 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSituation Graph Prediction: Structured Perspective Inference for User Modeling
Feb 10, 2026Perspective-Aware AI requires modeling evolving internal states--goals, emotions, contexts--not merely preferences. Progress is limited by a data bottleneck: digital footprints are privacy-sensitive and perspective states are rarely labeled. We propose Situation Graph Prediction (SGP), a task that frames perspective modeling as an inverse inference problem: reconstructing structured, ontology-aligned representations of perspective from observable multimodal artifacts. To enable grounding without real labels, we use a structure-first synthetic generation strategy that aligns latent labels and observable traces by design. As a pilot, we construct a dataset and run a diagnostic study using retrieval-augmented in-context learning as a proxy for supervision. In our study with GPT-4o, we observe a gap between surface-level extraction and latent perspective inference--indicating latent-state inference is harder than surface extraction under our controlled setting. Results suggest SGP is non-trivial and provide evidence for the structure-first data synthesis strategy.
Structured Personalization: Modeling Constraints as Matroids for Data-Minimal LLM Agents
Dec 10, 2025Personalizing Large Language Model (LLM) agents requires conditioning them on user-specific data, creating a critical trade-off between task utility and data disclosure. While the utility of adding user data often exhibits diminishing returns (i.e., submodularity), enabling near-optimal greedy selection, real-world personalization is complicated by structural constraints. These include logical dependencies (e.g., selecting fact A requires fact B), categorical quotas (e.g., select at most one writing style), and hierarchical rules (e.g., select at most two social media preferences, of which at most one can be for a professional network). These constraints violate the assumptions of standard subset selection algorithms. We propose a principled method to formally model such constraints. We introduce a compilation process that transforms a user's knowledge graph with dependencies into a set of abstract macro-facets. Our central result is a proof that common hierarchical and quota-based constraints over these macro-facets form a valid laminar matroid. This theoretical characterization lets us cast structured personalization as submodular maximization under a matroid constraint, enabling greedy with constant-factor guarantees (and (1-1/e) via continuous greedy) for a much richer and more realistic class of problems.
Breadth-First Search vs. Restarting Random Walks for Escaping Uninformed Heuristic Regions
Nov 12, 2025Greedy search methods like Greedy Best-First Search (GBFS) and Enforced Hill-Climbing (EHC) often struggle when faced with Uninformed Heuristic Regions (UHRs) like heuristic local minima or plateaus. In this work, we theoretically and empirically compare two popular methods for escaping UHRs in breadth-first search (BrFS) and restarting random walks (RRWs). We first derive the expected runtime of escaping a UHR using BrFS and RRWs, based on properties of the UHR and the random walk procedure, and then use these results to identify when RRWs will be faster in expectation than BrFS. We then evaluate these methods for escaping UHRs by comparing standard EHC, which uses BrFS to escape UHRs, to variants of EHC called EHC-RRW, which use RRWs for that purpose. EHC-RRW is shown to have strong expected runtime guarantees in cases where EHC has previously been shown to be effective. We also run experiments with these approaches on PDDL planning benchmarks to better understand their relative effectiveness for escaping UHRs.
Preset-Voice Matching for Privacy Regulated Speech-to-Speech Translation Systems
Jul 18, 2024



In recent years, there has been increased demand for speech-to-speech translation (S2ST) systems in industry settings. Although successfully commercialized, cloning-based S2ST systems expose their distributors to liabilities when misused by individuals and can infringe on personality rights when exploited by media organizations. This work proposes a regulated S2ST framework called Preset-Voice Matching (PVM). PVM removes cross-lingual voice cloning in S2ST by first matching the input voice to a similar prior consenting speaker voice in the target-language. With this separation, PVM avoids cloning the input speaker, ensuring PVM systems comply with regulations and reduce risk of misuse. Our results demonstrate PVM can significantly improve S2ST system run-time in multi-speaker settings and the naturalness of S2ST synthesized speech. To our knowledge, PVM is the first explicitly regulated S2ST framework leveraging similarly-matched preset-voices for dynamic S2ST tasks.
Expected Runtime Comparisons Between Breadth-First Search and Constant-Depth Restarting Random Walks
Jun 24, 2024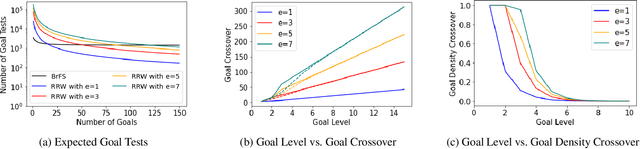
When greedy search algorithms encounter a local minima or plateau, the search typically devolves into a breadth-first search (BrFS), or a local search technique is used in an attempt to find a way out. In this work, we formally analyze the performance of BrFS and constant-depth restarting random walks (RRW) -- two methods often used for finding exits to a plateau/local minima -- to better understand when each is best suited. In particular, we formally derive the expected runtime for BrFS in the case of a uniformly distributed set of goals at a given goal depth. We then prove RRW will be faster than BrFS on trees if there are enough goals at that goal depth. We refer to this threshold as the crossover point. Our bound shows that the crossover point grows linearly with the branching factor of the tree, the goal depth, and the error in the random walk depth, while the size of the tree grows exponentially in branching factor and goal depth. Finally, we discuss the practical implications and applicability of this bound.
GANsemble for Small and Imbalanced Data Sets: A Baseline for Synthetic Microplastics Data
Apr 10, 2024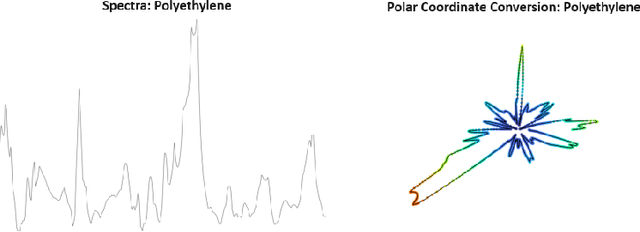
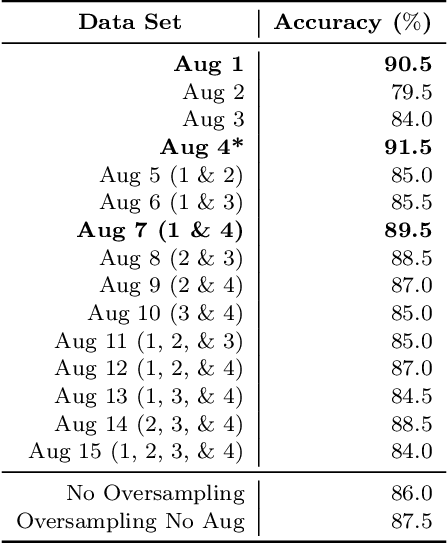
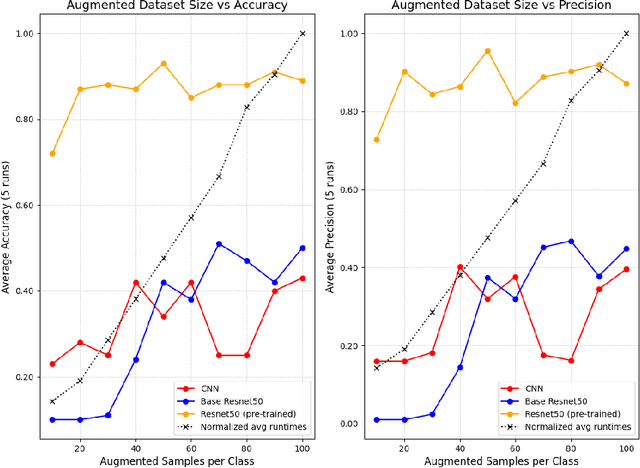
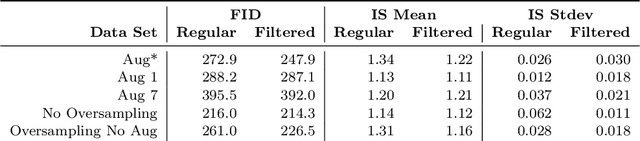
Microplastic particle ingestion or inhalation by humans is a problem of growing concern. Unfortunately, current research methods that use machine learning to understand their potential harms are obstructed by a lack of available data. Deep learning techniques in particular are challenged by such domains where only small or imbalanced data sets are available. Overcoming this challenge often involves oversampling underrepresented classes or augmenting the existing data to improve model performance. This paper proposes GANsemble: a two-module framework connecting data augmentation with conditional generative adversarial networks (cGANs) to generate class-conditioned synthetic data. First, the data chooser module automates augmentation strategy selection by searching for the best data augmentation strategy. Next, the cGAN module uses this strategy to train a cGAN for generating enhanced synthetic data. We experiment with the GANsemble framework on a small and imbalanced microplastics data set. A Microplastic-cGAN (MPcGAN) algorithm is introduced, and baselines for synthetic microplastics (SYMP) data are established in terms of Frechet Inception Distance (FID) and Inception Scores (IS). We also provide a synthetic microplastics filter (SYMP-Filter) algorithm to increase the quality of generated SYMP. Additionally, we show the best amount of oversampling with augmentation to fix class imbalance in small microplastics data sets. To our knowledge, this study is the first application of generative AI to synthetically create microplastics data.
Deep Unfolding for Iterative Stripe Noise Removal
Sep 27, 2022


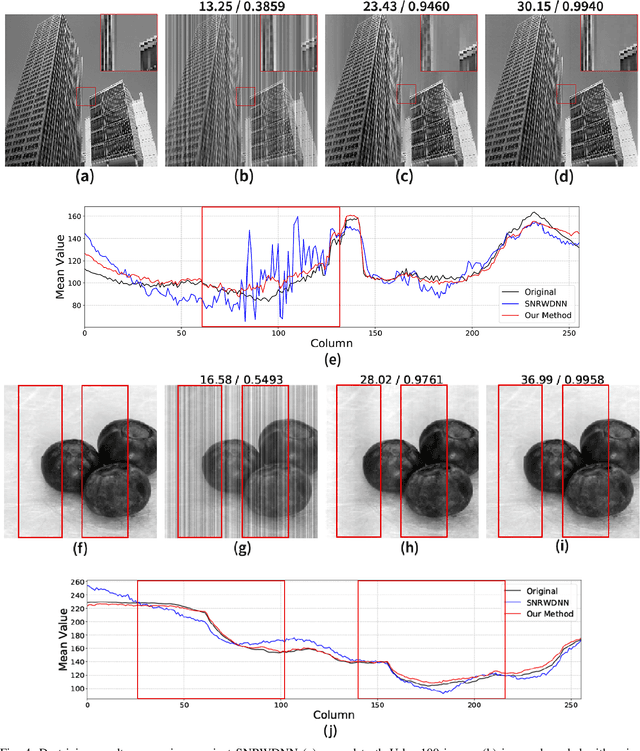
The non-uniform photoelectric response of infrared imaging systems results in fixed-pattern stripe noise being superimposed on infrared images, which severely reduces image quality. As the applications of degraded infrared images are limited, it is crucial to effectively preserve original details. Existing image destriping methods struggle to concurrently remove all stripe noise artifacts, preserve image details and structures, and balance real-time performance. In this paper we propose a novel algorithm for destriping degraded images, which takes advantage of neighbouring column signal correlation to remove independent column stripe noise. This is achieved through an iterative deep unfolding algorithm where the estimated noise of one network iteration is used as input to the next iteration. This progression substantially reduces the search space of possible function approximations, allowing for efficient training on larger datasets. The proposed method allows for a more precise estimation of stripe noise to preserve scene details more accurately. Extensive experimental results demonstrate that the proposed model outperforms existing destriping methods on artificially corrupted images on both quantitative and qualitative assessments.