 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-Aware Mapping from 3D Keypoints to Anatomical Landmarks for Markerless Biomechanics
Mar 27, 2026Markerless biomechanics increasingly relies on 3D skeletal keypoints extracted from video, yet downstream biomechanical mappings typically treat these estimates as deterministic, providing no principled mechanism for frame-wise quality control. In this work, we investigate predictive uncertainty as a quantitative measure of confidence for mapping 3D pose keypoints to 3D anatomical landmarks, a critical step preceding inverse kinematics and musculoskeletal analysis. Within a temporal learning framework, we model both uncertainty arising from observation noise and uncertainty related to model limitations. Using synchronized motion capture ground truth on AMASS, we evaluate uncertainty at frame and joint level through error--uncertainty rank correlation, risk--coverage analysis, and catastrophic outlier detection. Across experiments, uncertainty estimates, particularly those associated with model uncertainty, exhibit a strong monotonic association with landmark error (Spearman $ρ\approx 0.63$), enabling selective retention of reliable frames (error reduced to $\approx 16.8$ mm at 10% coverage) and accurate detection of severe failures (ROC-AUC $\approx 0.92$ for errors $>50$ mm). Reliability ranking remains stable under controlled input degradation, including Gaussian noise and simulated missing joints. In contrast, uncertainty attributable to observation noise provides limited additional benefit in this setting, suggesting that dominant failures in keypoint-to-landmark mapping are driven primarily by model uncertainty. Our results establish predictive uncertainty as a practical, frame-wise tool for automatic quality control in markerless biomechanical pipelines.
Character Detection using YOLO for Writer Identification in multiple Medieval books
Jan 08, 2026Paleography is the study of ancient and historical handwriting, its key objectives include the dating of manuscripts and understanding the evolution of writing. Estimating when a document was written and tracing the development of scripts and writing styles can be aided by identifying the individual scribes who contributed to a medieval manuscript. Although digital technologies have made significant progress in this field, the general problem remains unsolved and continues to pose open challenges. ... We previously proposed an approach focused on identifying specific letters or abbreviations that characterize each writer. In that study, we considered the letter "a", as it was widely present on all pages of text and highly distinctive, according to the suggestions of expert paleographers. We used template matching techniques to detect the occurrences of the character "a" on each page and the convolutional neural network (CNN) to attribute each instance to the correct scribe. Moving from the interesting results achieved from this previous system and being aware of the limitations of the template matching technique, which requires an appropriate threshold to work, we decided to experiment in the same framework with the use of the YOLO object detection model to identify the scribe who contributed to the writing of different medieval books. We considered the fifth version of YOLO to implement the YOLO object detection model, which completely substituted the template matching and CNN used in the previous work. The experimental results demonstrate that YOLO effectively extracts a greater number of letters considered, leading to a more accurate second-stage classification. Furthermore, the YOLO confidence score provides a foundation for developing a system that applies a rejection threshold, enabling reliable writer identification even in unseen manuscripts.
Latent Diffusion Autoencoders: Toward Efficient and Meaningful Unsupervised Representation Learning in Medical Imaging
Apr 11, 2025This study presents Latent Diffusion Autoencoder (LDAE), a novel encoder-decoder diffusion-based framework for efficient and meaningful unsupervised learning in medical imaging, focusing on Alzheimer disease (AD) using brain MR from the ADNI database as a case study. Unlike conventional diffusion autoencoders operating in image space, LDAE applies the diffusion process in a compressed latent representation, improving computational efficiency and making 3D medical imaging representation learning tractable. To validate the proposed approach, we explore two key hypotheses: (i) LDAE effectively captures meaningful semantic representations on 3D brain MR associated with AD and ageing, and (ii) LDAE achieves high-quality image generation and reconstruction while being computationally efficient. Experimental results support both hypotheses: (i) linear-probe evaluations demonstrate promising diagnostic performance for AD (ROC-AUC: 90%, ACC: 84%) and age prediction (MAE: 4.1 years, RMSE: 5.2 years); (ii) the learned semantic representations enable attribute manipulation, yielding anatomically plausible modifications; (iii) semantic interpolation experiments show strong reconstruction of missing scans, with SSIM of 0.969 (MSE: 0.0019) for a 6-month gap. Even for longer gaps (24 months), the model maintains robust performance (SSIM > 0.93, MSE < 0.004), indicating an ability to capture temporal progression trends; (iv) compared to conventional diffusion autoencoders, LDAE significantly increases inference throughput (20x faster) while also enhancing reconstruction quality. These findings position LDAE as a promising framework for scalable medical imaging applications, with the potential to serve as a foundation model for medical image analysis. Code available at https://github.com/GabrieleLozupone/LDAE
Poseidon: A ViT-based Architecture for Multi-Frame Pose Estimation with Adaptive Frame Weighting and Multi-Scale Feature Fusion
Jan 14, 2025Human pose estimation, a vital task in computer vision, involves detecting and localising human joints in images and videos. While single-frame pose estimation has seen significant progress, it often fails to capture the temporal dynamics for understanding complex, continuous movements. We propose Poseidon, a novel multi-frame pose estimation architecture that extends the ViTPose model by integrating temporal information for enhanced accuracy and robustness to address these limitations. Poseidon introduces key innovations: (1) an Adaptive Frame Weighting (AFW) mechanism that dynamically prioritises frames based on their relevance, ensuring that the model focuses on the most informative data; (2) a Multi-Scale Feature Fusion (MSFF) module that aggregates features from different backbone layers to capture both fine-grained details and high-level semantics; and (3) a Cross-Attention module for effective information exchange between central and contextual frames, enhancing the model's temporal coherence. The proposed architecture improves performance in complex video scenarios and offers scalability and computational efficiency suitable for real-world applications. Our approach achieves state-of-the-art performance on the PoseTrack21 and PoseTrack18 datasets, achieving mAP scores of 88.3 and 87.8, respectively, outperforming existing methods.
AXIAL: Attention-based eXplainability for Interpretable Alzheimer's Localized Diagnosis using 2D CNNs on 3D MRI brain scans
Jul 02, 2024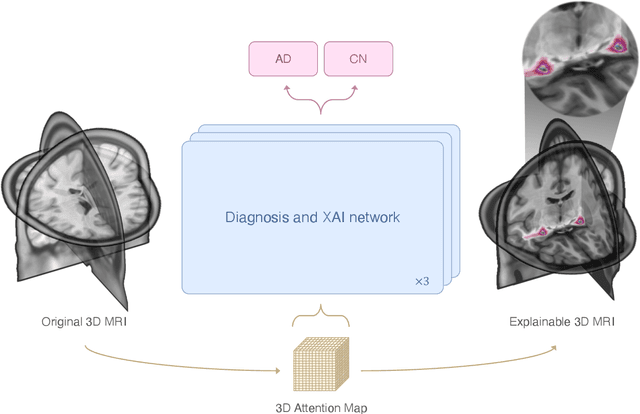
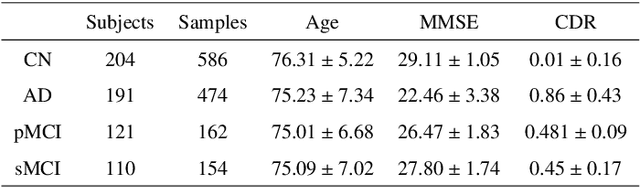
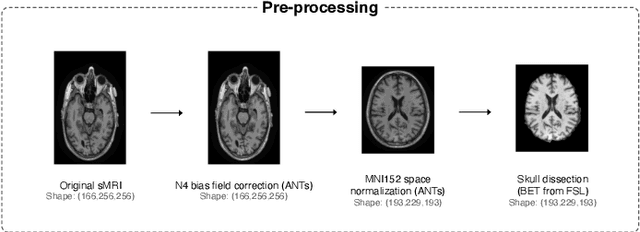
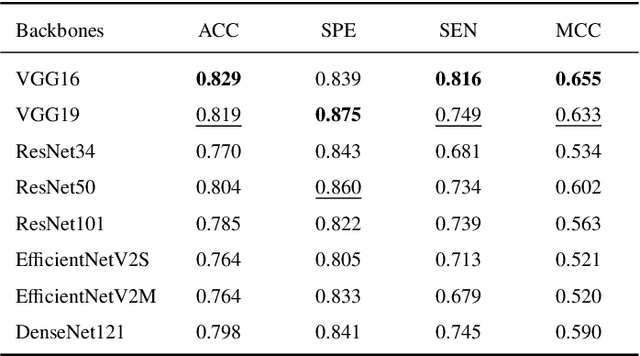
This study presents an innovative method for Alzheimer's disease diagnosis using 3D MRI designed to enhance the explainability of model decisions. Our approach adopts a soft attention mechanism, enabling 2D CNNs to extract volumetric representations. At the same time, the importance of each slice in decision-making is learned, allowing the generation of a voxel-level attention map to produces an explainable MRI. To test our method and ensure the reproducibility of our results, we chose a standardized collection of MRI data from the Alzheimer's Disease Neuroimaging Initiative (ADNI). On this dataset, our method significantly outperforms state-of-the-art methods in (i) distinguishing AD from cognitive normal (CN) with an accuracy of 0.856 and Matthew's correlation coefficient (MCC) of 0.712, representing improvements of 2.4\% and 5.3\% respectively over the second-best, and (ii) in the prognostic task of discerning stable from progressive mild cognitive impairment (MCI) with an accuracy of 0.725 and MCC of 0.443, showing improvements of 10.2\% and 20.5\% respectively over the second-best. We achieved this prognostic result by adopting a double transfer learning strategy, which enhanced sensitivity to morphological changes and facilitated early-stage AD detection. With voxel-level precision, our method identified which specific areas are being paid attention to, identifying these predominant brain regions: the \emph{hippocampus}, the \emph{amygdala}, the \emph{parahippocampal}, and the \emph{inferior lateral ventricles}. All these areas are clinically associated with AD development. Furthermore, our approach consistently found the same AD-related areas across different cross-validation folds, proving its robustness and precision in highlighting areas that align closely with known pathological markers of the disease.
A Machine Learning Approach to Analyze the Effects of Alzheimer's Disease on Handwriting through Lognormal Features
May 27, 2024Alzheimer's disease is one of the most incisive illnesses among the neurodegenerative ones, and it causes a progressive decline in cognitive abilities that, in the worst cases, becomes severe enough to interfere with daily life. Currently, there is no cure, so an early diagnosis is strongly needed to try and slow its progression through medical treatments. Handwriting analysis is considered a potential tool for detecting and understanding certain neurological conditions, including Alzheimer's disease. While handwriting analysis alone cannot provide a definitive diagnosis of Alzheimer's, it may offer some insights and be used for a comprehensive assessment. The Sigma-lognormal model is conceived for movement analysis and can also be applied to handwriting. This model returns a set of lognormal parameters as output, which forms the basis for the computation of novel and significant features. This paper presents a machine learning approach applied to handwriting features extracted through the sigma-lognormal model. The aim is to develop a support system to help doctors in the diagnosis and study of Alzheimer, evaluate the effectiveness of the extracted features and finally study the relation among them.
How word semantics and phonology affect handwriting of Alzheimer's patients: a machine learning based analysis
Jul 06, 2023Using kinematic properties of handwriting to support the diagnosis of neurodegenerative disease is a real challenge: non-invasive detection techniques combined with machine learning approaches promise big steps forward in this research field. In literature, the tasks proposed focused on different cognitive skills to elicitate handwriting movements. In particular, the meaning and phonology of words to copy can compromise writing fluency. In this paper, we investigated how word semantics and phonology affect the handwriting of people affected by Alzheimer's disease. To this aim, we used the data from six handwriting tasks, each requiring copying a word belonging to one of the following categories: regular (have a predictable phoneme-grapheme correspondence, e.g., cat), non-regular (have atypical phoneme-grapheme correspondence, e.g., laugh), and non-word (non-meaningful pronounceable letter strings that conform to phoneme-grapheme conversion rules). We analyzed the data using a machine learning approach by implementing four well-known and widely-used classifiers and feature selection. The experimental results showed that the feature selection allowed us to derive a different set of highly distinctive features for each word type. Furthermore, non-regular words needed, on average, more features but achieved excellent classification performance: the best result was obtained on a non-regular, reaching an accuracy close to 90%.