 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum-Assisted Automatic Path-Planning for Robotic Quality Inspection in Industry 4.0
Jul 02, 2025This work explores the application of hybrid quantum-classical algorithms to optimize robotic inspection trajectories derived from Computer-Aided Design (CAD) models in industrial settings. By modeling the task as a 3D variant of the Traveling Salesman Problem, incorporating incomplete graphs and open-route constraints, this study evaluates the performance of two D-Wave-based solvers against classical methods such as GUROBI and Google OR-Tools. Results across five real-world cases demonstrate competitive solution quality with significantly reduced computation times, highlighting the potential of quantum approaches in automation under Industry 4.0.
MVMO: A Multi-Object Dataset for Wide Baseline Multi-View Semantic Segmentation
May 30, 2022
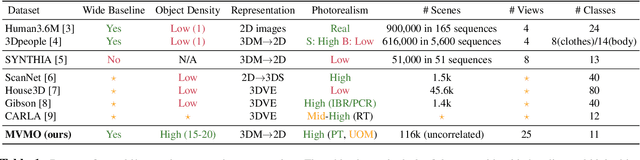


We present MVMO (Multi-View, Multi-Object dataset): a synthetic dataset of 116,000 scenes containing randomly placed objects of 10 distinct classes and captured from 25 camera locations in the upper hemisphere. MVMO comprises photorealistic, path-traced image renders, together with semantic segmentation ground truth for every view. Unlike existing multi-view datasets, MVMO features wide baselines between cameras and high density of objects, which lead to large disparities, heavy occlusions and view-dependent object appearance. Single view semantic segmentation is hindered by self and inter-object occlusions that could benefit from additional viewpoints. Therefore, we expect that MVMO will propel research in multi-view semantic segmentation and cross-view semantic transfer. We also provide baselines that show that new research is needed in such fields to exploit the complementary information of multi-view setups.
Self-supervised blur detection from synthetically blurred scenes
Aug 28, 2019
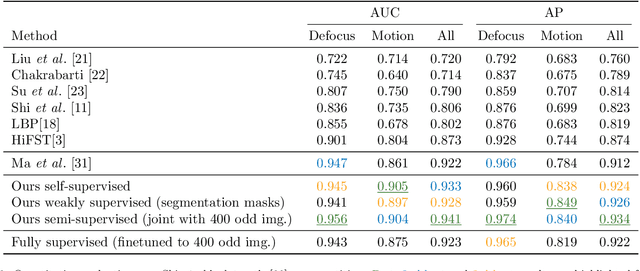


Blur detection aims at segmenting the blurred areas of a given image. Recent deep learning-based methods approach this problem by learning an end-to-end mapping between the blurred input and a binary mask representing the localization of its blurred areas. Nevertheless, the effectiveness of such deep models is limited due to the scarcity of datasets annotated in terms of blur segmentation, as blur annotation is labour intensive. In this work, we bypass the need for such annotated datasets for end-to-end learning, and instead rely on object proposals and a model for blur generation in order to produce a dataset of synthetically blurred images. This allows us to perform self-supervised learning over the generated image and ground truth blur mask pairs using CNNs, defining a framework that can be employed in purely self-supervised, weakly supervised or semi-supervised configurations. Interestingly, experimental results of such setups over the largest blur segmentation datasets available show that this approach achieves state of the art results in blur segmentation, even without ever observing any real blurred image.
Data-Driven Color Augmentation Techniques for Deep Skin Image Analysis
Mar 10, 2017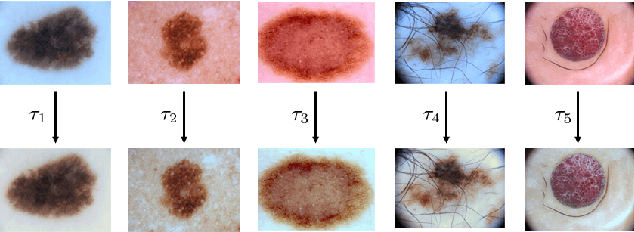
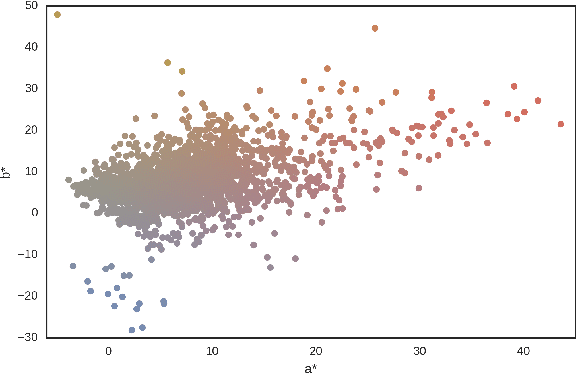

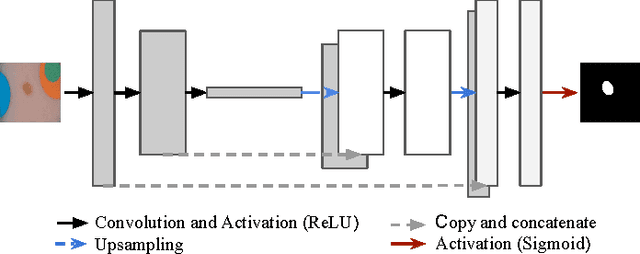
Dermoscopic skin images are often obtained with different imaging devices, under varying acquisition conditions. In this work, instead of attempting to perform intensity and color normalization, we propose to leverage computational color constancy techniques to build an artificial data augmentation technique suitable for this kind of images. Specifically, we apply the \emph{shades of gray} color constancy technique to color-normalize the entire training set of images, while retaining the estimated illuminants. We then draw one sample from the distribution of training set illuminants and apply it on the normalized image. We employ this technique for training two deep convolutional neural networks for the tasks of skin lesion segmentation and skin lesion classification, in the context of the ISIC 2017 challenge and without using any external dermatologic image set. Our results on the validation set are promising, and will be supplemented with extended results on the hidden test set when available.