 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Maximum Entropy Approach to Identifying Sentence Boundaries
Apr 09, 1997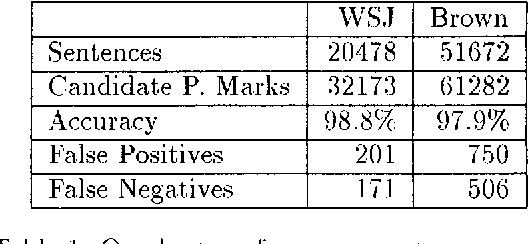
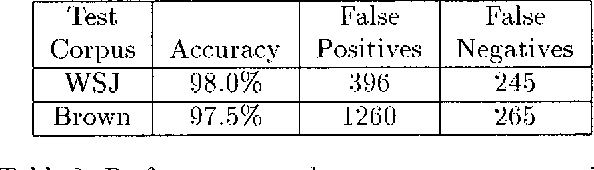

We present a trainable model for identifying sentence boundaries in raw text. Given a corpus annotated with sentence boundaries, our model learns to classify each occurrence of ., ?, and ! as either a valid or invalid sentence boundary. The training procedure requires no hand-crafted rules, lexica, part-of-speech tags, or domain-specific information. The model can therefore be trained easily on any genre of English, and should be trainable on any other Roman-alphabet language. Performance is comparable to or better than the performance of similar systems, but we emphasize the simplicity of retraining for new domains.
* 4 pages, uses aclap.sty and covingtn.sty
An Automatic Method of Finding Topic Boundaries
Jun 07, 1994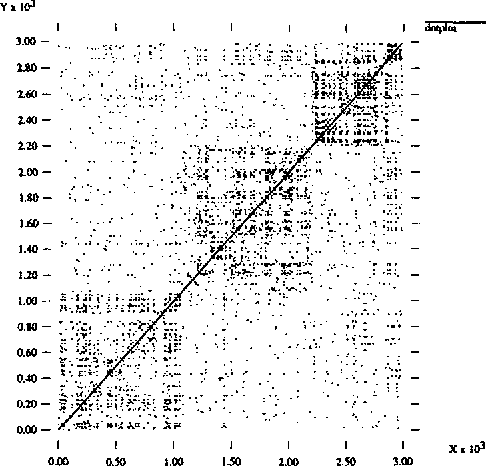
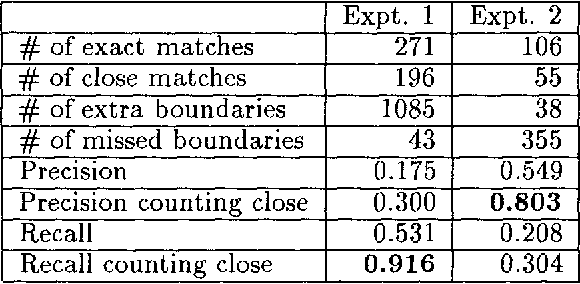
This article outlines a new method of locating discourse boundaries based on lexical cohesion and a graphical technique called dotplotting. The application of dotplotting to discourse segmentation can be performed either manually, by examining a graph, or automatically, using an optimization algorithm. The results of two experiments involving automatically locating boundaries between a series of concatenated documents are presented. Areas of application and future directions for this work are also outlined.