Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeStatistical Models for Unsupervised Prepositional Phrase Attachment
Paper and Code
Jul 22, 1998

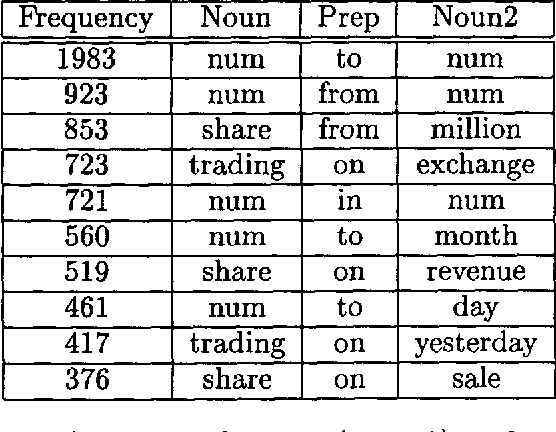
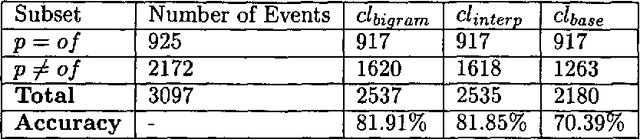
We present several unsupervised statistical models for the prepositional phrase attachment task that approach the accuracy of the best supervised methods for this task. Our unsupervised approach uses a heuristic based on attachment proximity and trains from raw text that is annotated with only part-of-speech tags and morphological base forms, as opposed to attachment information. It is therefore less resource-intensive and more portable than previous corpus-based algorithms proposed for this task. We present results for prepositional phrase attachment in both English and Spanish.
* Proceedings of the 17th International Conference on Computational
Linguistics (COLING-ACL '98) * uses colacl.sty
View paper on