 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerating Synthetic Multispectral Satellite Imagery from Sentinel-2
Dec 05, 2020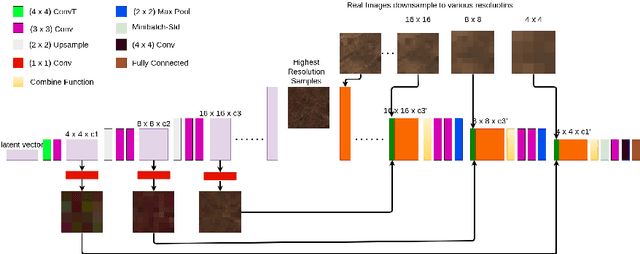
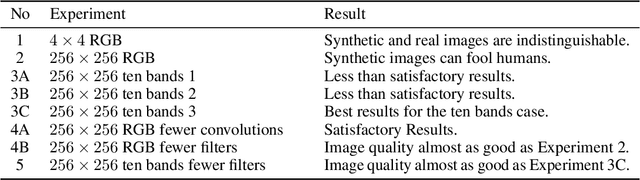

Multi-spectral satellite imagery provides valuable data at global scale for many environmental and socio-economic applications. Building supervised machine learning models based on these imagery, however, may require ground reference labels which are not available at global scale. Here, we propose a generative model to produce multi-resolution multi-spectral imagery based on Sentinel-2 data. The resulting synthetic images are indistinguishable from real ones by humans. This technique paves the road for future work to generate labeled synthetic imagery that can be used for data augmentation in data scarce regions and applications.
Semantic Segmentation of Medium-Resolution Satellite Imagery using Conditional Generative Adversarial Networks
Dec 05, 2020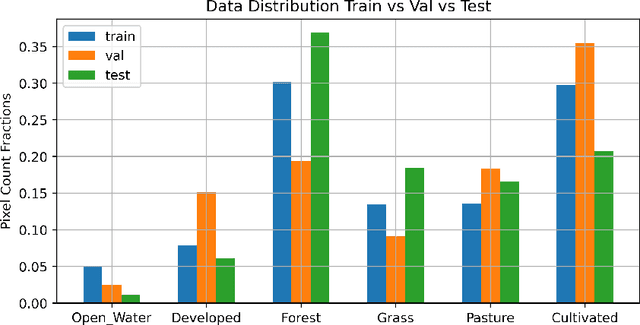
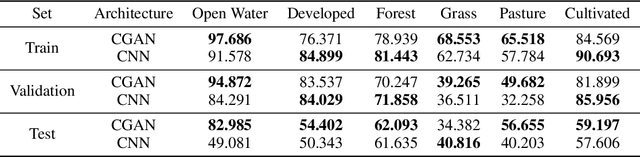


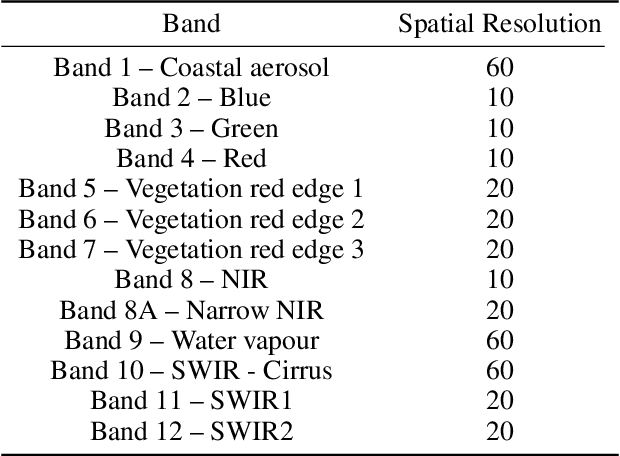
Semantic segmentation of satellite imagery is a common approach to identify patterns and detect changes around the planet. Most of the state-of-the-art semantic segmentation models are trained in a fully supervised way using Convolutional Neural Network (CNN). The generalization property of CNN is poor for satellite imagery because the data can be very diverse in terms of landscape types, image resolutions, and scarcity of labels for different geographies and seasons. Hence, the performance of CNN doesn't translate well to images from unseen regions or seasons. Inspired by Conditional Generative Adversarial Networks (CGAN) based approach of image-to-image translation for high-resolution satellite imagery, we propose a CGAN framework for land cover classification using medium-resolution Sentinel-2 imagery. We find that the CGAN model outperforms the CNN model of similar complexity by a significant margin on an unseen imbalanced test dataset.
Visual Attention for Behavioral Cloning in Autonomous Driving
Dec 05, 2018The goal of our work is to use visual attention to enhance autonomous driving performance. We present two methods of predicting visual attention maps. The first method is a supervised learning approach in which we collect eye-gaze data for the task of driving and use this to train a model for predicting the attention map. The second method is a novel unsupervised approach where we train a model to learn to predict attention as it learns to drive a car. Finally, we present a comparative study of our results and show that the supervised approach for predicting attention when incorporated performs better than other approaches.