 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn overview and comparative analysis of Recurrent Neural Networks for Short Term Load Forecasting
Jul 20, 2018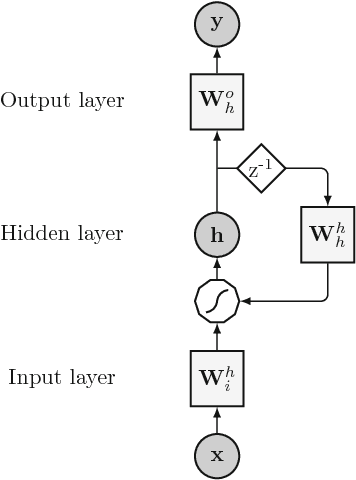
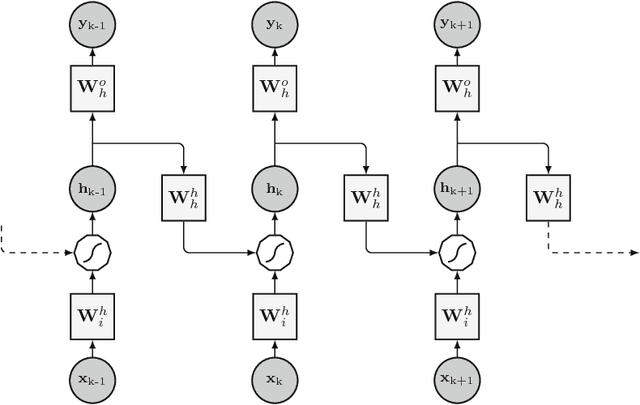
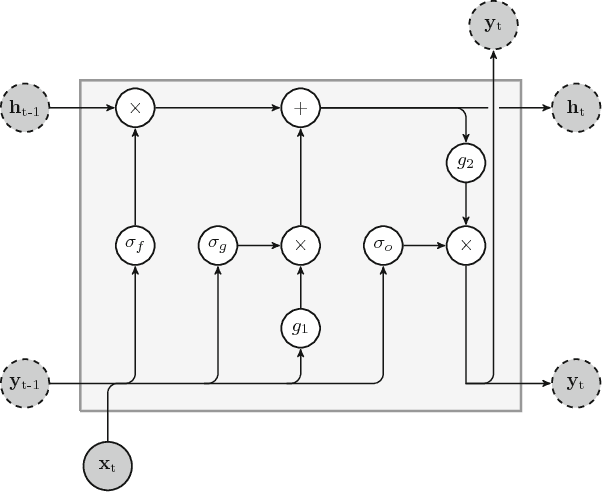
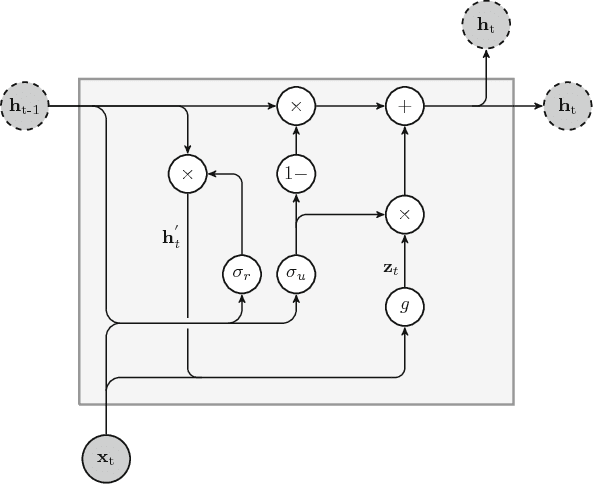
The key component in forecasting demand and consumption of resources in a supply network is an accurate prediction of real-valued time series. Indeed, both service interruptions and resource waste can be reduced with the implementation of an effective forecasting system. Significant research has thus been devoted to the design and development of methodologies for short term load forecasting over the past decades. A class of mathematical models, called Recurrent Neural Networks, are nowadays gaining renewed interest among researchers and they are replacing many practical implementation of the forecasting systems, previously based on static methods. Despite the undeniable expressive power of these architectures, their recurrent nature complicates their understanding and poses challenges in the training procedures. Recently, new important families of recurrent architectures have emerged and their applicability in the context of load forecasting has not been investigated completely yet. In this paper we perform a comparative study on the problem of Short-Term Load Forecast, by using different classes of state-of-the-art Recurrent Neural Networks. We test the reviewed models first on controlled synthetic tasks and then on different real datasets, covering important practical cases of study. We provide a general overview of the most important architectures and we define guidelines for configuring the recurrent networks to predict real-valued time series.
Temporal Overdrive Recurrent Neural Network
Jan 18, 2017
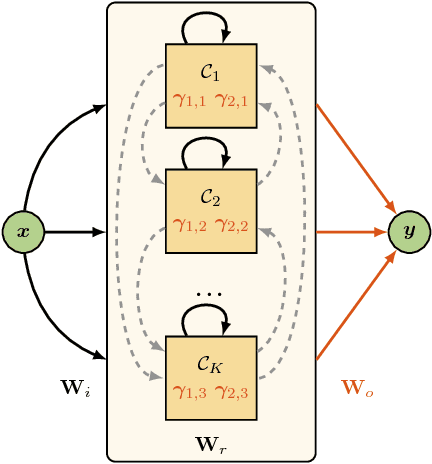
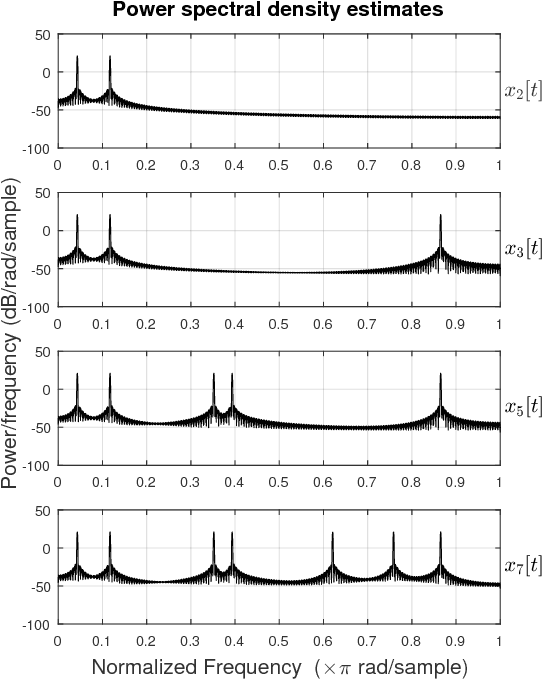
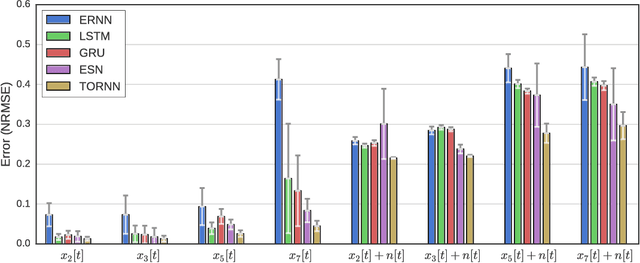
In this work we present a novel recurrent neural network architecture designed to model systems characterized by multiple characteristic timescales in their dynamics. The proposed network is composed by several recurrent groups of neurons that are trained to separately adapt to each timescale, in order to improve the system identification process. We test our framework on time series prediction tasks and we show some promising, preliminary results achieved on synthetic data. To evaluate the capabilities of our network, we compare the performance with several state-of-the-art recurrent architectures.
Data-driven detrending of nonstationary fractal time series with echo state networks
Oct 03, 2016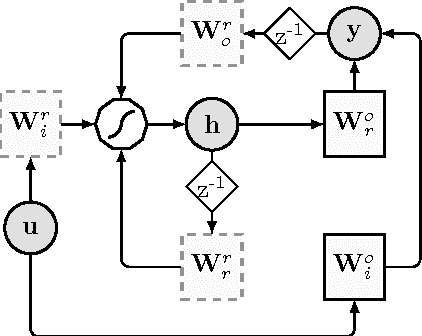

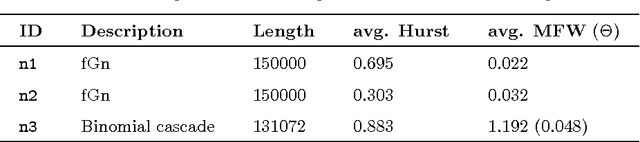
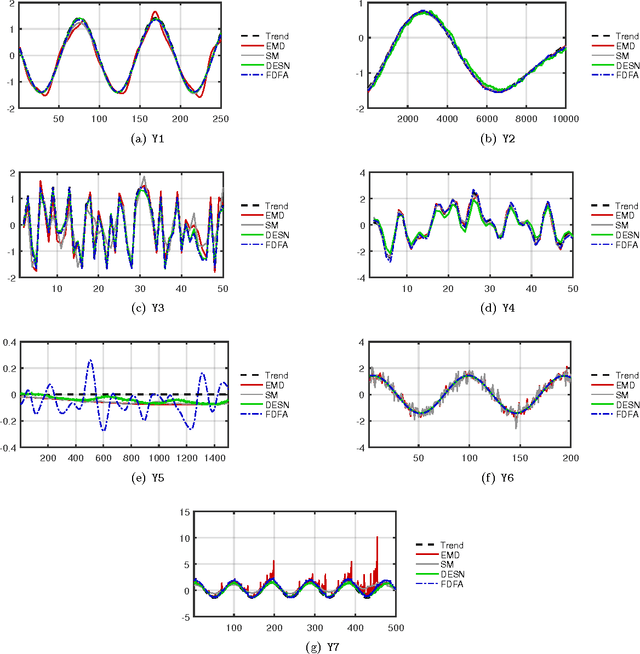
In this paper, we propose a novel data-driven approach for removing trends (detrending) from nonstationary, fractal and multifractal time series. We consider real-valued time series relative to measurements of an underlying dynamical system that evolves through time. We assume that such a dynamical process is predictable to a certain degree by means of a class of recurrent networks called Echo State Network (ESN), which are capable to model a generic dynamical process. In order to isolate the superimposed (multi)fractal component of interest, we define a data-driven filter by leveraging on the ESN prediction capability to identify the trend component of a given input time series. Specifically, the (estimated) trend is removed from the original time series and the residual signal is analyzed with the multifractal detrended fluctuation analysis procedure to verify the correctness of the detrending procedure. In order to demonstrate the effectiveness of the proposed technique, we consider several synthetic time series consisting of different types of trends and fractal noise components with known characteristics. We also process a real-world dataset, the sunspot time series, which is well-known for its multifractal features and has recently gained attention in the complex systems field. Results demonstrate the validity and generality of the proposed detrending method based on ESNs.
An Agent-Based Algorithm exploiting Multiple Local Dissimilarities for Clusters Mining and Knowledge Discovery
Sep 17, 2014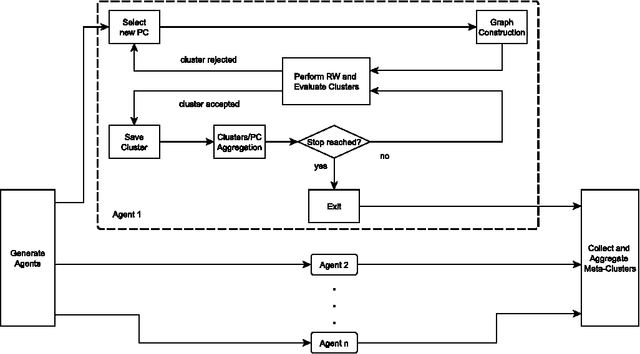

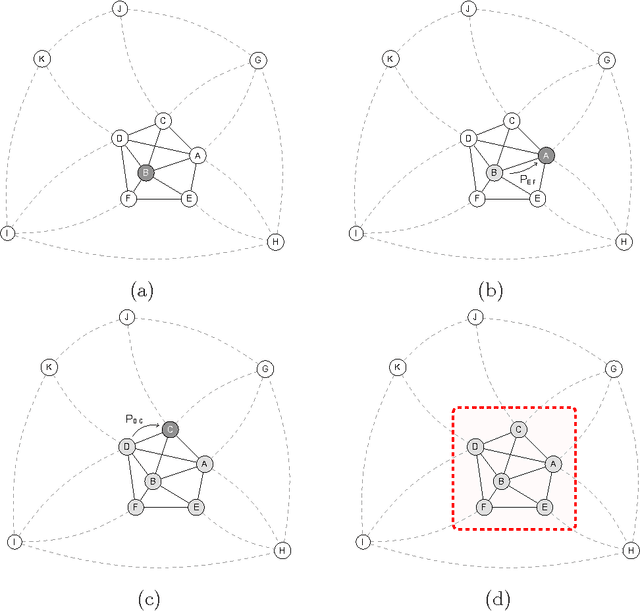

We propose a multi-agent algorithm able to automatically discover relevant regularities in a given dataset, determining at the same time the set of configurations of the adopted parametric dissimilarity measure yielding compact and separated clusters. Each agent operates independently by performing a Markovian random walk on a suitable weighted graph representation of the input dataset. Such a weighted graph representation is induced by the specific parameter configuration of the dissimilarity measure adopted by the agent, which searches and takes decisions autonomously for one cluster at a time. Results show that the algorithm is able to discover parameter configurations that yield a consistent and interpretable collection of clusters. Moreover, we demonstrate that our algorithm shows comparable performances with other similar state-of-the-art algorithms when facing specific clustering problems.