Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Maximum Entropy Approach to Identifying Sentence Boundaries
Paper and Code
Apr 09, 1997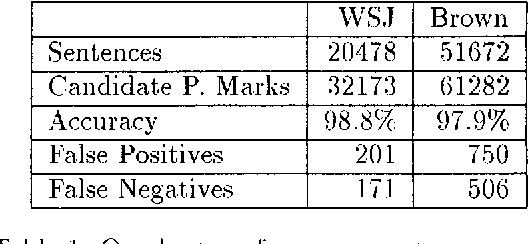
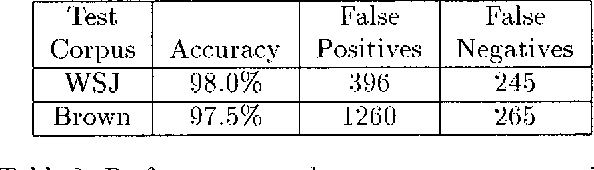

We present a trainable model for identifying sentence boundaries in raw text. Given a corpus annotated with sentence boundaries, our model learns to classify each occurrence of ., ?, and ! as either a valid or invalid sentence boundary. The training procedure requires no hand-crafted rules, lexica, part-of-speech tags, or domain-specific information. The model can therefore be trained easily on any genre of English, and should be trainable on any other Roman-alphabet language. Performance is comparable to or better than the performance of similar systems, but we emphasize the simplicity of retraining for new domains.
* Proceedings of the 5th ANLP Conference, 1997 * 4 pages, uses aclap.sty and covingtn.sty
View paper on