 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdvancing Surgical VQA with Scene Graph Knowledge
Dec 15, 2023Modern operating room is becoming increasingly complex, requiring innovative intra-operative support systems. While the focus of surgical data science has largely been on video analysis, integrating surgical computer vision with language capabilities is emerging as a necessity. Our work aims to advance Visual Question Answering (VQA) in the surgical context with scene graph knowledge, addressing two main challenges in the current surgical VQA systems: removing question-condition bias in the surgical VQA dataset and incorporating scene-aware reasoning in the surgical VQA model design. First, we propose a Surgical Scene Graph-based dataset, SSG-QA, generated by employing segmentation and detection models on publicly available datasets. We build surgical scene graphs using spatial and action information of instruments and anatomies. These graphs are fed into a question engine, generating diverse QA pairs. Our SSG-QA dataset provides a more complex, diverse, geometrically grounded, unbiased, and surgical action-oriented dataset compared to existing surgical VQA datasets. We then propose SSG-QA-Net, a novel surgical VQA model incorporating a lightweight Scene-embedded Interaction Module (SIM), which integrates geometric scene knowledge in the VQA model design by employing cross-attention between the textual and the scene features. Our comprehensive analysis of the SSG-QA dataset shows that SSG-QA-Net outperforms existing methods across different question types and complexities. We highlight that the primary limitation in the current surgical VQA systems is the lack of scene knowledge to answer complex queries. We present a novel surgical VQA dataset and model and show that results can be significantly improved by incorporating geometric scene features in the VQA model design. The source code and the dataset will be made publicly available at: https://github.com/CAMMA-public/SSG-QA
Seamless Iterative Semi-Supervised Correction of Imperfect Labels in Microscopy Images
Aug 05, 2022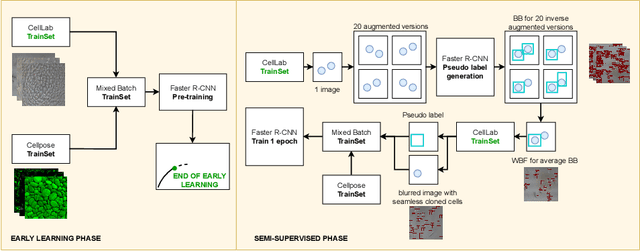
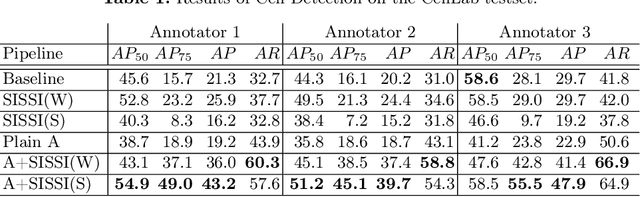
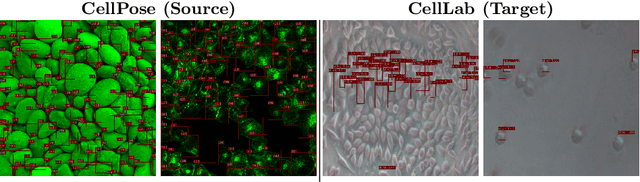

In-vitro tests are an alternative to animal testing for the toxicity of medical devices. Detecting cells as a first step, a cell expert evaluates the growth of cells according to cytotoxicity grade under the microscope. Thus, human fatigue plays a role in error making, making the use of deep learning appealing. Due to the high cost of training data annotation, an approach without manual annotation is needed. We propose Seamless Iterative Semi-Supervised correction of Imperfect labels (SISSI), a new method for training object detection models with noisy and missing annotations in a semi-supervised fashion. Our network learns from noisy labels generated with simple image processing algorithms, which are iteratively corrected during self-training. Due to the nature of missing bounding boxes in the pseudo labels, which would negatively affect the training, we propose to train on dynamically generated synthetic-like images using seamless cloning. Our method successfully provides an adaptive early learning correction technique for object detection. The combination of early learning correction that has been applied in classification and semantic segmentation before and synthetic-like image generation proves to be more effective than the usual semi-supervised approach by > 15% AP and > 20% AR across three different readers. Our code is available at https://github.com/marwankefah/SISSI.