 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAttention for Fine-Grained Categorization
Paper and Code
Apr 11, 2015


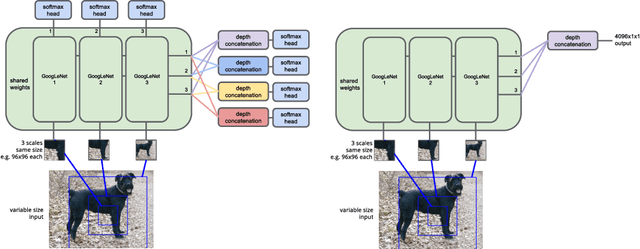
This paper presents experiments extending the work of Ba et al. (2014) on recurrent neural models for attention into less constrained visual environments, specifically fine-grained categorization on the Stanford Dogs data set. In this work we use an RNN of the same structure but substitute a more powerful visual network and perform large-scale pre-training of the visual network outside of the attention RNN. Most work in attention models to date focuses on tasks with toy or more constrained visual environments, whereas we present results for fine-grained categorization better than the state-of-the-art GoogLeNet classification model. We show that our model learns to direct high resolution attention to the most discriminative regions without any spatial supervision such as bounding boxes, and it is able to discriminate fine-grained dog breeds moderately well even when given only an initial low-resolution context image and narrow, inexpensive glimpses at faces and fur patterns. This and similar attention models have the major advantage of being trained end-to-end, as opposed to other current detection and recognition pipelines with hand-engineered components where information is lost. While our model is state-of-the-art, further work is needed to fully leverage the sequential input.