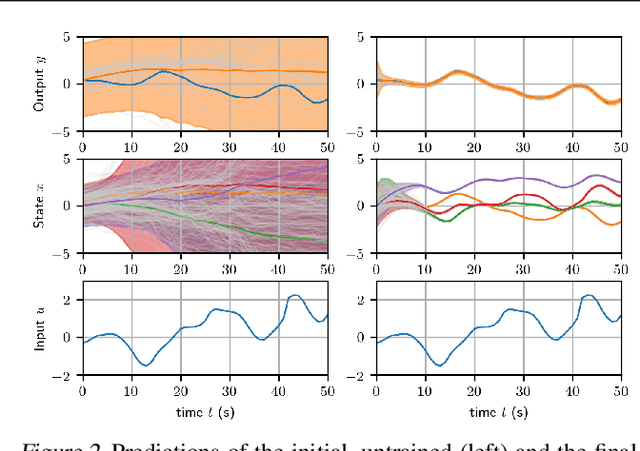

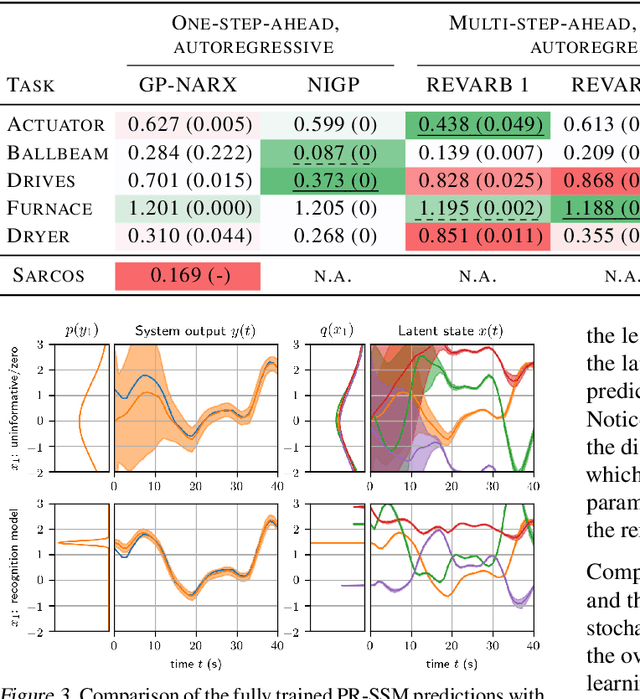
State-space models (SSMs) are a highly expressive model class for learning patterns in time series data and for system identification. Deterministic versions of SSMs (e.g. LSTMs) proved extremely successful in modeling complex time series data. Fully probabilistic SSMs, however, are often found hard to train, even for smaller problems. To overcome this limitation, we propose a novel model formulation and a scalable training algorithm based on doubly stochastic variational inference and Gaussian processes. In contrast to existing work, the proposed variational approximation allows one to fully capture the latent state temporal correlations. These correlations are the key to robust training. The effectiveness of the proposed PR-SSM is evaluated on a set of real-world benchmark datasets in comparison to state-of-the-art probabilistic model learning methods. Scalability and robustness are demonstrated on a high dimensional problem.
Model-Based Policy Search for Automatic Tuning of Multivariate PID Controllers
Mar 08, 2017
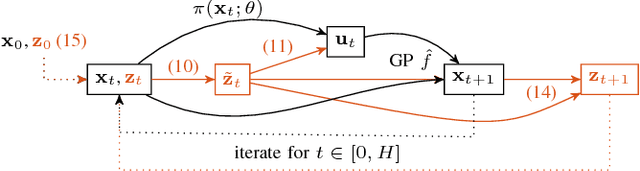
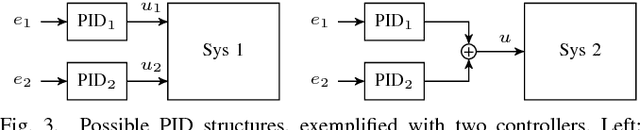
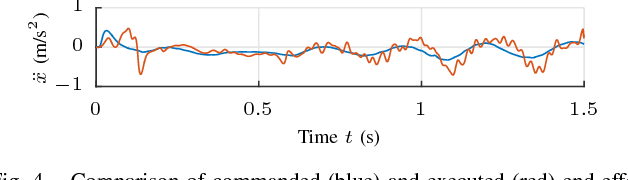
PID control architectures are widely used in industrial applications. Despite their low number of open parameters, tuning multiple, coupled PID controllers can become tedious in practice. In this paper, we extend PILCO, a model-based policy search framework, to automatically tune multivariate PID controllers purely based on data observed on an otherwise unknown system. The system's state is extended appropriately to frame the PID policy as a static state feedback policy. This renders PID tuning possible as the solution of a finite horizon optimal control problem without further a priori knowledge. The framework is applied to the task of balancing an inverted pendulum on a seven degree-of-freedom robotic arm, thereby demonstrating its capabilities of fast and data-efficient policy learning, even on complex real world problems.