 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAthena 2.0: Discourse and User Modeling in Open Domain Dialogue
Aug 03, 2023



Conversational agents are consistently growing in popularity and many people interact with them every day. While many conversational agents act as personal assistants, they can have many different goals. Some are task-oriented, such as providing customer support for a bank or making a reservation. Others are designed to be empathetic and to form emotional connections with the user. The Alexa Prize Challenge aims to create a socialbot, which allows the user to engage in coherent conversations, on a range of popular topics that will interest the user. Here we describe Athena 2.0, UCSC's conversational agent for Amazon's Socialbot Grand Challenge 4. Athena 2.0 utilizes a novel knowledge-grounded discourse model that tracks the entity links that Athena introduces into the dialogue, and uses them to constrain named-entity recognition and linking, and coreference resolution. Athena 2.0 also relies on a user model to personalize topic selection and other aspects of the conversation to individual users.
Athena 2.0: Contextualized Dialogue Management for an Alexa Prize SocialBot
Nov 03, 2021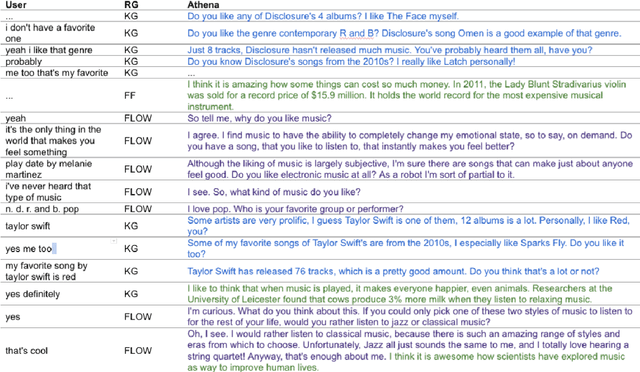

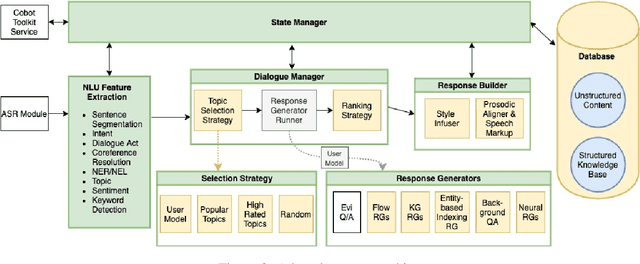
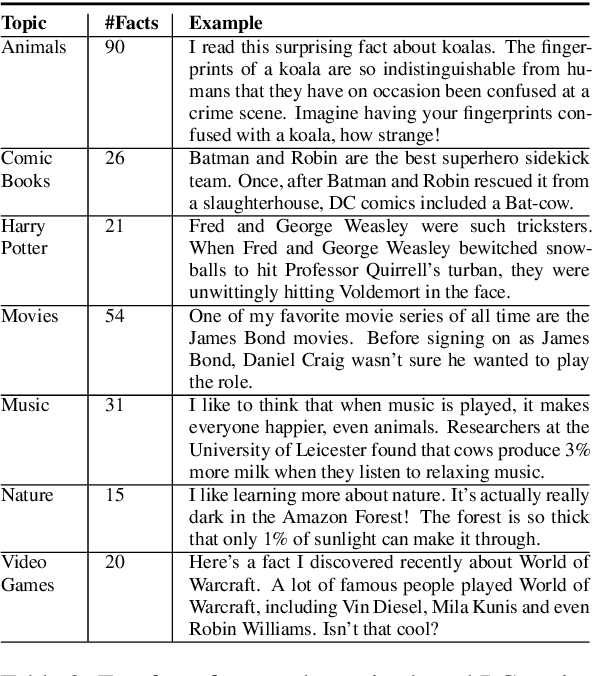
Athena 2.0 is an Alexa Prize SocialBot that has been a finalist in the last two Alexa Prize Grand Challenges. One reason for Athena's success is its novel dialogue management strategy, which allows it to dynamically construct dialogues and responses from component modules, leading to novel conversations with every interaction. Here we describe Athena's system design and performance in the Alexa Prize during the 20/21 competition. A live demo of Athena as well as video recordings will provoke discussion on the state of the art in conversational AI.
MBA: Mini-Batch AUC Optimization
May 31, 2018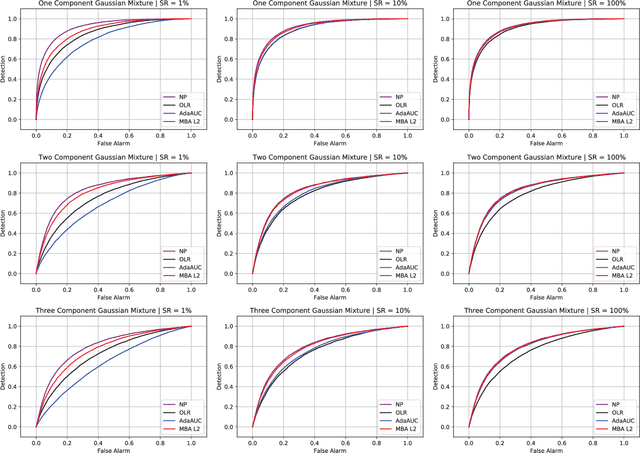
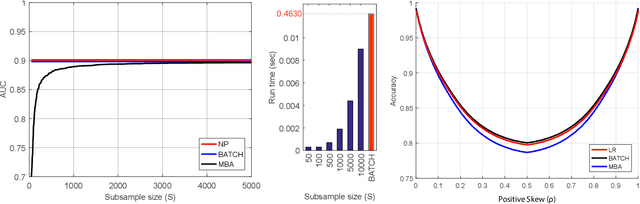
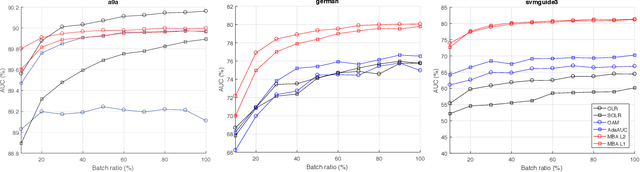
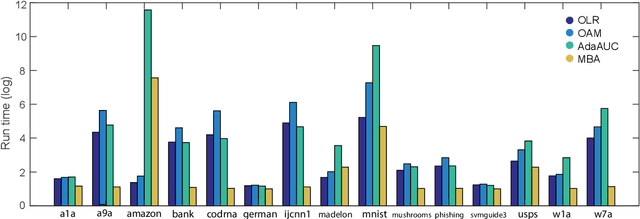
Area under the receiver operating characteristics curve (AUC) is an important metric for a wide range of signal processing and machine learning problems, and scalable methods for optimizing AUC have recently been proposed. However, handling very large datasets remains an open challenge for this problem. This paper proposes a novel approach to AUC maximization, based on sampling mini-batches of positive/negative instance pairs and computing U-statistics to approximate a global risk minimization problem. The resulting algorithm is simple, fast, and learning-rate free. We show that the number of samples required for good performance is independent of the number of pairs available, which is a quadratic function of the positive and negative instances. Extensive experiments show the practical utility of the proposed method.
Modeling informational novelty in a conversational system with a hybrid statistical and grammar-based approach to natural language generation
Jun 21, 2001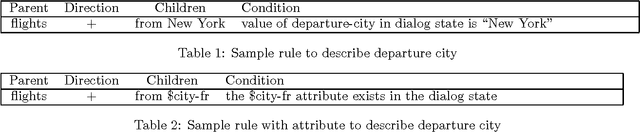
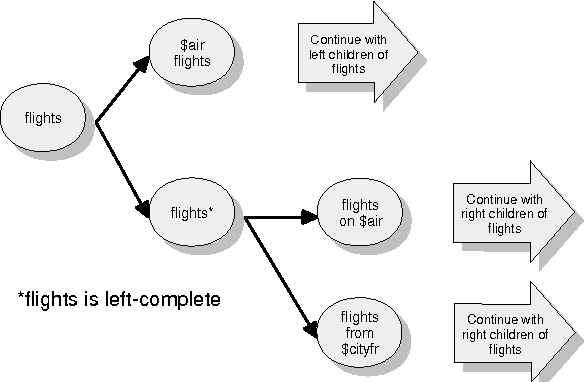

We present a hybrid statistical and grammar-based system for surface natural language generation (NLG) that uses grammar rules, conditions on using those grammar rules, and corpus statistics to determine the word order. We also describe how this surface NLG module is implemented in a prototype conversational system, and how it attempts to model informational novelty by varying the word order. Using a combination of rules and statistical information, the conversational system expresses the novel information differently than the given information, based on the run-time dialog state. We also discuss our plans for evaluating the generation strategy.
Trainable Methods for Surface Natural Language Generation
Jun 13, 2000



We present three systems for surface natural language generation that are trainable from annotated corpora. The first two systems, called NLG1 and NLG2, require a corpus marked only with domain-specific semantic attributes, while the last system, called NLG3, requires a corpus marked with both semantic attributes and syntactic dependency information. All systems attempt to produce a grammatical natural language phrase from a domain-specific semantic representation. NLG1 serves a baseline system and uses phrase frequencies to generate a whole phrase in one step, while NLG2 and NLG3 use maximum entropy probability models to individually generate each word in the phrase. The systems NLG2 and NLG3 learn to determine both the word choice and the word order of the phrase. We present experiments in which we generate phrases to describe flights in the air travel domain.
* LaTeX, 8 pages
Statistical Models for Unsupervised Prepositional Phrase Attachment
Jul 22, 1998

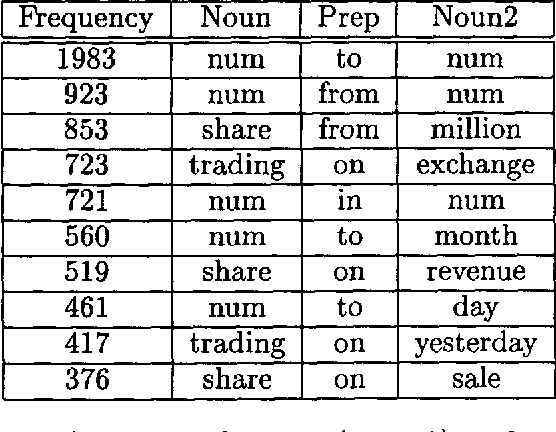
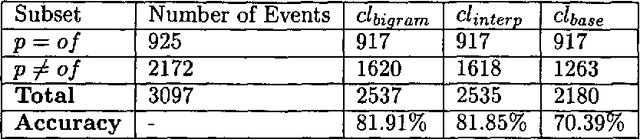
We present several unsupervised statistical models for the prepositional phrase attachment task that approach the accuracy of the best supervised methods for this task. Our unsupervised approach uses a heuristic based on attachment proximity and trains from raw text that is annotated with only part-of-speech tags and morphological base forms, as opposed to attachment information. It is therefore less resource-intensive and more portable than previous corpus-based algorithms proposed for this task. We present results for prepositional phrase attachment in both English and Spanish.
* uses colacl.sty
A Linear Observed Time Statistical Parser Based on Maximum Entropy Models
Jun 11, 1997
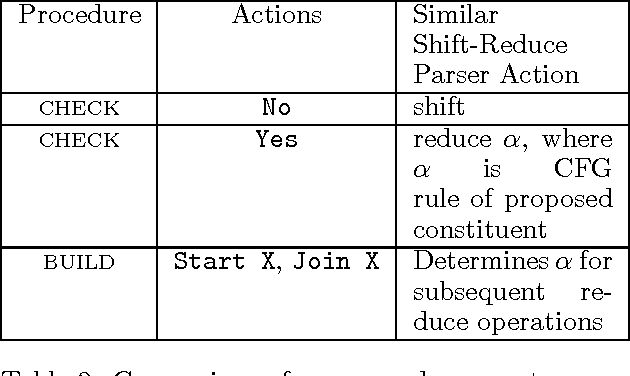

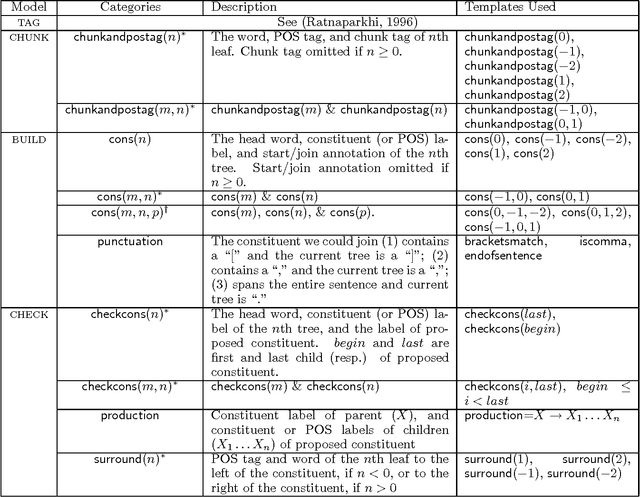
This paper presents a statistical parser for natural language that obtains a parsing accuracy---roughly 87% precision and 86% recall---which surpasses the best previously published results on the Wall St. Journal domain. The parser itself requires very little human intervention, since the information it uses to make parsing decisions is specified in a concise and simple manner, and is combined in a fully automatic way under the maximum entropy framework. The observed running time of the parser on a test sentence is linear with respect to the sentence length. Furthermore, the parser returns several scored parses for a sentence, and this paper shows that a scheme to pick the best parse from the 20 highest scoring parses could yield a dramatically higher accuracy of 93% precision and recall.
A Maximum Entropy Approach to Identifying Sentence Boundaries
Apr 09, 1997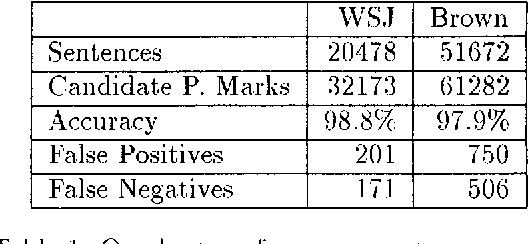
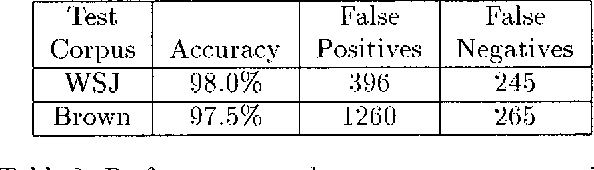

We present a trainable model for identifying sentence boundaries in raw text. Given a corpus annotated with sentence boundaries, our model learns to classify each occurrence of ., ?, and ! as either a valid or invalid sentence boundary. The training procedure requires no hand-crafted rules, lexica, part-of-speech tags, or domain-specific information. The model can therefore be trained easily on any genre of English, and should be trainable on any other Roman-alphabet language. Performance is comparable to or better than the performance of similar systems, but we emphasize the simplicity of retraining for new domains.
* 4 pages, uses aclap.sty and covingtn.sty