 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProject Ariadne: A Structural Causal Framework for Auditing Faithfulness in LLM Agents
Jan 05, 2026As Large Language Model (LLM) agents are increasingly tasked with high-stakes autonomous decision-making, the transparency of their reasoning processes has become a critical safety concern. While \textit{Chain-of-Thought} (CoT) prompting allows agents to generate human-readable reasoning traces, it remains unclear whether these traces are \textbf{faithful} generative drivers of the model's output or merely \textbf{post-hoc rationalizations}. We introduce \textbf{Project Ariadne}, a novel XAI framework that utilizes Structural Causal Models (SCMs) and counterfactual logic to audit the causal integrity of agentic reasoning. Unlike existing interpretability methods that rely on surface-level textual similarity, Project Ariadne performs \textbf{hard interventions} ($do$-calculus) on intermediate reasoning nodes -- systematically inverting logic, negating premises, and reversing factual claims -- to measure the \textbf{Causal Sensitivity} ($φ$) of the terminal answer. Our empirical evaluation of state-of-the-art models reveals a persistent \textit{Faithfulness Gap}. We define and detect a widespread failure mode termed \textbf{Causal Decoupling}, where agents exhibit a violation density ($ρ$) of up to $0.77$ in factual and scientific domains. In these instances, agents arrive at identical conclusions despite contradictory internal logic, proving that their reasoning traces function as "Reasoning Theater" while decision-making is governed by latent parametric priors. Our findings suggest that current agentic architectures are inherently prone to unfaithful explanation, and we propose the Ariadne Score as a new benchmark for aligning stated logic with model action.
Breadth-First Search vs. Restarting Random Walks for Escaping Uninformed Heuristic Regions
Nov 12, 2025Greedy search methods like Greedy Best-First Search (GBFS) and Enforced Hill-Climbing (EHC) often struggle when faced with Uninformed Heuristic Regions (UHRs) like heuristic local minima or plateaus. In this work, we theoretically and empirically compare two popular methods for escaping UHRs in breadth-first search (BrFS) and restarting random walks (RRWs). We first derive the expected runtime of escaping a UHR using BrFS and RRWs, based on properties of the UHR and the random walk procedure, and then use these results to identify when RRWs will be faster in expectation than BrFS. We then evaluate these methods for escaping UHRs by comparing standard EHC, which uses BrFS to escape UHRs, to variants of EHC called EHC-RRW, which use RRWs for that purpose. EHC-RRW is shown to have strong expected runtime guarantees in cases where EHC has previously been shown to be effective. We also run experiments with these approaches on PDDL planning benchmarks to better understand their relative effectiveness for escaping UHRs.
GANsemble for Small and Imbalanced Data Sets: A Baseline for Synthetic Microplastics Data
Apr 10, 2024
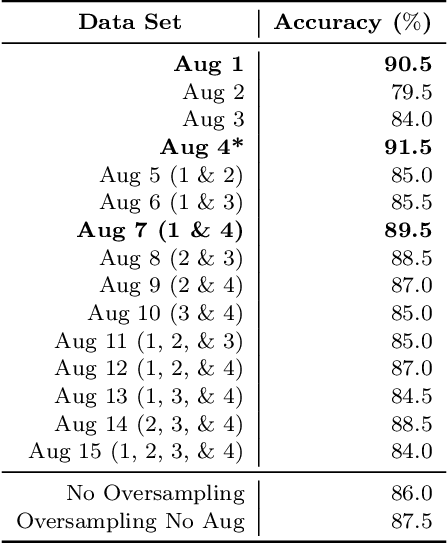
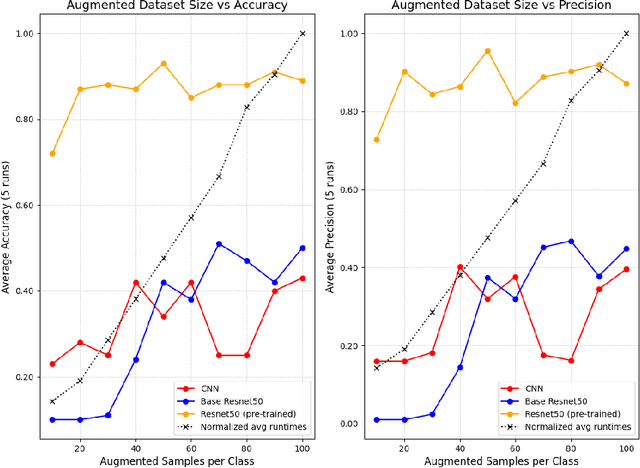
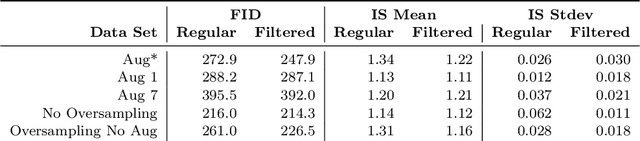
Microplastic particle ingestion or inhalation by humans is a problem of growing concern. Unfortunately, current research methods that use machine learning to understand their potential harms are obstructed by a lack of available data. Deep learning techniques in particular are challenged by such domains where only small or imbalanced data sets are available. Overcoming this challenge often involves oversampling underrepresented classes or augmenting the existing data to improve model performance. This paper proposes GANsemble: a two-module framework connecting data augmentation with conditional generative adversarial networks (cGANs) to generate class-conditioned synthetic data. First, the data chooser module automates augmentation strategy selection by searching for the best data augmentation strategy. Next, the cGAN module uses this strategy to train a cGAN for generating enhanced synthetic data. We experiment with the GANsemble framework on a small and imbalanced microplastics data set. A Microplastic-cGAN (MPcGAN) algorithm is introduced, and baselines for synthetic microplastics (SYMP) data are established in terms of Frechet Inception Distance (FID) and Inception Scores (IS). We also provide a synthetic microplastics filter (SYMP-Filter) algorithm to increase the quality of generated SYMP. Additionally, we show the best amount of oversampling with augmentation to fix class imbalance in small microplastics data sets. To our knowledge, this study is the first application of generative AI to synthetically create microplastics data.
Opti Code Pro: A Heuristic Search-based Approach to Code Refactoring
May 12, 2023This paper presents an approach that evaluates best-first search methods to code refactoring. The motivation for code refactoring could be to improve the design, structure, or implementation of an existing program without changing its functionality. To solve a very specific problem of coupling and cohesion, we propose using heuristic search-based techniques on an approximation of the full code refactoring problem, to guide the refactoring process toward solutions that have high cohesion and low coupling. We evaluated our approach by providing demonstrative examples of the effectiveness of this approach on random state problems and created a tool to implement the algorithm on Java projects.