 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI-Assisted Colonoscopy: Polyp Detection and Segmentation using Foundation Models
Mar 31, 2025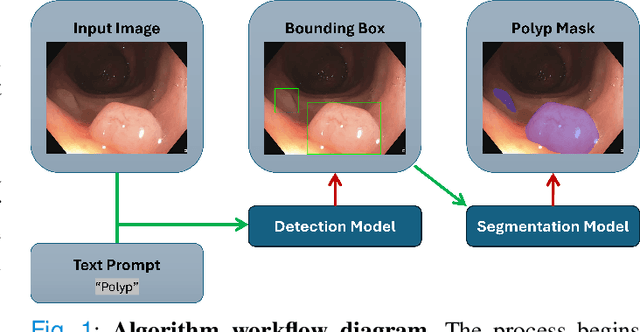



In colonoscopy, 80% of the missed polyps could be detected with the help of Deep Learning models. In the search for algorithms capable of addressing this challenge, foundation models emerge as promising candidates. Their zero-shot or few-shot learning capabilities, facilitate generalization to new data or tasks without extensive fine-tuning. A concept that is particularly advantageous in the medical imaging domain, where large annotated datasets for traditional training are scarce. In this context, a comprehensive evaluation of foundation models for polyp segmentation was conducted, assessing both detection and delimitation. For the study, three different colonoscopy datasets have been employed to compare the performance of five different foundation models, DINOv2, YOLO-World, GroundingDINO, SAM and MedSAM, against two benchmark networks, YOLOv8 and Mask R-CNN. Results show that the success of foundation models in polyp characterization is highly dependent on domain specialization. For optimal performance in medical applications, domain-specific models are essential, and generic models require fine-tuning to achieve effective results. Through this specialization, foundation models demonstrated superior performance compared to state-of-the-art detection and segmentation models, with some models even excelling in zero-shot evaluation; outperforming fine-tuned models on unseen data.
Unleashing the Potential of Synthetic Images: A Study on Histopathology Image Classification
Sep 24, 2024Histopathology image classification is crucial for the accurate identification and diagnosis of various diseases but requires large and diverse datasets. Obtaining such datasets, however, is often costly and time-consuming due to the need for expert annotations and ethical constraints. To address this, we examine the suitability of different generative models and image selection approaches to create realistic synthetic histopathology image patches conditioned on class labels. Our findings highlight the importance of selecting an appropriate generative model type and architecture to enhance performance. Our experiments over the PCam dataset show that diffusion models are effective for transfer learning, while GAN-generated samples are better suited for augmentation. Additionally, transformer-based generative models do not require image filtering, in contrast to those derived from Convolutional Neural Networks (CNNs), which benefit from realism score-based selection. Therefore, we show that synthetic images can effectively augment existing datasets, ultimately improving the performance of the downstream histopathology image classification task.
MVMO: A Multi-Object Dataset for Wide Baseline Multi-View Semantic Segmentation
May 30, 2022
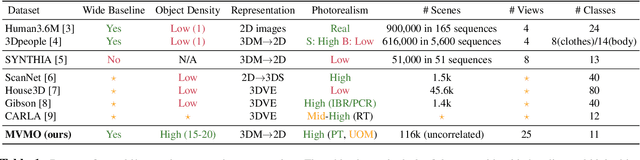


We present MVMO (Multi-View, Multi-Object dataset): a synthetic dataset of 116,000 scenes containing randomly placed objects of 10 distinct classes and captured from 25 camera locations in the upper hemisphere. MVMO comprises photorealistic, path-traced image renders, together with semantic segmentation ground truth for every view. Unlike existing multi-view datasets, MVMO features wide baselines between cameras and high density of objects, which lead to large disparities, heavy occlusions and view-dependent object appearance. Single view semantic segmentation is hindered by self and inter-object occlusions that could benefit from additional viewpoints. Therefore, we expect that MVMO will propel research in multi-view semantic segmentation and cross-view semantic transfer. We also provide baselines that show that new research is needed in such fields to exploit the complementary information of multi-view setups.
Self-supervised blur detection from synthetically blurred scenes
Aug 28, 2019
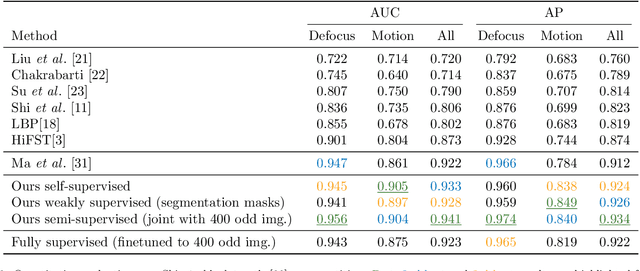


Blur detection aims at segmenting the blurred areas of a given image. Recent deep learning-based methods approach this problem by learning an end-to-end mapping between the blurred input and a binary mask representing the localization of its blurred areas. Nevertheless, the effectiveness of such deep models is limited due to the scarcity of datasets annotated in terms of blur segmentation, as blur annotation is labour intensive. In this work, we bypass the need for such annotated datasets for end-to-end learning, and instead rely on object proposals and a model for blur generation in order to produce a dataset of synthetically blurred images. This allows us to perform self-supervised learning over the generated image and ground truth blur mask pairs using CNNs, defining a framework that can be employed in purely self-supervised, weakly supervised or semi-supervised configurations. Interestingly, experimental results of such setups over the largest blur segmentation datasets available show that this approach achieves state of the art results in blur segmentation, even without ever observing any real blurred image.
On the Duality Between Retinex and Image Dehazing
Apr 06, 2018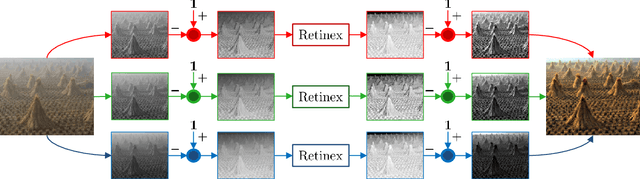
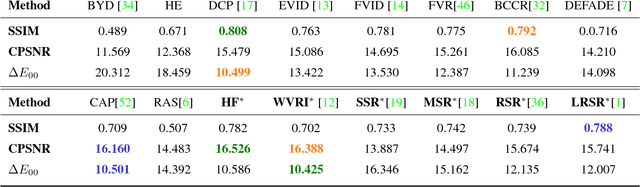

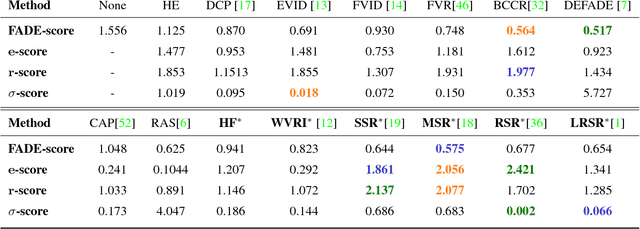
Image dehazing deals with the removal of undesired loss of visibility in outdoor images due to the presence of fog. Retinex is a color vision model mimicking the ability of the Human Visual System to robustly discount varying illuminations when observing a scene under different spectral lighting conditions. Retinex has been widely explored in the computer vision literature for image enhancement and other related tasks. While these two problems are apparently unrelated, the goal of this work is to show that they can be connected by a simple linear relationship. Specifically, most Retinex-based algorithms have the characteristic feature of always increasing image brightness, which turns them into ideal candidates for effective image dehazing by directly applying Retinex to a hazy image whose intensities have been inverted. In this paper, we give theoretical proof that Retinex on inverted intensities is a solution to the image dehazing problem. Comprehensive qualitative and quantitative results indicate that several classical and modern implementations of Retinex can be transformed into competing image dehazing algorithms performing on pair with more complex fog removal methods, and can overcome some of the main challenges associated with this problem.
Data-Driven Color Augmentation Techniques for Deep Skin Image Analysis
Mar 10, 2017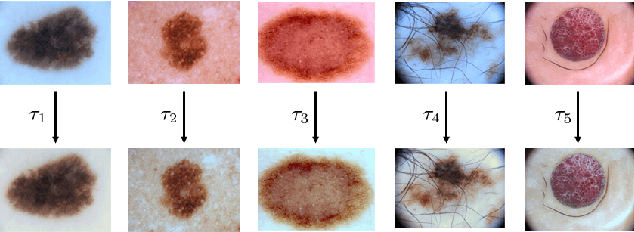
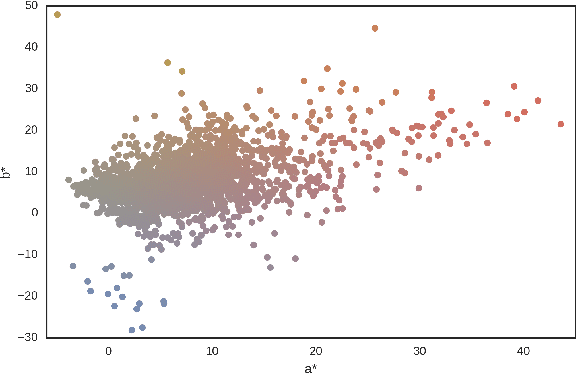

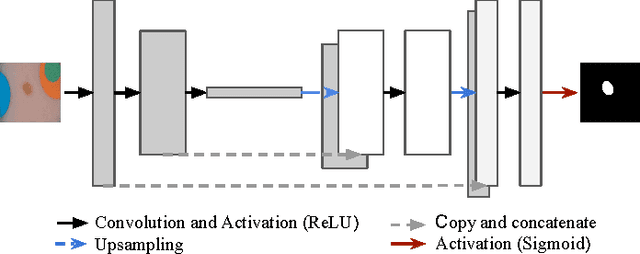
Dermoscopic skin images are often obtained with different imaging devices, under varying acquisition conditions. In this work, instead of attempting to perform intensity and color normalization, we propose to leverage computational color constancy techniques to build an artificial data augmentation technique suitable for this kind of images. Specifically, we apply the \emph{shades of gray} color constancy technique to color-normalize the entire training set of images, while retaining the estimated illuminants. We then draw one sample from the distribution of training set illuminants and apply it on the normalized image. We employ this technique for training two deep convolutional neural networks for the tasks of skin lesion segmentation and skin lesion classification, in the context of the ISIC 2017 challenge and without using any external dermatologic image set. Our results on the validation set are promising, and will be supplemented with extended results on the hidden test set when available.