 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClassifying sequences by the optimized dissimilarity space embedding approach: a case study on the solubility analysis of the E. coli proteome
Paper and Code
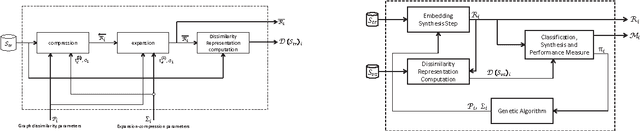
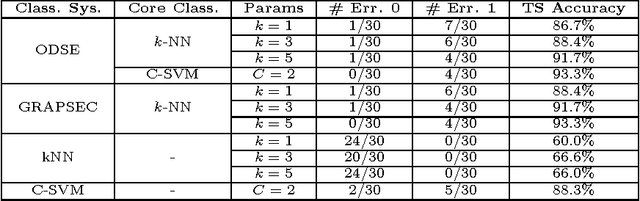
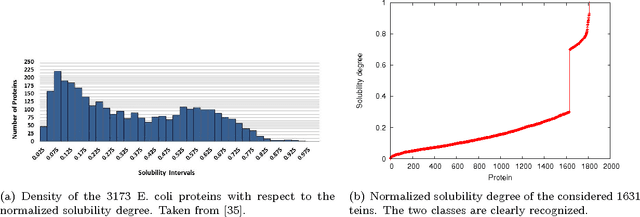
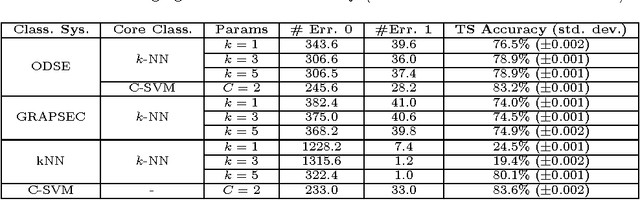
We evaluate a version of the recently-proposed classification system named Optimized Dissimilarity Space Embedding (ODSE) that operates in the input space of sequences of generic objects. The ODSE system has been originally presented as a classification system for patterns represented as labeled graphs. However, since ODSE is founded on the dissimilarity space representation of the input data, the classifier can be easily adapted to any input domain where it is possible to define a meaningful dissimilarity measure. Here we demonstrate the effectiveness of the ODSE classifier for sequences by considering an application dealing with the recognition of the solubility degree of the Escherichia coli proteome. Solubility, or analogously aggregation propensity, is an important property of protein molecules, which is intimately related to the mechanisms underlying the chemico-physical process of folding. Each protein of our dataset is initially associated with a solubility degree and it is represented as a sequence of symbols, denoting the 20 amino acid residues. The herein obtained computational results, which we stress that have been achieved with no context-dependent tuning of the ODSE system, confirm the validity and generality of the ODSE-based approach for structured data classification.