 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSunflower: A New Approach To Expanding Coverage of African Languages in Large Language Models
Oct 08, 2025There are more than 2000 living languages in Africa, most of which have been bypassed by advances in language technology. Current leading LLMs exhibit strong performance on a number of the most common languages (e.g. Swahili or Yoruba), but prioritise support for the languages with the most speakers first, resulting in piecemeal ability across disparate languages. We contend that a regionally focussed approach is more efficient, and present a case study for Uganda, a country with high linguistic diversity. We describe the development of Sunflower 14B and 32B, a pair of models based on Qwen 3 with state of the art comprehension in the majority of all Ugandan languages. These models are open source and can be used to reduce language barriers in a number of important practical applications.
How much speech data is necessary for ASR in African languages? An evaluation of data scaling in Kinyarwanda and Kikuyu
Oct 08, 2025
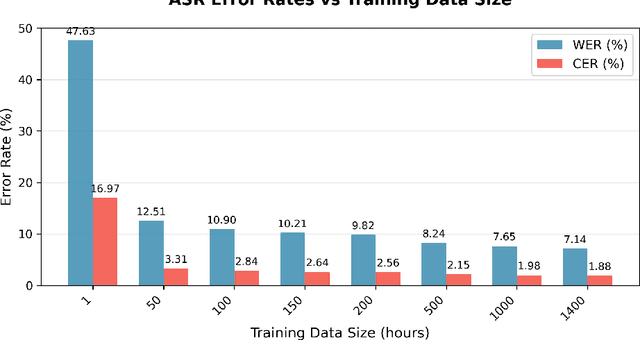

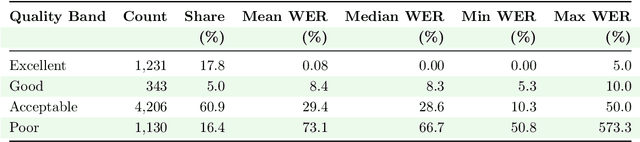
The development of Automatic Speech Recognition (ASR) systems for low-resource African languages remains challenging due to limited transcribed speech data. While recent advances in large multilingual models like OpenAI's Whisper offer promising pathways for low-resource ASR development, critical questions persist regarding practical deployment requirements. This paper addresses two fundamental concerns for practitioners: determining the minimum data volumes needed for viable performance and characterizing the primary failure modes that emerge in production systems. We evaluate Whisper's performance through comprehensive experiments on two Bantu languages: systematic data scaling analysis on Kinyarwanda using training sets from 1 to 1,400 hours, and detailed error characterization on Kikuyu using 270 hours of training data. Our scaling experiments demonstrate that practical ASR performance (WER < 13\%) becomes achievable with as little as 50 hours of training data, with substantial improvements continuing through 200 hours (WER < 10\%). Complementing these volume-focused findings, our error analysis reveals that data quality issues, particularly noisy ground truth transcriptions, account for 38.6\% of high-error cases, indicating that careful data curation is as critical as data volume for robust system performance. These results provide actionable benchmarks and deployment guidance for teams developing ASR systems across similar low-resource language contexts. We release accompanying and models see https://github.com/SunbirdAI/kinyarwanda-whisper-eval
Generating Synthetic Multispectral Satellite Imagery from Sentinel-2
Dec 05, 2020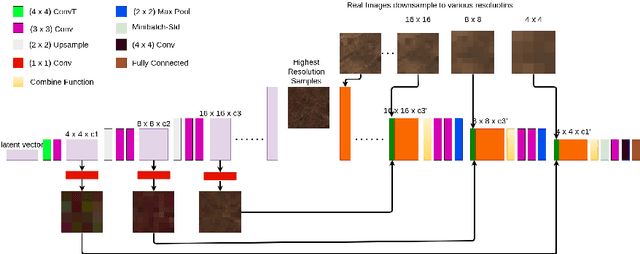
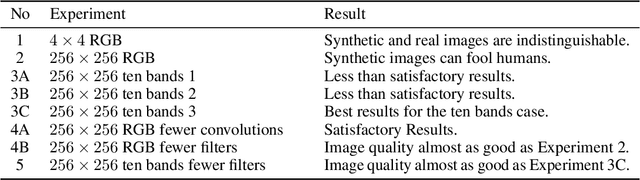

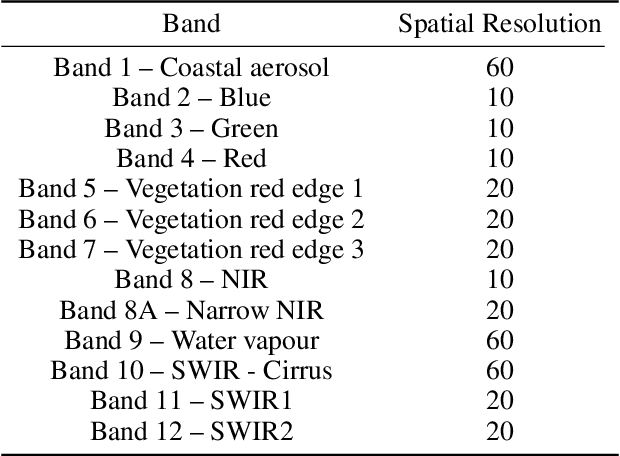
Multi-spectral satellite imagery provides valuable data at global scale for many environmental and socio-economic applications. Building supervised machine learning models based on these imagery, however, may require ground reference labels which are not available at global scale. Here, we propose a generative model to produce multi-resolution multi-spectral imagery based on Sentinel-2 data. The resulting synthetic images are indistinguishable from real ones by humans. This technique paves the road for future work to generate labeled synthetic imagery that can be used for data augmentation in data scarce regions and applications.
Semantic Segmentation of Medium-Resolution Satellite Imagery using Conditional Generative Adversarial Networks
Dec 05, 2020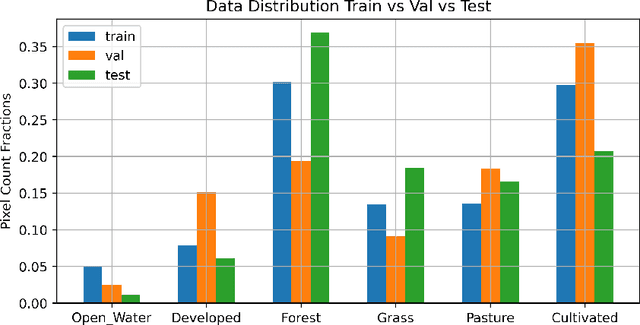
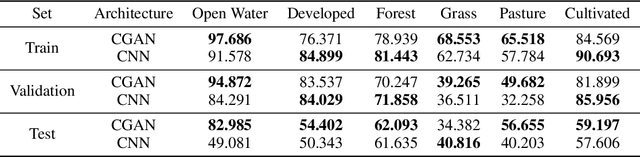


Semantic segmentation of satellite imagery is a common approach to identify patterns and detect changes around the planet. Most of the state-of-the-art semantic segmentation models are trained in a fully supervised way using Convolutional Neural Network (CNN). The generalization property of CNN is poor for satellite imagery because the data can be very diverse in terms of landscape types, image resolutions, and scarcity of labels for different geographies and seasons. Hence, the performance of CNN doesn't translate well to images from unseen regions or seasons. Inspired by Conditional Generative Adversarial Networks (CGAN) based approach of image-to-image translation for high-resolution satellite imagery, we propose a CGAN framework for land cover classification using medium-resolution Sentinel-2 imagery. We find that the CGAN model outperforms the CNN model of similar complexity by a significant margin on an unseen imbalanced test dataset.
Localization of Malaria Parasites and White Blood Cells in Thick Blood Smears
Dec 03, 2020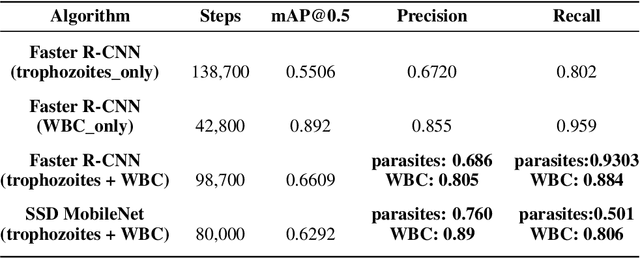
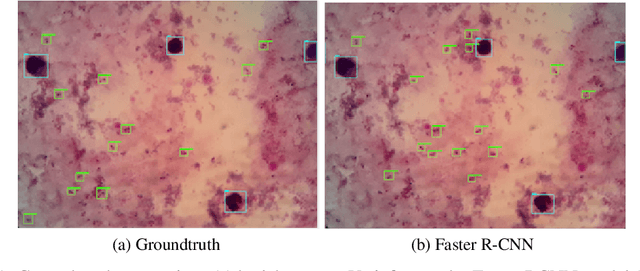
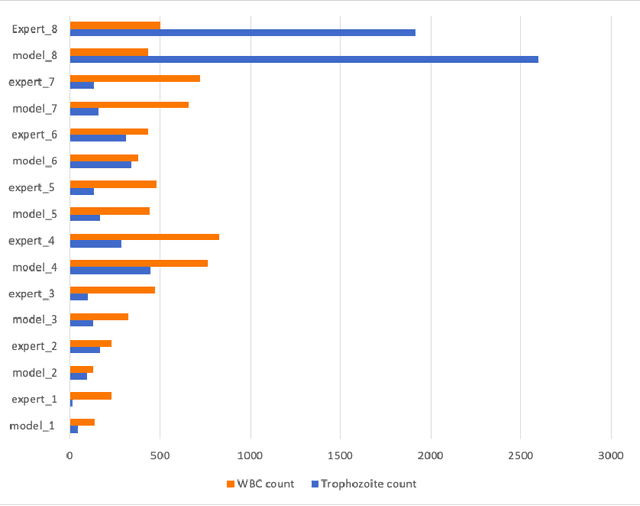
Effectively determining malaria parasitemia is a critical aspect in assisting clinicians to accurately determine the severity of the disease and provide quality treatment. Microscopy applied to thick smear blood smears is the de facto method for malaria parasitemia determination. However, manual quantification of parasitemia is time consuming, laborious and requires considerable trained expertise which is particularly inadequate in highly endemic and low resourced areas. This study presents an end-to-end approach for localisation and count of malaria parasites and white blood cells (WBCs) which aid in the effective determination of parasitemia; the quantitative content of parasites in the blood. On a dataset of slices of images of thick blood smears, we build models to analyse the obtained digital images. To improve model performance due to the limited size of the dataset, data augmentation was applied. Our preliminary results show that our deep learning approach reliably detects and returns a count of malaria parasites and WBCs with a high precision and recall. We also evaluate our system against human experts and results indicate a strong correlation between our deep learning model counts and the manual expert counts (p=0.998 for parasites, p=0.987 for WBCs). This approach could potentially be applied to support malaria parasitemia determination especially in settings that lack sufficient Microscopists.
Proceedings of the ICLR Workshop on Computer Vision for Agriculture 2020
May 17, 2020This is the proceedings of the Computer Vision for Agriculture (CV4A) Workshop that was held in conjunction with the International Conference on Learning Representations (ICLR) 2020. The Computer Vision for Agriculture (CV4A) 2020 workshop was scheduled to be held in Addis Ababa, Ethiopia, on April 26th, 2020. It was held virtually that same day due to the COVID-19 pandemic. The workshop was held in conjunction with the International Conference on Learning Representations (ICLR) 2020.
Luganda Text-to-Speech Machine
May 11, 2020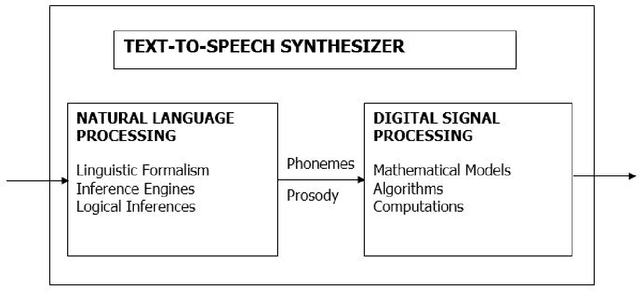
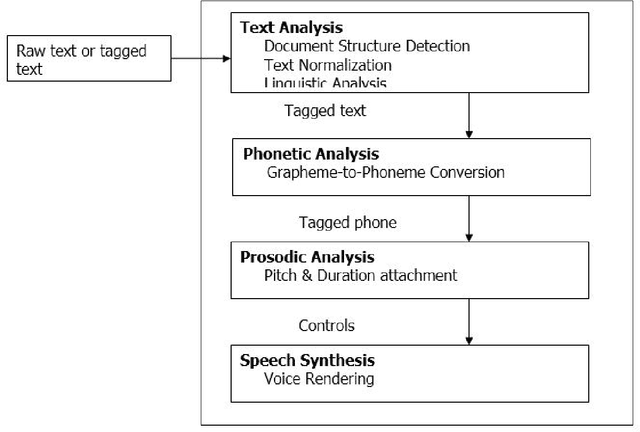
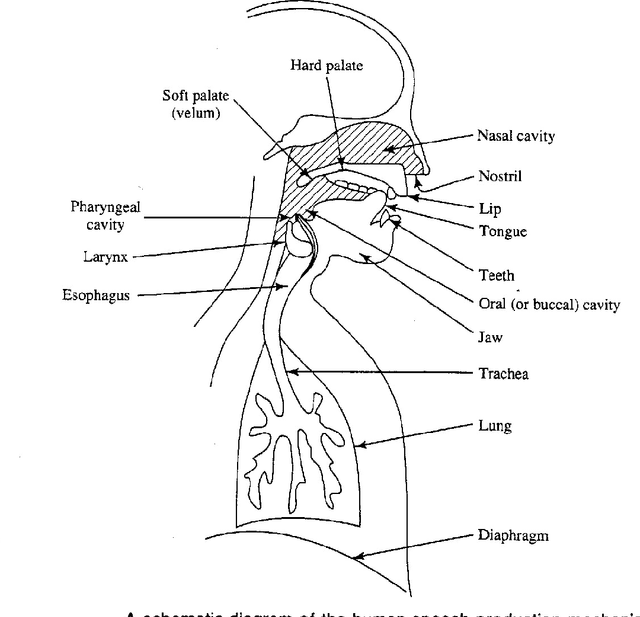
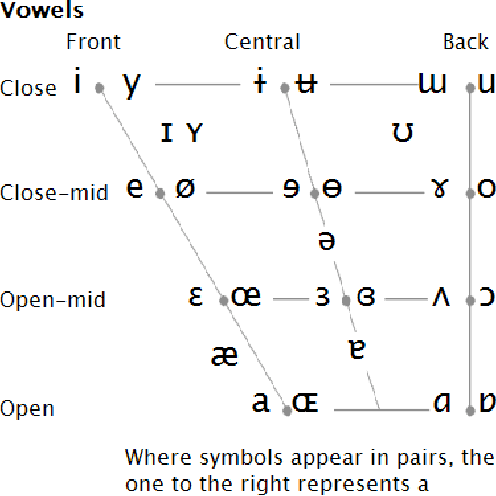
In Uganda, Luganda is the most spoken native language. It is used for communication in informal as well as formal business transactions. The development of technology startups globally related to TTS has mainly been with languages like English, French, etc. These are added in TTS engines by Google, Microsoft among others, allowing developers in these regions to innovate TTS products. Luganda is not supported because the language is not built and trained on these engines. In this study, we analyzed the Luganda language structure and constructions and then proposed and developed a Luganda TTS. The system was built and trained using locally sourced Luganda language text and audio. The engine is now able to capture text and reads it aloud. We tested the accuracy using MRT and MOS. MRT and MOS tests results are quite good with MRT having better results. The results general score was 71%. This study will enhance previous solutions to NLP gaps in Uganda, as well as provide raw data such that other research in this area can take place.
Scoring Root Necrosis in Cassava Using Semantic Segmentation
May 07, 2020


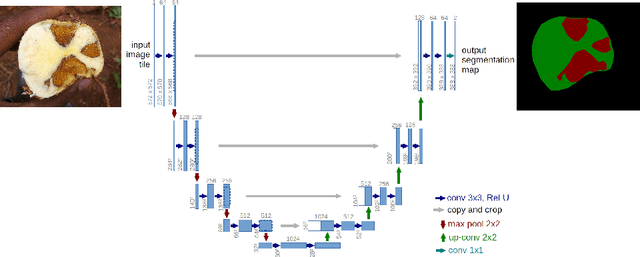
Cassava a major food crop in many parts of Africa, has majorly been affected by Cassava Brown Streak Disease (CBSD). The disease affects tuberous roots and presents symptoms that include a yellow/brown, dry, corky necrosis within the starch-bearing tissues. Cassava breeders currently depend on visual inspection to score necrosis in roots based on a qualitative score which is quite subjective. In this paper we present an approach to automate root necrosis scoring using deep convolutional neural networks with semantic segmentation. Our experiments show that the UNet model performs this task with high accuracy achieving a mean Intersection over Union (IoU) of 0.90 on the test set. This method provides a means to use a quantitative measure for necrosis scoring on root cross-sections. This is done by segmentation and classifying the necrotized and non-necrotized pixels of cassava root cross-sections without any additional feature engineering.
iCassava 2019Fine-Grained Visual Categorization Challenge
Aug 08, 2019

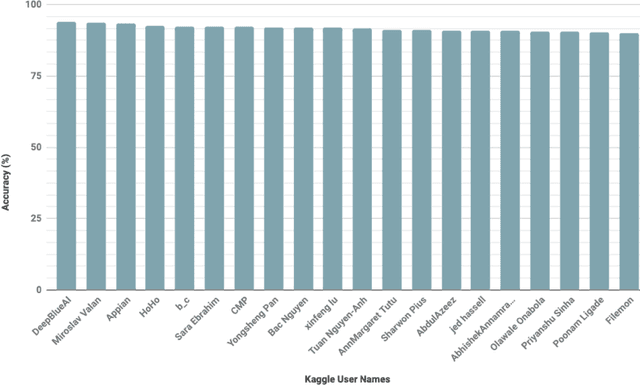
Viral diseases are major sources of poor yields for cassava, the 2nd largest provider of carbohydrates in Africa.At least 80% of small-holder farmer households in Sub-Saharan Africa grow cassava. Since many of these farmers have smart phones, they can easily obtain photos of dis-eased and healthy cassava leaves in their farms, allowing the opportunity to use computer vision techniques to monitor the disease type and severity and increase yields. How-ever, annotating these images is extremely difficult as ex-perts who are able to distinguish between highly similar dis-eases need to be employed. We provide a dataset of labeled and unlabeled cassava leaves and formulate a Kaggle challenge to encourage participants to improve the performance of their algorithms using semi-supervised approaches. This paper describes our dataset and challenge which is part of the Fine-Grained Visual Categorization workshop at CVPR2019.