 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelective Brain Damage: Measuring the Disparate Impact of Model Pruning
Nov 13, 2019



Neural network pruning techniques have demonstrated it is possible to remove the majority of weights in a network with surprisingly little degradation to test set accuracy. However, this measure of performance conceals significant differences in how different classes and images are impacted by pruning. We find that certain examples, which we term pruning identified exemplars (PIEs), and classes are systematically more impacted by the introduction of sparsity. Removing PIE images from the test-set greatly improves top-1 accuracy for both pruned and non-pruned models. These hard-to-generalize-to images tend to be mislabelled, of lower image quality, depict multiple objects or require fine-grained classification. These findings shed light on previously unknown trade-offs, and suggest that a high degree of caution should be exercised before pruning is used in sensitive domains.
iCassava 2019Fine-Grained Visual Categorization Challenge
Aug 08, 2019

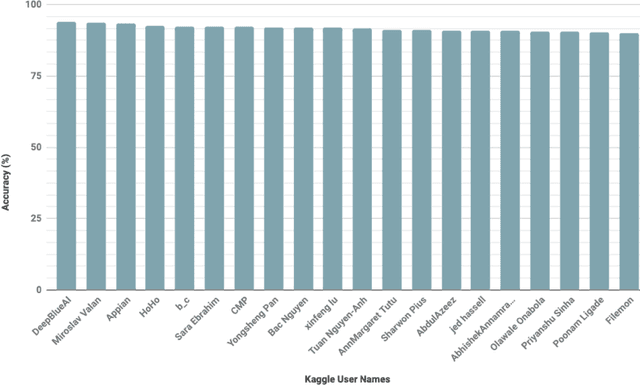
Viral diseases are major sources of poor yields for cassava, the 2nd largest provider of carbohydrates in Africa.At least 80% of small-holder farmer households in Sub-Saharan Africa grow cassava. Since many of these farmers have smart phones, they can easily obtain photos of dis-eased and healthy cassava leaves in their farms, allowing the opportunity to use computer vision techniques to monitor the disease type and severity and increase yields. How-ever, annotating these images is extremely difficult as ex-perts who are able to distinguish between highly similar dis-eases need to be employed. We provide a dataset of labeled and unlabeled cassava leaves and formulate a Kaggle challenge to encourage participants to improve the performance of their algorithms using semi-supervised approaches. This paper describes our dataset and challenge which is part of the Fine-Grained Visual Categorization workshop at CVPR2019.
Attention for Fine-Grained Categorization
Apr 11, 2015


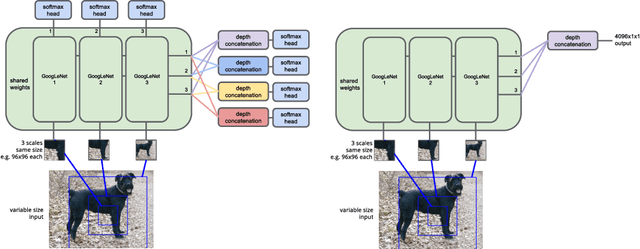
This paper presents experiments extending the work of Ba et al. (2014) on recurrent neural models for attention into less constrained visual environments, specifically fine-grained categorization on the Stanford Dogs data set. In this work we use an RNN of the same structure but substitute a more powerful visual network and perform large-scale pre-training of the visual network outside of the attention RNN. Most work in attention models to date focuses on tasks with toy or more constrained visual environments, whereas we present results for fine-grained categorization better than the state-of-the-art GoogLeNet classification model. We show that our model learns to direct high resolution attention to the most discriminative regions without any spatial supervision such as bounding boxes, and it is able to discriminate fine-grained dog breeds moderately well even when given only an initial low-resolution context image and narrow, inexpensive glimpses at faces and fur patterns. This and similar attention models have the major advantage of being trained end-to-end, as opposed to other current detection and recognition pipelines with hand-engineered components where information is lost. While our model is state-of-the-art, further work is needed to fully leverage the sequential input.
Zero-Shot Learning by Convex Combination of Semantic Embeddings
Mar 21, 2014


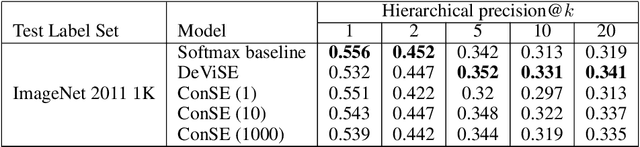
Several recent publications have proposed methods for mapping images into continuous semantic embedding spaces. In some cases the embedding space is trained jointly with the image transformation. In other cases the semantic embedding space is established by an independent natural language processing task, and then the image transformation into that space is learned in a second stage. Proponents of these image embedding systems have stressed their advantages over the traditional \nway{} classification framing of image understanding, particularly in terms of the promise for zero-shot learning -- the ability to correctly annotate images of previously unseen object categories. In this paper, we propose a simple method for constructing an image embedding system from any existing \nway{} image classifier and a semantic word embedding model, which contains the $\n$ class labels in its vocabulary. Our method maps images into the semantic embedding space via convex combination of the class label embedding vectors, and requires no additional training. We show that this simple and direct method confers many of the advantages associated with more complex image embedding schemes, and indeed outperforms state of the art methods on the ImageNet zero-shot learning task.