 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHandling Missing Modalities in Multimodal Survival Prediction for Non-Small Cell Lung Cancer
Jan 15, 2026Accurate survival prediction in Non-Small Cell Lung Cancer (NSCLC) requires the integration of heterogeneous clinical, radiological, and histopathological information. While Multimodal Deep Learning (MDL) offers a promises for precision prognosis and survival prediction, its clinical applicability is severely limited by small cohort sizes and the presence of missing modalities, often forcing complete-case filtering or aggressive imputation. In this work, we present a missing-aware multimodal survival framework that integrates Computed Tomography (CT), Whole-Slide Histopathology (WSI) Images, and structured clinical variables for overall survival modeling in unresectable stage II-III NSCLC. By leveraging Foundation Models (FM) for modality-specific feature extraction and a missing-aware encoding strategy, the proposed approach enables intermediate multimodal fusion under naturally incomplete modality profiles. The proposed architecture is resilient to missing modalities by design, allowing the model to utilize all available data without being forced to drop patients during training or inference. Experimental results demonstrate that intermediate fusion consistently outperforms unimodal baselines as well as early and late fusion strategies, with the strongest performance achieved by the fusion of WSI and clinical modalities (73.30 C-index). Further analyses of modality importance reveal an adaptive behavior in which less informative modalities, i.e., CT modality, are automatically down-weighted and contribute less to the final survival prediction.
Latent Diffusion Autoencoders: Toward Efficient and Meaningful Unsupervised Representation Learning in Medical Imaging
Apr 11, 2025This study presents Latent Diffusion Autoencoder (LDAE), a novel encoder-decoder diffusion-based framework for efficient and meaningful unsupervised learning in medical imaging, focusing on Alzheimer disease (AD) using brain MR from the ADNI database as a case study. Unlike conventional diffusion autoencoders operating in image space, LDAE applies the diffusion process in a compressed latent representation, improving computational efficiency and making 3D medical imaging representation learning tractable. To validate the proposed approach, we explore two key hypotheses: (i) LDAE effectively captures meaningful semantic representations on 3D brain MR associated with AD and ageing, and (ii) LDAE achieves high-quality image generation and reconstruction while being computationally efficient. Experimental results support both hypotheses: (i) linear-probe evaluations demonstrate promising diagnostic performance for AD (ROC-AUC: 90%, ACC: 84%) and age prediction (MAE: 4.1 years, RMSE: 5.2 years); (ii) the learned semantic representations enable attribute manipulation, yielding anatomically plausible modifications; (iii) semantic interpolation experiments show strong reconstruction of missing scans, with SSIM of 0.969 (MSE: 0.0019) for a 6-month gap. Even for longer gaps (24 months), the model maintains robust performance (SSIM > 0.93, MSE < 0.004), indicating an ability to capture temporal progression trends; (iv) compared to conventional diffusion autoencoders, LDAE significantly increases inference throughput (20x faster) while also enhancing reconstruction quality. These findings position LDAE as a promising framework for scalable medical imaging applications, with the potential to serve as a foundation model for medical image analysis. Code available at https://github.com/GabrieleLozupone/LDAE
AXIAL: Attention-based eXplainability for Interpretable Alzheimer's Localized Diagnosis using 2D CNNs on 3D MRI brain scans
Jul 02, 2024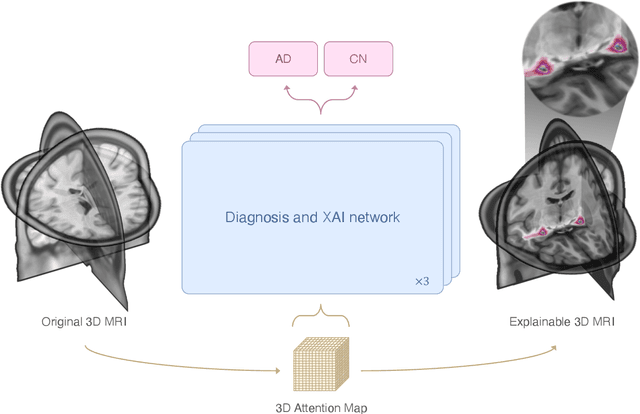
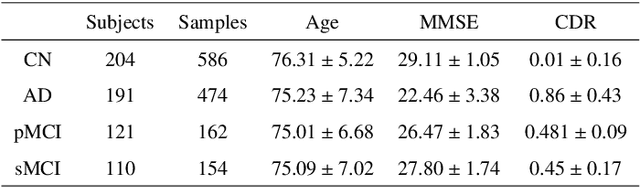
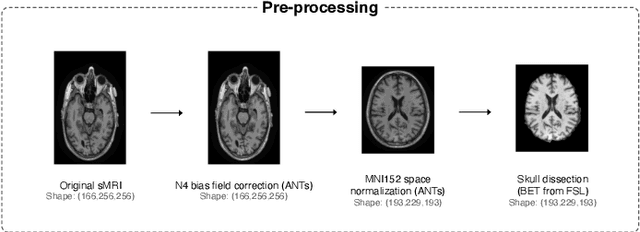
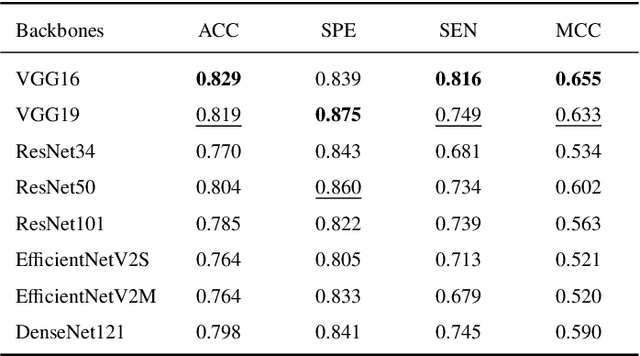
This study presents an innovative method for Alzheimer's disease diagnosis using 3D MRI designed to enhance the explainability of model decisions. Our approach adopts a soft attention mechanism, enabling 2D CNNs to extract volumetric representations. At the same time, the importance of each slice in decision-making is learned, allowing the generation of a voxel-level attention map to produces an explainable MRI. To test our method and ensure the reproducibility of our results, we chose a standardized collection of MRI data from the Alzheimer's Disease Neuroimaging Initiative (ADNI). On this dataset, our method significantly outperforms state-of-the-art methods in (i) distinguishing AD from cognitive normal (CN) with an accuracy of 0.856 and Matthew's correlation coefficient (MCC) of 0.712, representing improvements of 2.4\% and 5.3\% respectively over the second-best, and (ii) in the prognostic task of discerning stable from progressive mild cognitive impairment (MCI) with an accuracy of 0.725 and MCC of 0.443, showing improvements of 10.2\% and 20.5\% respectively over the second-best. We achieved this prognostic result by adopting a double transfer learning strategy, which enhanced sensitivity to morphological changes and facilitated early-stage AD detection. With voxel-level precision, our method identified which specific areas are being paid attention to, identifying these predominant brain regions: the \emph{hippocampus}, the \emph{amygdala}, the \emph{parahippocampal}, and the \emph{inferior lateral ventricles}. All these areas are clinically associated with AD development. Furthermore, our approach consistently found the same AD-related areas across different cross-validation folds, proving its robustness and precision in highlighting areas that align closely with known pathological markers of the disease.
On the Cross-Dataset Generalization of Machine Learning for Network Intrusion Detection
Feb 15, 2024Network Intrusion Detection Systems (NIDS) are a fundamental tool in cybersecurity. Their ability to generalize across diverse networks is a critical factor in their effectiveness and a prerequisite for real-world applications. In this study, we conduct a comprehensive analysis on the generalization of machine-learning-based NIDS through an extensive experimentation in a cross-dataset framework. We employ four machine learning classifiers and utilize four datasets acquired from different networks: CIC-IDS-2017, CSE-CIC-IDS2018, LycoS-IDS2017, and LycoS-Unicas-IDS2018. Notably, the last dataset is a novel contribution, where we apply corrections based on LycoS-IDS2017 to the well-known CSE-CIC-IDS2018 dataset. The results show nearly perfect classification performance when the models are trained and tested on the same dataset. However, when training and testing the models in a cross-dataset fashion, the classification accuracy is largely commensurate with random chance except for a few combinations of attacks and datasets. We employ data visualization techniques in order to provide valuable insights on the patterns in the data. Our analysis unveils the presence of anomalies in the data that directly hinder the classifiers capability to generalize the learned knowledge to new scenarios. This study enhances our comprehension of the generalization capabilities of machine-learning-based NIDS, highlighting the significance of acknowledging data heterogeneity.
Gravity Network for end-to-end small lesion detection
Sep 22, 2023



This paper introduces a novel one-stage end-to-end detector specifically designed to detect small lesions in medical images. Precise localization of small lesions presents challenges due to their appearance and the diverse contextual backgrounds in which they are found. To address this, our approach introduces a new type of pixel-based anchor that dynamically moves towards the targeted lesion for detection. We refer to this new architecture as GravityNet, and the novel anchors as gravity points since they appear to be "attracted" by the lesions. We conducted experiments on two well-established medical problems involving small lesions to evaluate the performance of the proposed approach: microcalcifications detection in digital mammograms and microaneurysms detection in digital fundus images. Our method demonstrates promising results in effectively detecting small lesions in these medical imaging tasks.
Seamless Iterative Semi-Supervised Correction of Imperfect Labels in Microscopy Images
Aug 05, 2022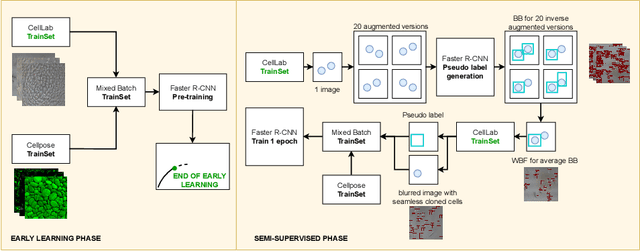
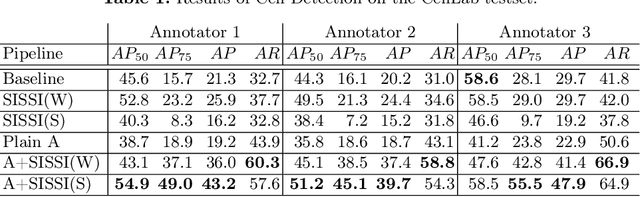
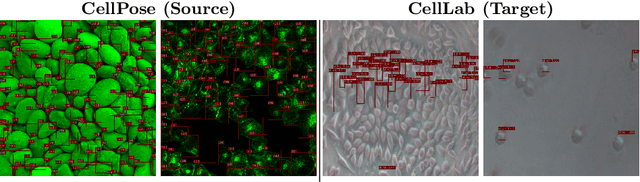

In-vitro tests are an alternative to animal testing for the toxicity of medical devices. Detecting cells as a first step, a cell expert evaluates the growth of cells according to cytotoxicity grade under the microscope. Thus, human fatigue plays a role in error making, making the use of deep learning appealing. Due to the high cost of training data annotation, an approach without manual annotation is needed. We propose Seamless Iterative Semi-Supervised correction of Imperfect labels (SISSI), a new method for training object detection models with noisy and missing annotations in a semi-supervised fashion. Our network learns from noisy labels generated with simple image processing algorithms, which are iteratively corrected during self-training. Due to the nature of missing bounding boxes in the pseudo labels, which would negatively affect the training, we propose to train on dynamically generated synthetic-like images using seamless cloning. Our method successfully provides an adaptive early learning correction technique for object detection. The combination of early learning correction that has been applied in classification and semantic segmentation before and synthetic-like image generation proves to be more effective than the usual semi-supervised approach by > 15% AP and > 20% AR across three different readers. Our code is available at https://github.com/marwankefah/SISSI.
Sinc-based convolutional neural networks for EEG-BCI-based motor imagery classification
Jan 19, 2021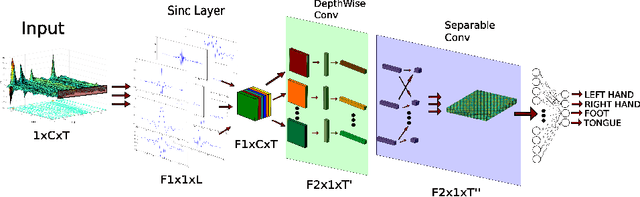

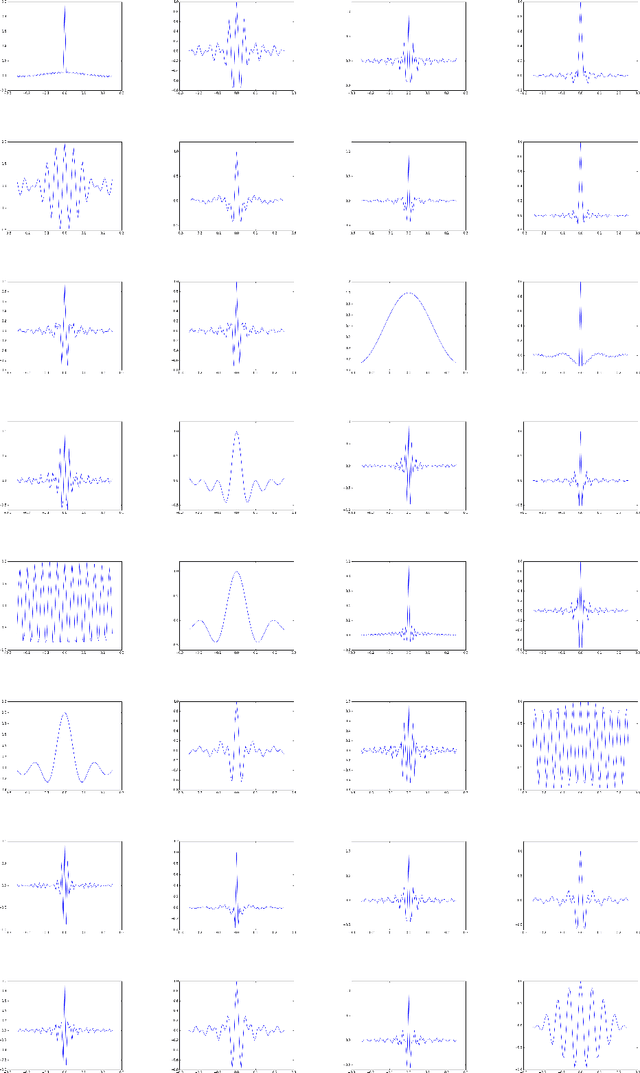
Brain-Computer Interfaces (BCI) based on motor imagery translate mental motor images recognized from the electroencephalogram (EEG) to control commands. EEG patterns of different imagination tasks, e.g. hand and foot movements, are effectively classified with machine learning techniques using band power features. Recently, also Convolutional Neural Networks (CNNs) that learn both effective features and classifiers simultaneously from raw EEG data have been applied. However, CNNs have two major drawbacks: (i) they have a very large number of parameters, which thus requires a very large number of training examples; and (ii) they are not designed to explicitly learn features in the frequency domain. To overcome these limitations, in this work we introduce Sinc-EEGNet, a lightweight CNN architecture that combines learnable band-pass and depthwise convolutional filters. Experimental results obtained on the publicly available BCI Competition IV Dataset 2a show that our approach outperforms reference methods in terms of classification accuracy.
On the Duality Between Retinex and Image Dehazing
Apr 06, 2018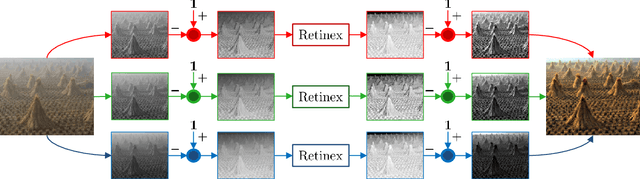

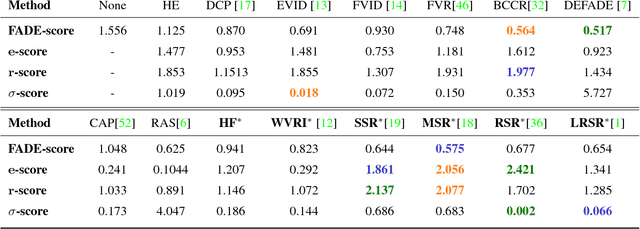
Image dehazing deals with the removal of undesired loss of visibility in outdoor images due to the presence of fog. Retinex is a color vision model mimicking the ability of the Human Visual System to robustly discount varying illuminations when observing a scene under different spectral lighting conditions. Retinex has been widely explored in the computer vision literature for image enhancement and other related tasks. While these two problems are apparently unrelated, the goal of this work is to show that they can be connected by a simple linear relationship. Specifically, most Retinex-based algorithms have the characteristic feature of always increasing image brightness, which turns them into ideal candidates for effective image dehazing by directly applying Retinex to a hazy image whose intensities have been inverted. In this paper, we give theoretical proof that Retinex on inverted intensities is a solution to the image dehazing problem. Comprehensive qualitative and quantitative results indicate that several classical and modern implementations of Retinex can be transformed into competing image dehazing algorithms performing on pair with more complex fog removal methods, and can overcome some of the main challenges associated with this problem.