 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGANsemble for Small and Imbalanced Data Sets: A Baseline for Synthetic Microplastics Data
Apr 10, 2024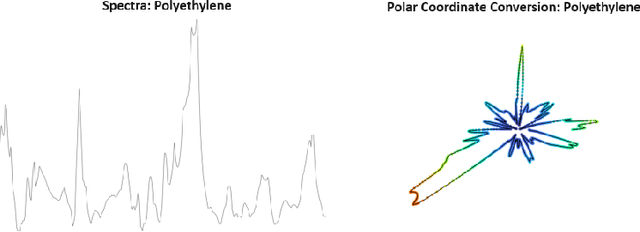
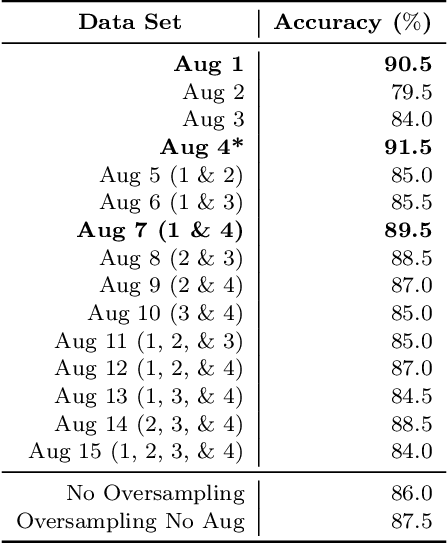
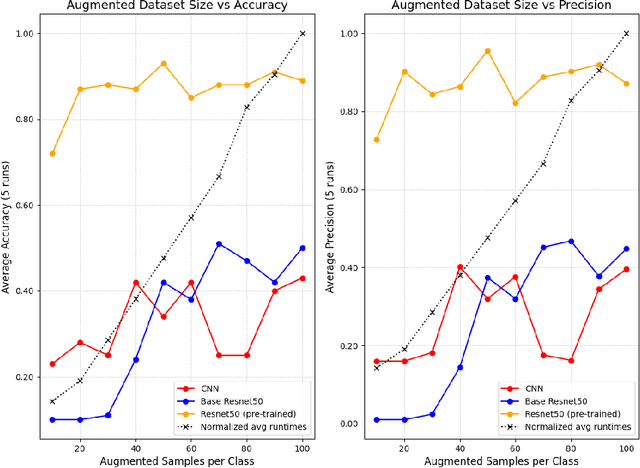
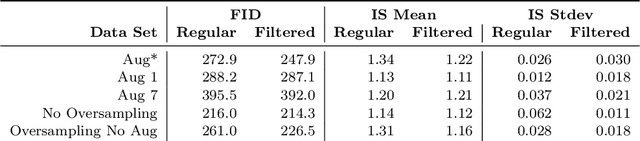
Microplastic particle ingestion or inhalation by humans is a problem of growing concern. Unfortunately, current research methods that use machine learning to understand their potential harms are obstructed by a lack of available data. Deep learning techniques in particular are challenged by such domains where only small or imbalanced data sets are available. Overcoming this challenge often involves oversampling underrepresented classes or augmenting the existing data to improve model performance. This paper proposes GANsemble: a two-module framework connecting data augmentation with conditional generative adversarial networks (cGANs) to generate class-conditioned synthetic data. First, the data chooser module automates augmentation strategy selection by searching for the best data augmentation strategy. Next, the cGAN module uses this strategy to train a cGAN for generating enhanced synthetic data. We experiment with the GANsemble framework on a small and imbalanced microplastics data set. A Microplastic-cGAN (MPcGAN) algorithm is introduced, and baselines for synthetic microplastics (SYMP) data are established in terms of Frechet Inception Distance (FID) and Inception Scores (IS). We also provide a synthetic microplastics filter (SYMP-Filter) algorithm to increase the quality of generated SYMP. Additionally, we show the best amount of oversampling with augmentation to fix class imbalance in small microplastics data sets. To our knowledge, this study is the first application of generative AI to synthetically create microplastics data.
Machine learning applications using diffusion tensor imaging of human brain: A PubMed literature review
Dec 18, 2020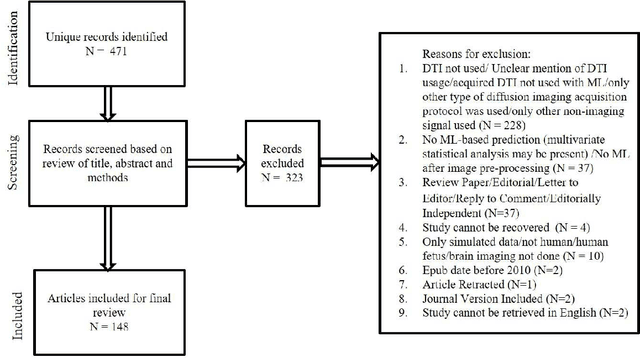
We performed a PubMed search to find 148 papers published between January 2010 and December 2019 related to human brain, Diffusion Tensor Imaging (DTI), and Machine Learning (ML). The studies focused on healthy cohorts (n = 15), mental health disorders (n = 25), tumor (n = 19), trauma (n = 5), dementia (n = 24), developmental disorders (n = 5), movement disorders (n = 9), other neurological disorders (n = 27), miscellaneous non-neurological disorders, or without stating the disease of focus (n = 7), and multiple combinations of the aforementioned categories (n = 12). Classification of patients using information from DTI stands out to be the most commonly (n = 114) performed ML application. A significant number (n = 93) of studies used support vector machines (SVM) as the preferred choice of ML model for classification. A significant portion (31/44) of publications in the recent years (2018-2019) continued to use SVM, support vector regression, and random forest which are a part of traditional ML. Though many types of applications across various health conditions (including healthy) were conducted, majority of the studies were based on small cohorts (less than 100) and did not conduct independent/external validation on test sets.
A Hierarchical Genetic Optimization of a Fuzzy Logic System for Flow Control in Micro Grids
Mar 01, 2017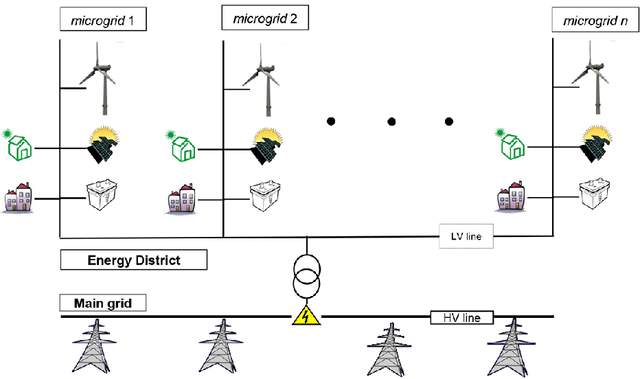
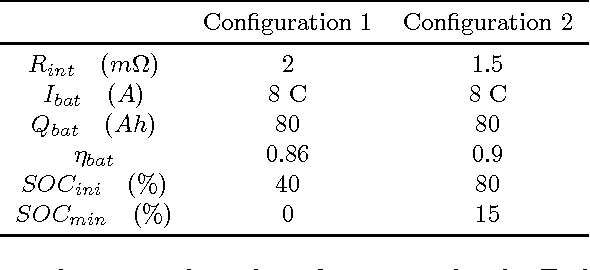

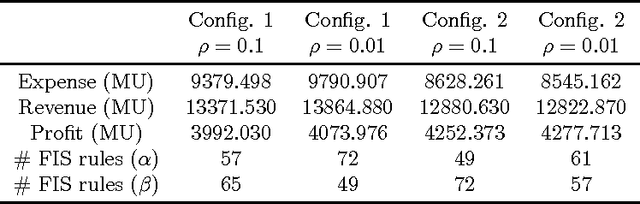
Bio-inspired algorithms like Genetic Algorithms and Fuzzy Inference Systems (FIS) are nowadays widely adopted as hybrid techniques in commercial and industrial environment. In this paper we present an interesting application of the fuzzy-GA paradigm to Smart Grids. The main aim consists in performing decision making for power flow management tasks in the proposed microgrid model equipped by renewable sources and an energy storage system, taking into account the economical profit in energy trading with the main-grid. In particular, this study focuses on the application of a Hierarchical Genetic Algorithm (HGA) for tuning the Rule Base (RB) of a Fuzzy Inference System (FIS), trying to discover a minimal fuzzy rules set in a Fuzzy Logic Controller (FLC) adopted to perform decision making in the microgrid. The HGA rationale focuses on a particular encoding scheme, based on control genes and parametric genes applied to the optimization of the FIS parameters, allowing to perform a reduction in the structural complexity of the RB. This approach will be referred in the following as fuzzy-HGA. Results are compared with a simpler approach based on a classic fuzzy-GA scheme, where both FIS parameters and rule weights are tuned, while the number of fuzzy rules is fixed in advance. Experiments shows how the fuzzy-HGA approach adopted for the synthesis of the proposed controller outperforms the classic fuzzy-GA scheme, increasing the accounting profit by 67\% in the considered energy trading problem yielding at the same time a simpler RB.
Data-driven detrending of nonstationary fractal time series with echo state networks
Oct 03, 2016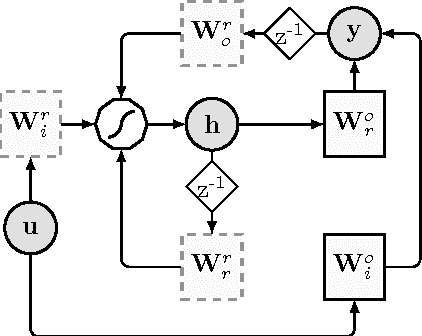

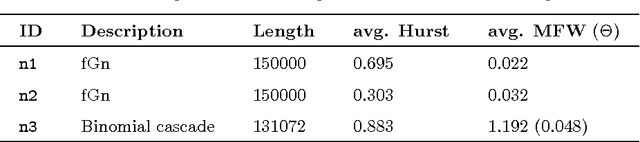
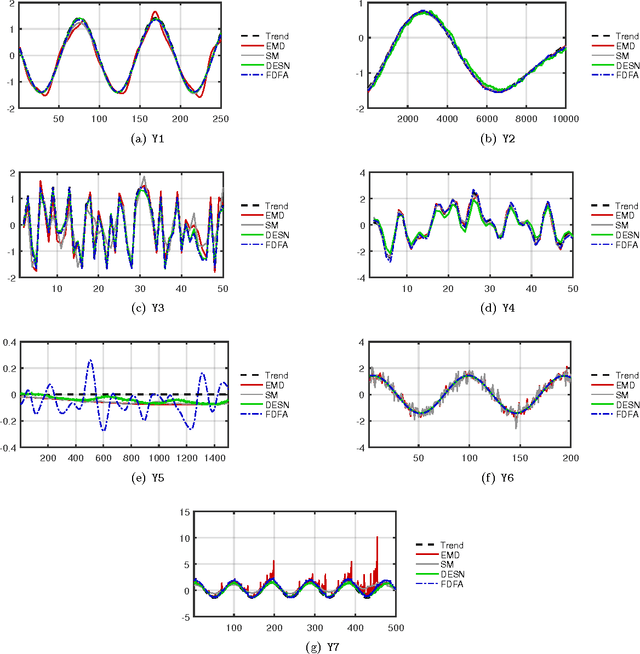
In this paper, we propose a novel data-driven approach for removing trends (detrending) from nonstationary, fractal and multifractal time series. We consider real-valued time series relative to measurements of an underlying dynamical system that evolves through time. We assume that such a dynamical process is predictable to a certain degree by means of a class of recurrent networks called Echo State Network (ESN), which are capable to model a generic dynamical process. In order to isolate the superimposed (multi)fractal component of interest, we define a data-driven filter by leveraging on the ESN prediction capability to identify the trend component of a given input time series. Specifically, the (estimated) trend is removed from the original time series and the residual signal is analyzed with the multifractal detrended fluctuation analysis procedure to verify the correctness of the detrending procedure. In order to demonstrate the effectiveness of the proposed technique, we consider several synthetic time series consisting of different types of trends and fractal noise components with known characteristics. We also process a real-world dataset, the sunspot time series, which is well-known for its multifractal features and has recently gained attention in the complex systems field. Results demonstrate the validity and generality of the proposed detrending method based on ESNs.
Position paper: a general framework for applying machine learning techniques in operating room
Nov 29, 2015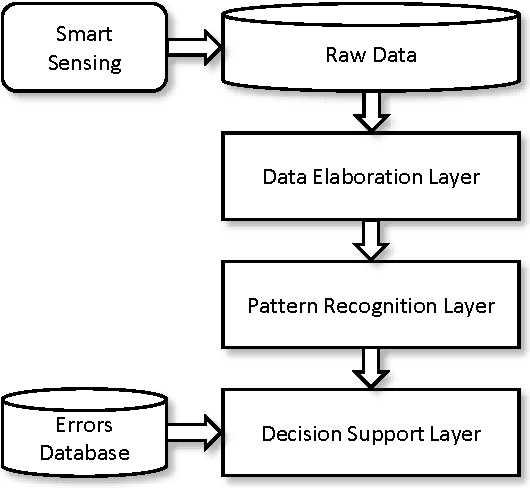
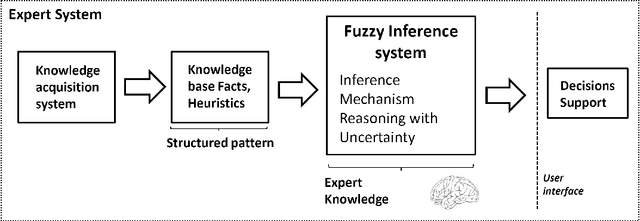
In this position paper we describe a general framework for applying machine learning and pattern recognition techniques in healthcare. In particular, we are interested in providing an automated tool for monitoring and incrementing the level of awareness in the operating room and for identifying human errors which occur during the laparoscopy surgical operation. The framework that we present is divided in three different layers: each layer implements algorithms which have an increasing level of complexity and which perform functionality with an higher degree of abstraction. In the first layer, raw data collected from sensors in the operating room during surgical operation, they are pre-processed and aggregated. The results of this initial phase are transferred to a second layer, which implements pattern recognition techniques and extract relevant features from the data. Finally, in the last layer, expert systems are employed to take high level decisions, which represent the final output of the system.
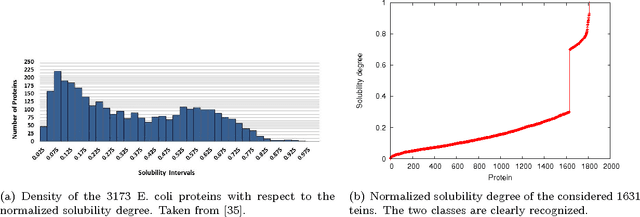
Characterization of graphs for protein structure modeling and recognition of solubility
Sep 23, 2015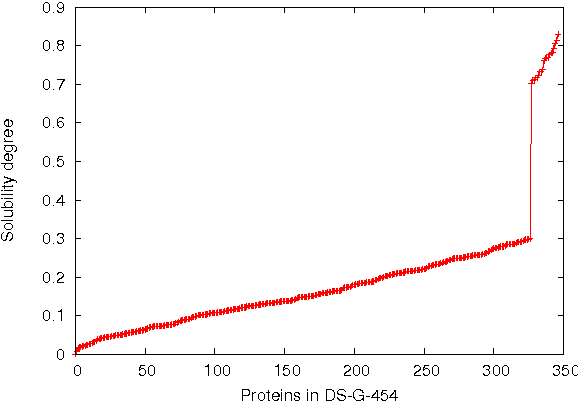
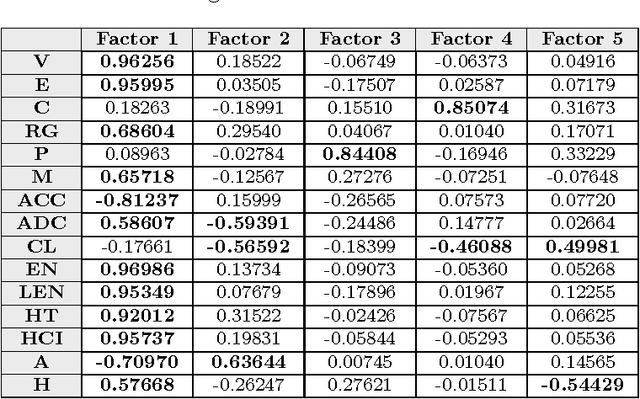
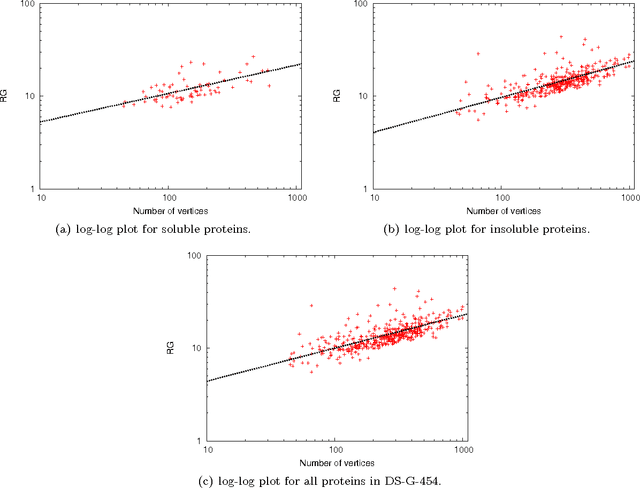
This paper deals with the relations among structural, topological, and chemical properties of the E.Coli proteome from the vantage point of the solubility/aggregation propensity of proteins. Each E.Coli protein is initially represented according to its known folded 3D shape. This step consists in representing the available E.Coli proteins in terms of graphs. We first analyze those graphs by considering pure topological characterizations, i.e., by analyzing the mass fractal dimension and the distribution underlying both shortest paths and vertex degrees. Results confirm the general architectural principles of proteins. Successively, we focus on the statistical properties of a representation of such graphs in terms of vectors composed of several numerical features, which we extracted from their structural representation. We found that protein size is the main discriminator for the solubility, while however there are other factors that help explaining the solubility degree. We finally analyze such data through a novel one-class classifier, with the aim of discriminating among very and poorly soluble proteins. Results are encouraging and consolidate the potential of pattern recognition techniques when employed to describe complex biological systems.
Discrimination and characterization of Parkinsonian rest tremors by analyzing long-term correlations and multifractal signatures
May 15, 2015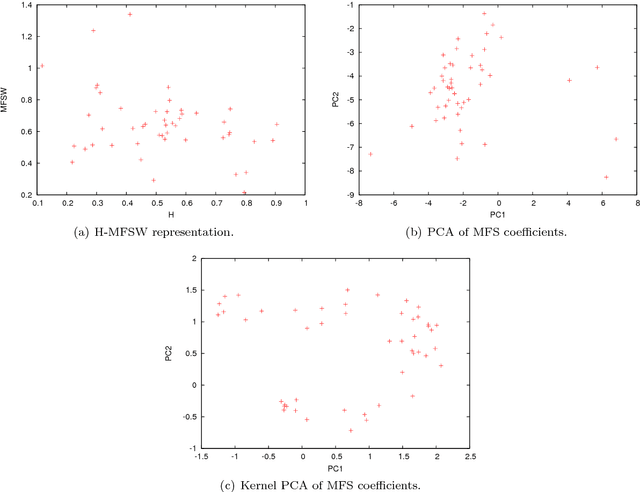
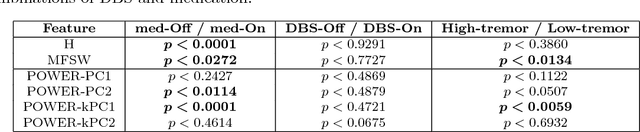
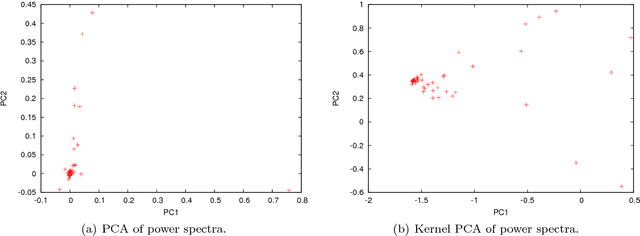
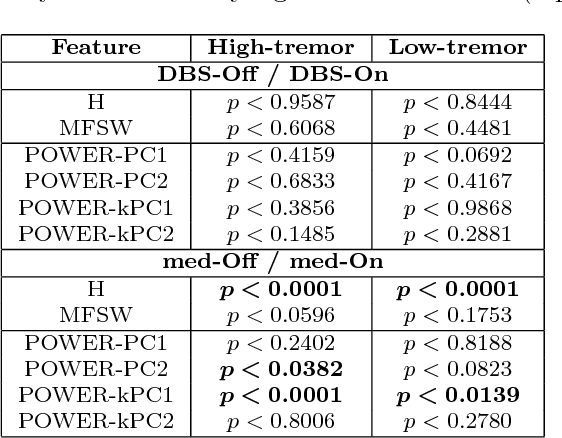
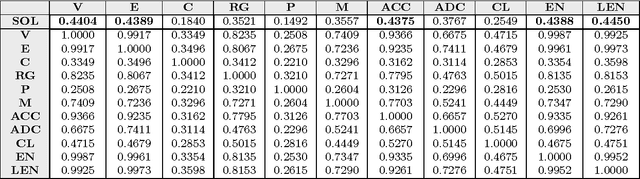
In this paper, we analyze 48 signals of rest tremor velocity related to 12 distinct subjects affected by Parkinson's disease. The subjects belong to two different groups, formed by four and eight subjects with, respectively, high- and low-amplitude rest tremors. Each subject is tested in four settings, given by combining the use of deep brain stimulation and L-DOPA medication. We develop two main feature-based representations of such signals, which are obtained by considering (i) the long-term correlations and multifractal properties, and (ii) the power spectra. The feature-based representations are initially utilized for the purpose of characterizing the subjects under different settings. In agreement with previous studies, we show that deep brain stimulation does not significantly characterize neither of the two groups, regardless of the adopted representation. On the other hand, the medication effect yields statistically significant differences in both high- and low-amplitude tremor groups. We successively test several different instances of the two feature-based representations of the signals in the setting of supervised classification and (nonlinear) feature transformation. We consider three different classification problems, involving the recognition of (i) the presence of medication, (ii) the use of deep brain stimulation, and (iii) the membership to the high- and low-amplitude tremor groups. Classification results show that the use of medication can be discriminated with higher accuracy, considering many of the feature-based representations. Notably, we show that the best results are obtained with a parsimonious, two-dimensional representation encoding the long-term correlations and multifractal character of the signals.
Data granulation by the principles of uncertainty
Mar 02, 2015
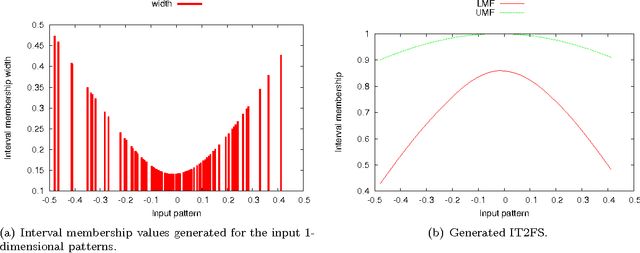
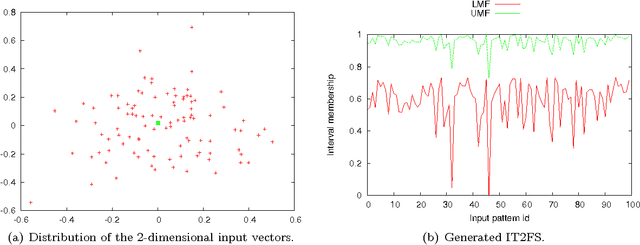
Researches in granular modeling produced a variety of mathematical models, such as intervals, (higher-order) fuzzy sets, rough sets, and shadowed sets, which are all suitable to characterize the so-called information granules. Modeling of the input data uncertainty is recognized as a crucial aspect in information granulation. Moreover, the uncertainty is a well-studied concept in many mathematical settings, such as those of probability theory, fuzzy set theory, and possibility theory. This fact suggests that an appropriate quantification of the uncertainty expressed by the information granule model could be used to define an invariant property, to be exploited in practical situations of information granulation. In this perspective, a procedure of information granulation is effective if the uncertainty conveyed by the synthesized information granule is in a monotonically increasing relation with the uncertainty of the input data. In this paper, we present a data granulation framework that elaborates over the principles of uncertainty introduced by Klir. Being the uncertainty a mesoscopic descriptor of systems and data, it is possible to apply such principles regardless of the input data type and the specific mathematical setting adopted for the information granules. The proposed framework is conceived (i) to offer a guideline for the synthesis of information granules and (ii) to build a groundwork to compare and quantitatively judge over different data granulation procedures. To provide a suitable case study, we introduce a new data granulation technique based on the minimum sum of distances, which is designed to generate type-2 fuzzy sets. We analyze the procedure by performing different experiments on two distinct data types: feature vectors and labeled graphs. Results show that the uncertainty of the input data is suitably conveyed by the generated type-2 fuzzy set models.
On the impact of topological properties of smart grids in power losses optimization problems
Jan 21, 2015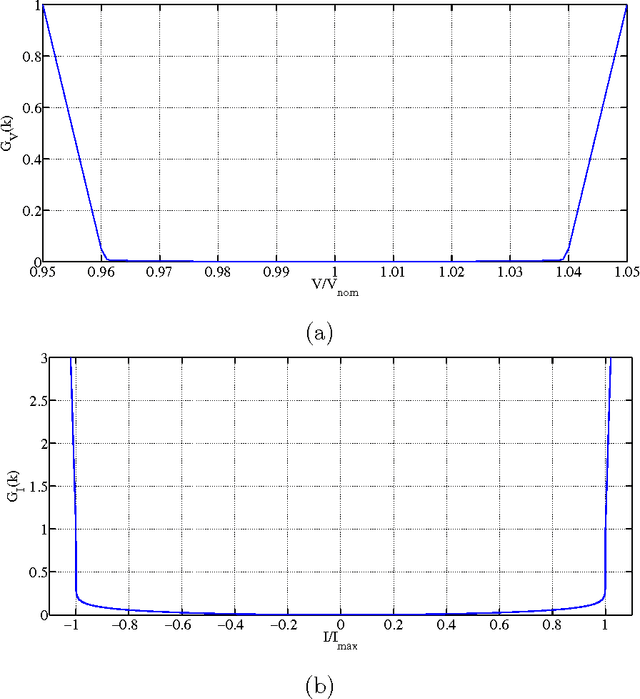
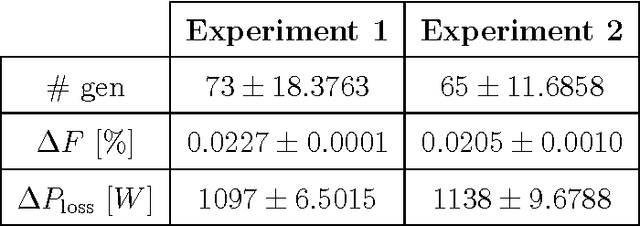
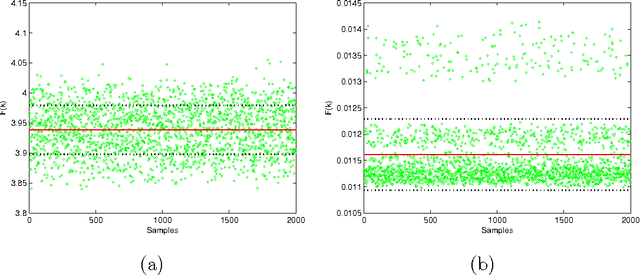
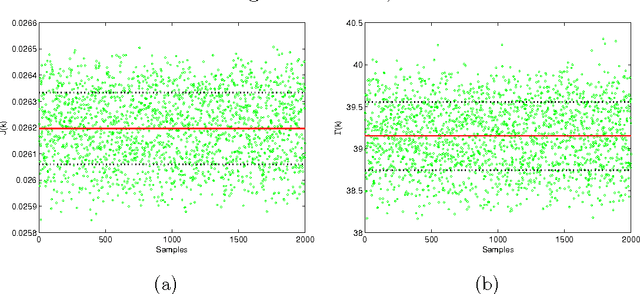
Power losses reduction is one of the main targets for any electrical energy distribution company. In this paper, we face the problem of joint optimization of both topology and network parameters in a real smart grid. We consider a portion of the Italian electric distribution network managed by the ACEA Distribuzione S.p.A. located in Rome. We perform both the power factor correction (PFC) for tuning the generators and the distributed feeder reconfiguration (DFR) to set the state of the breakers. This joint optimization problem is faced considering a suitable objective function and by adopting genetic algorithms as global optimization strategy. We analyze admissible network configurations, showing that some of these violate constraints on current and voltage at branches and nodes. Such violations depend only on pure topological properties of the configurations. We perform tests by feeding the simulation environment with real data concerning hourly samples of dissipated and generated active and reactive power values of the ACEA smart grid. Results show that removing the configurations violating the electrical constraints from the solution space leads to interesting improvements in terms of power loss reduction. To conclude, we provide also an electrical interpretation of the phenomenon using graph-based pattern analysis techniques.
Classifying sequences by the optimized dissimilarity space embedding approach: a case study on the solubility analysis of the E. coli proteome
Jan 14, 2015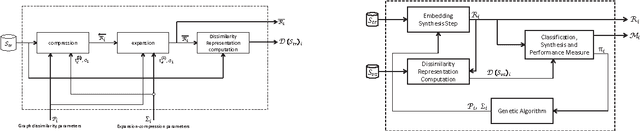
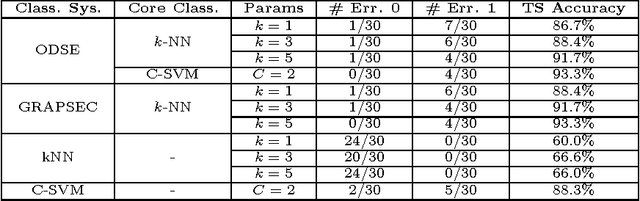
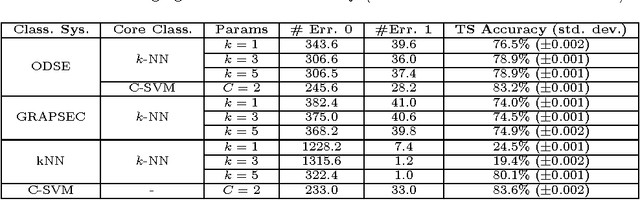
We evaluate a version of the recently-proposed classification system named Optimized Dissimilarity Space Embedding (ODSE) that operates in the input space of sequences of generic objects. The ODSE system has been originally presented as a classification system for patterns represented as labeled graphs. However, since ODSE is founded on the dissimilarity space representation of the input data, the classifier can be easily adapted to any input domain where it is possible to define a meaningful dissimilarity measure. Here we demonstrate the effectiveness of the ODSE classifier for sequences by considering an application dealing with the recognition of the solubility degree of the Escherichia coli proteome. Solubility, or analogously aggregation propensity, is an important property of protein molecules, which is intimately related to the mechanisms underlying the chemico-physical process of folding. Each protein of our dataset is initially associated with a solubility degree and it is represented as a sequence of symbols, denoting the 20 amino acid residues. The herein obtained computational results, which we stress that have been achieved with no context-dependent tuning of the ODSE system, confirm the validity and generality of the ODSE-based approach for structured data classification.