 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Online Hierarchical Energy Management System for Energy Communities, Complying with the Current Technical Legislation Framework
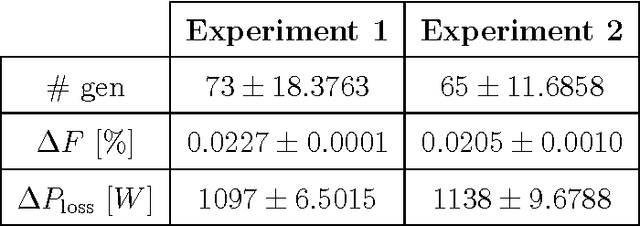
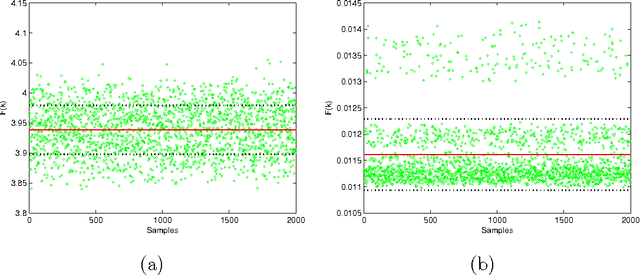
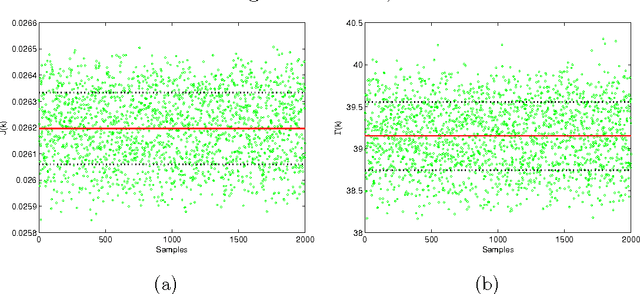
Jan 22, 2024Efforts in the fight against Climate Change are increasingly oriented towards new energy efficiency strategies in Smart Grids (SGs). In 2018, with proper legislation, the European Union (EU) defined the Renewable Energy Community (REC) as a local electrical grid whose participants share their self-produced renewable energy, aiming at reducing bill costs by taking advantage of proper incentives. That action aspires to accelerate the spread of local renewable energy exploitation, whose costs could not be within everyone's reach. Since a REC is technically an SG, the strategies above can be applied, and specifically, practical Energy Management Systems (EMSs) are required. Therefore, in this work, an online Hierarchical EMS (HEMS) is synthesized for REC cost minimization to evaluate its superiority over a local self-consumption approach. EU technical indications (as inherited from Italy) are diligently followed, aiming for results that are as realistic as possible. Power flows between REC nodes, or Microgrids (MGs) are optimized by taking Energy Storage Systems (ESSs) and PV plant costs, energy purchase costs, and REC incentives. A hybrid Fuzzy Inference System - Genetic Algorithm (FIS-GA) model is implemented with the GA encoding the FIS parameters. Power generation and consumption, which are the overall system input, are predicted by a LSTM trained on historical data. The proposed hierarchical model achieves good precision in short computation times and outperforms the self-consumption approach, leading to about 20% savings compared to the latter. In addition, the Explainable AI (XAI), which characterizes the model through the FIS, makes results more reliable thanks to an excellent human interpretation level. To finish, the HEMS is parametrized so that it is straightforward to switch to another Country's technical legislation framework.
An overview and comparative analysis of Recurrent Neural Networks for Short Term Load Forecasting
Jul 20, 2018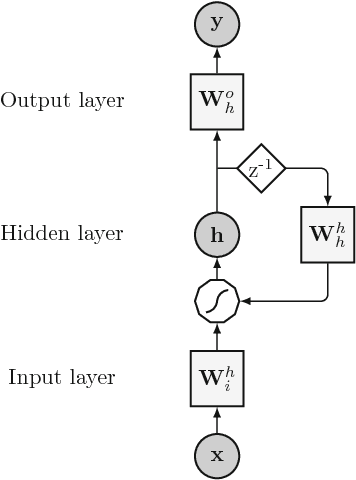
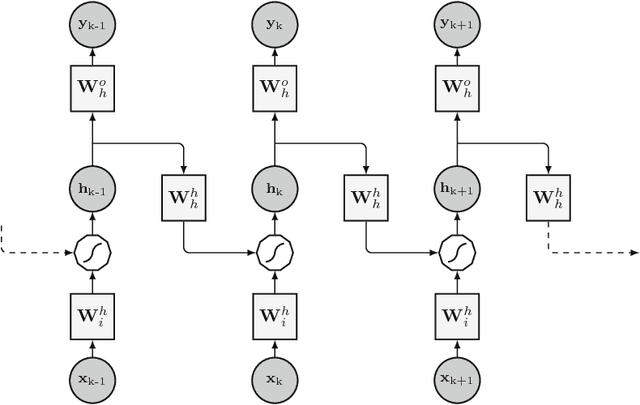
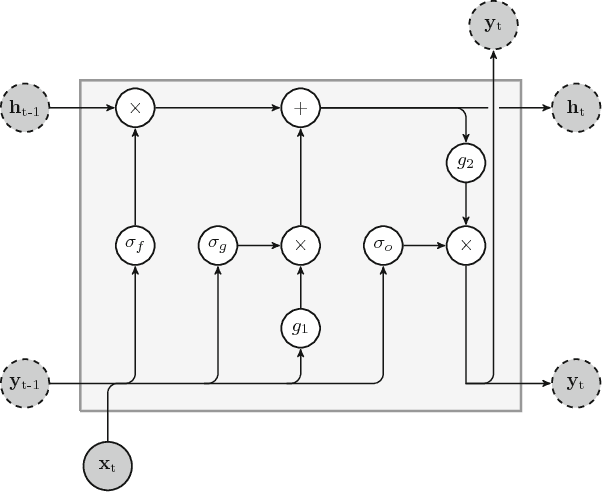
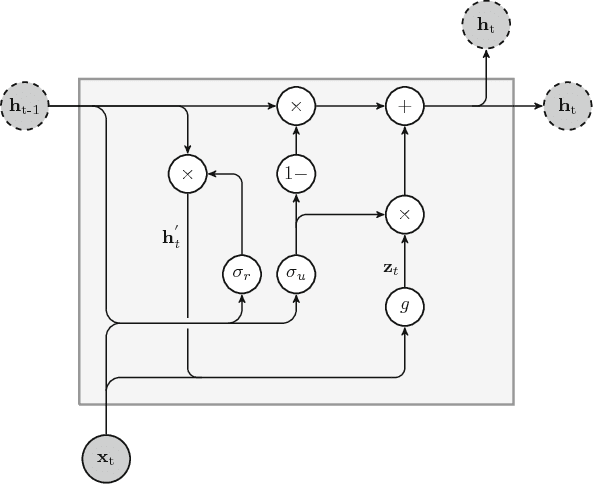
The key component in forecasting demand and consumption of resources in a supply network is an accurate prediction of real-valued time series. Indeed, both service interruptions and resource waste can be reduced with the implementation of an effective forecasting system. Significant research has thus been devoted to the design and development of methodologies for short term load forecasting over the past decades. A class of mathematical models, called Recurrent Neural Networks, are nowadays gaining renewed interest among researchers and they are replacing many practical implementation of the forecasting systems, previously based on static methods. Despite the undeniable expressive power of these architectures, their recurrent nature complicates their understanding and poses challenges in the training procedures. Recently, new important families of recurrent architectures have emerged and their applicability in the context of load forecasting has not been investigated completely yet. In this paper we perform a comparative study on the problem of Short-Term Load Forecast, by using different classes of state-of-the-art Recurrent Neural Networks. We test the reviewed models first on controlled synthetic tasks and then on different real datasets, covering important practical cases of study. We provide a general overview of the most important architectures and we define guidelines for configuring the recurrent networks to predict real-valued time series.
A Hierarchical Genetic Optimization of a Fuzzy Logic System for Flow Control in Micro Grids
Mar 01, 2017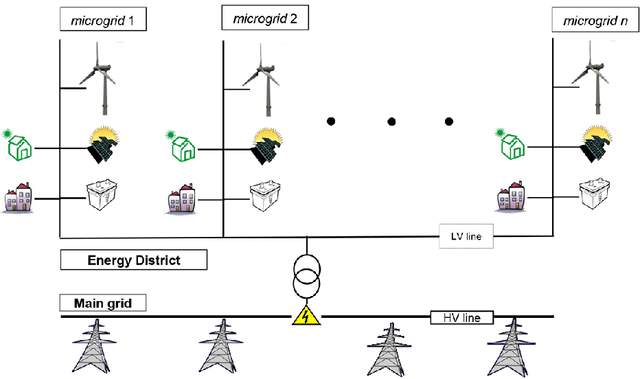

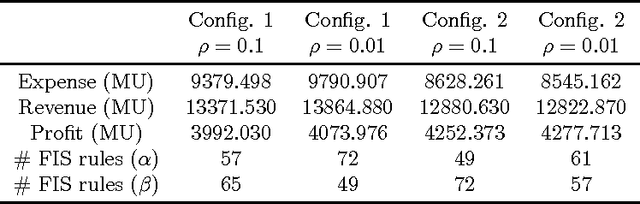
Bio-inspired algorithms like Genetic Algorithms and Fuzzy Inference Systems (FIS) are nowadays widely adopted as hybrid techniques in commercial and industrial environment. In this paper we present an interesting application of the fuzzy-GA paradigm to Smart Grids. The main aim consists in performing decision making for power flow management tasks in the proposed microgrid model equipped by renewable sources and an energy storage system, taking into account the economical profit in energy trading with the main-grid. In particular, this study focuses on the application of a Hierarchical Genetic Algorithm (HGA) for tuning the Rule Base (RB) of a Fuzzy Inference System (FIS), trying to discover a minimal fuzzy rules set in a Fuzzy Logic Controller (FLC) adopted to perform decision making in the microgrid. The HGA rationale focuses on a particular encoding scheme, based on control genes and parametric genes applied to the optimization of the FIS parameters, allowing to perform a reduction in the structural complexity of the RB. This approach will be referred in the following as fuzzy-HGA. Results are compared with a simpler approach based on a classic fuzzy-GA scheme, where both FIS parameters and rule weights are tuned, while the number of fuzzy rules is fixed in advance. Experiments shows how the fuzzy-HGA approach adopted for the synthesis of the proposed controller outperforms the classic fuzzy-GA scheme, increasing the accounting profit by 67\% in the considered energy trading problem yielding at the same time a simpler RB.
Data-driven detrending of nonstationary fractal time series with echo state networks
Oct 03, 2016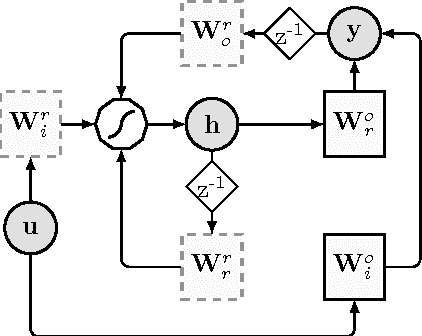

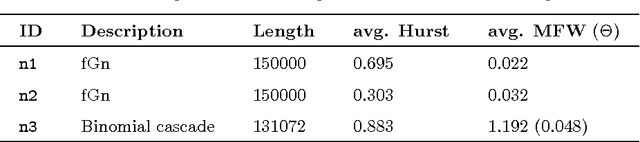
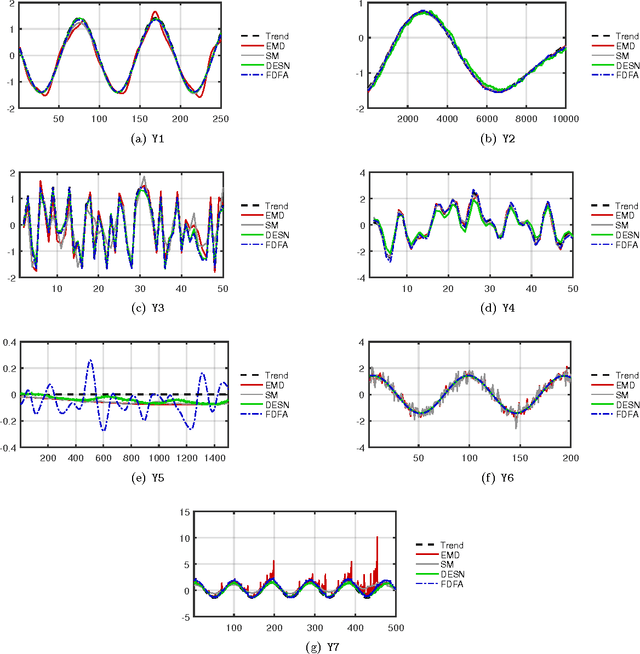
In this paper, we propose a novel data-driven approach for removing trends (detrending) from nonstationary, fractal and multifractal time series. We consider real-valued time series relative to measurements of an underlying dynamical system that evolves through time. We assume that such a dynamical process is predictable to a certain degree by means of a class of recurrent networks called Echo State Network (ESN), which are capable to model a generic dynamical process. In order to isolate the superimposed (multi)fractal component of interest, we define a data-driven filter by leveraging on the ESN prediction capability to identify the trend component of a given input time series. Specifically, the (estimated) trend is removed from the original time series and the residual signal is analyzed with the multifractal detrended fluctuation analysis procedure to verify the correctness of the detrending procedure. In order to demonstrate the effectiveness of the proposed technique, we consider several synthetic time series consisting of different types of trends and fractal noise components with known characteristics. We also process a real-world dataset, the sunspot time series, which is well-known for its multifractal features and has recently gained attention in the complex systems field. Results demonstrate the validity and generality of the proposed detrending method based on ESNs.
Toward a multilevel representation of protein molecules: comparative approaches to the aggregation/folding propensity problem
Apr 30, 2015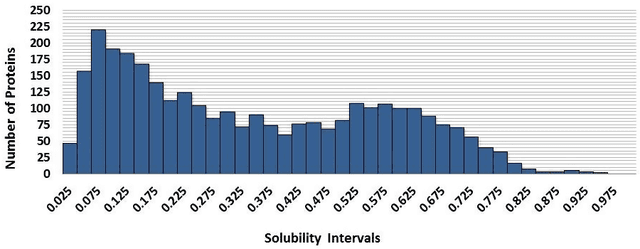


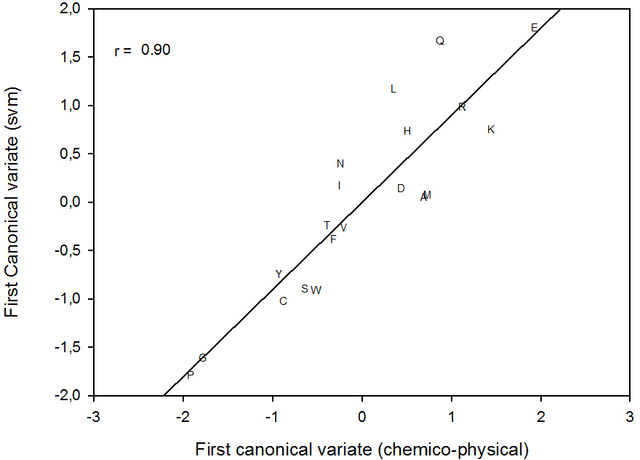
This paper builds upon the fundamental work of Niwa et al. [34], which provides the unique possibility to analyze the relative aggregation/folding propensity of the elements of the entire Escherichia coli (E. coli) proteome in a cell-free standardized microenvironment. The hardness of the problem comes from the superposition between the driving forces of intra- and inter-molecule interactions and it is mirrored by the evidences of shift from folding to aggregation phenotypes by single-point mutations [10]. Here we apply several state-of-the-art classification methods coming from the field of structural pattern recognition, with the aim to compare different representations of the same proteins gathered from the Niwa et al. data base; such representations include sequences and labeled (contact) graphs enriched with chemico-physical attributes. By this comparison, we are able to identify also some interesting general properties of proteins. Notably, (i) we suggest a threshold around 250 residues discriminating "easily foldable" from "hardly foldable" molecules consistent with other independent experiments, and (ii) we highlight the relevance of contact graph spectra for folding behavior discrimination and characterization of the E. coli solubility data. The soundness of the experimental results presented in this paper is proved by the statistically relevant relationships discovered among the chemico-physical description of proteins and the developed cost matrix of substitution used in the various discrimination systems.
Building pattern recognition applications with the SPARE library
Feb 20, 2015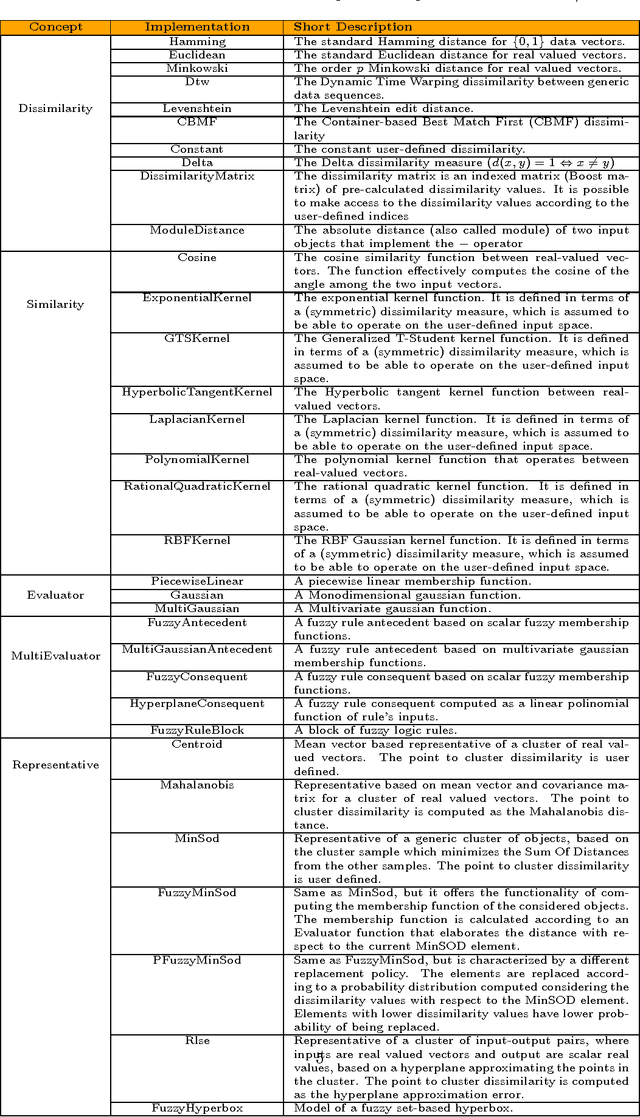
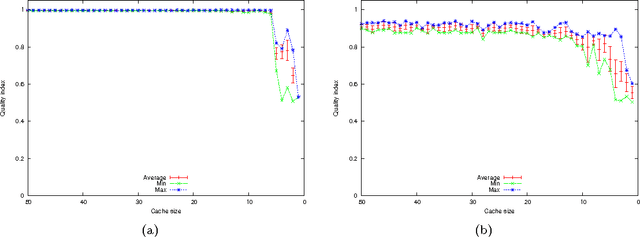
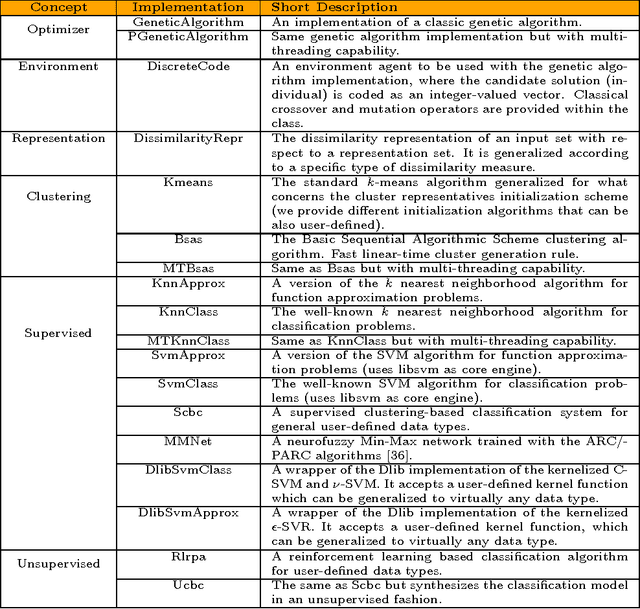
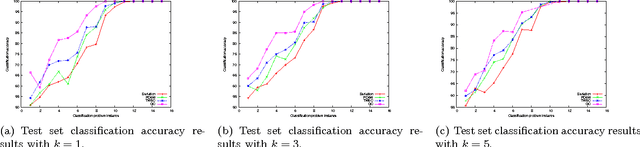
This paper presents the SPARE C++ library, an open source software tool conceived to build pattern recognition and soft computing systems. The library follows the requirement of the generality: most of the implemented algorithms are able to process user-defined input data types transparently, such as labeled graphs and sequences of objects, as well as standard numeric vectors. Here we present a high-level picture of the SPARE library characteristics, focusing instead on the specific practical possibility of constructing pattern recognition systems for different input data types. In particular, as a proof of concept, we discuss two application instances involving clustering of real-valued multidimensional sequences and classification of labeled graphs.
On the impact of topological properties of smart grids in power losses optimization problems
Jan 21, 2015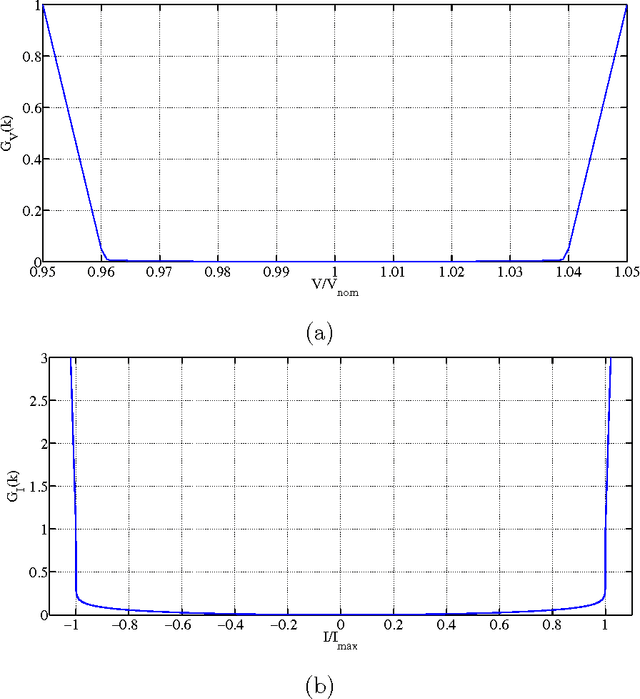
Power losses reduction is one of the main targets for any electrical energy distribution company. In this paper, we face the problem of joint optimization of both topology and network parameters in a real smart grid. We consider a portion of the Italian electric distribution network managed by the ACEA Distribuzione S.p.A. located in Rome. We perform both the power factor correction (PFC) for tuning the generators and the distributed feeder reconfiguration (DFR) to set the state of the breakers. This joint optimization problem is faced considering a suitable objective function and by adopting genetic algorithms as global optimization strategy. We analyze admissible network configurations, showing that some of these violate constraints on current and voltage at branches and nodes. Such violations depend only on pure topological properties of the configurations. We perform tests by feeding the simulation environment with real data concerning hourly samples of dissipated and generated active and reactive power values of the ACEA smart grid. Results show that removing the configurations violating the electrical constraints from the solution space leads to interesting improvements in terms of power loss reduction. To conclude, we provide also an electrical interpretation of the phenomenon using graph-based pattern analysis techniques.
Classifying sequences by the optimized dissimilarity space embedding approach: a case study on the solubility analysis of the E. coli proteome
Jan 14, 2015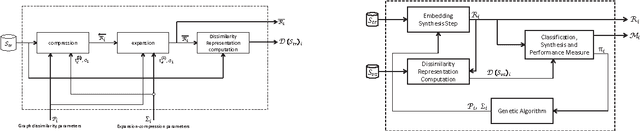
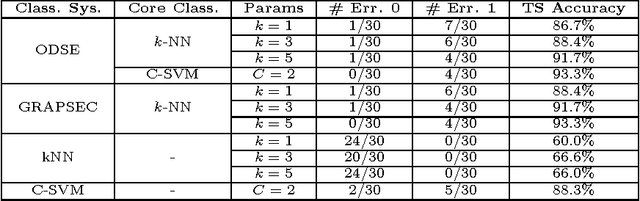
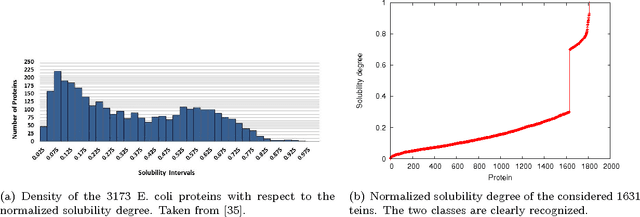
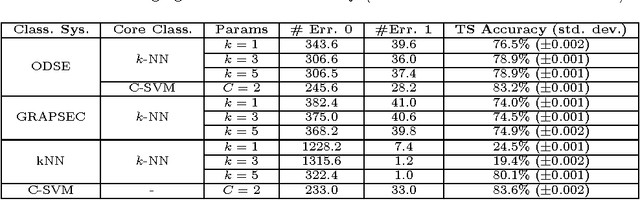
We evaluate a version of the recently-proposed classification system named Optimized Dissimilarity Space Embedding (ODSE) that operates in the input space of sequences of generic objects. The ODSE system has been originally presented as a classification system for patterns represented as labeled graphs. However, since ODSE is founded on the dissimilarity space representation of the input data, the classifier can be easily adapted to any input domain where it is possible to define a meaningful dissimilarity measure. Here we demonstrate the effectiveness of the ODSE classifier for sequences by considering an application dealing with the recognition of the solubility degree of the Escherichia coli proteome. Solubility, or analogously aggregation propensity, is an important property of protein molecules, which is intimately related to the mechanisms underlying the chemico-physical process of folding. Each protein of our dataset is initially associated with a solubility degree and it is represented as a sequence of symbols, denoting the 20 amino acid residues. The herein obtained computational results, which we stress that have been achieved with no context-dependent tuning of the ODSE system, confirm the validity and generality of the ODSE-based approach for structured data classification.
Modeling and Recognition of Smart Grid Faults by a Combined Approach of Dissimilarity Learning and One-Class Classification
Dec 17, 2014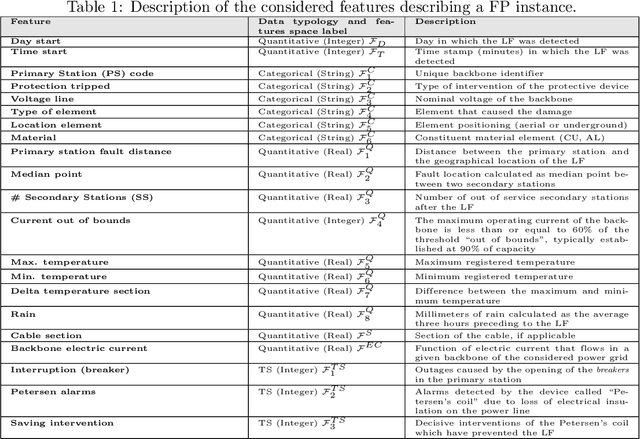
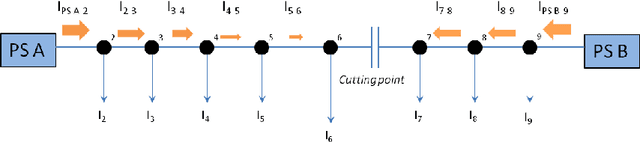
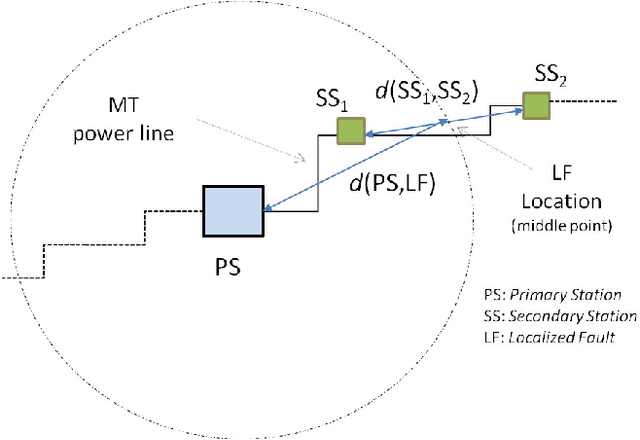

Detecting faults in electrical power grids is of paramount importance, either from the electricity operator and consumer viewpoints. Modern electric power grids (smart grids) are equipped with smart sensors that allow to gather real-time information regarding the physical status of all the component elements belonging to the whole infrastructure (e.g., cables and related insulation, transformers, breakers and so on). In real-world smart grid systems, usually, additional information that are related to the operational status of the grid itself are collected such as meteorological information. Designing a suitable recognition (discrimination) model of faults in a real-world smart grid system is hence a challenging task. This follows from the heterogeneity of the information that actually determine a typical fault condition. The second point is that, for synthesizing a recognition model, in practice only the conditions of observed faults are usually meaningful. Therefore, a suitable recognition model should be synthesized by making use of the observed fault conditions only. In this paper, we deal with the problem of modeling and recognizing faults in a real-world smart grid system, which supplies the entire city of Rome, Italy. Recognition of faults is addressed by following a combined approach of multiple dissimilarity measures customization and one-class classification techniques. We provide here an in-depth study related to the available data and to the models synthesized by the proposed one-class classifier. We offer also a comprehensive analysis of the fault recognition results by exploiting a fuzzy set based reliability decision rule.
An Agent-Based Algorithm exploiting Multiple Local Dissimilarities for Clusters Mining and Knowledge Discovery
Sep 17, 2014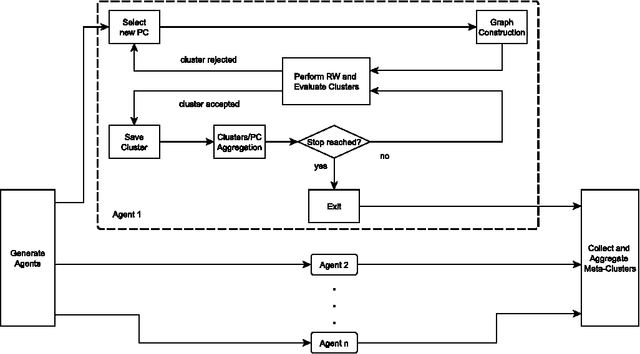


We propose a multi-agent algorithm able to automatically discover relevant regularities in a given dataset, determining at the same time the set of configurations of the adopted parametric dissimilarity measure yielding compact and separated clusters. Each agent operates independently by performing a Markovian random walk on a suitable weighted graph representation of the input dataset. Such a weighted graph representation is induced by the specific parameter configuration of the dissimilarity measure adopted by the agent, which searches and takes decisions autonomously for one cluster at a time. Results show that the algorithm is able to discover parameter configurations that yield a consistent and interpretable collection of clusters. Moreover, we demonstrate that our algorithm shows comparable performances with other similar state-of-the-art algorithms when facing specific clustering problems.