 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReal-Time Diagnostic Integrity Meets Efficiency: A Novel Platform-Agnostic Architecture for Physiological Signal Compression
Jan 04, 2024Head-based signals such as EEG, EMG, EOG, and ECG collected by wearable systems will play a pivotal role in clinical diagnosis, monitoring, and treatment of important brain disorder diseases. However, the real-time transmission of the significant corpus physiological signals over extended periods consumes substantial power and time, limiting the viability of battery-dependent physiological monitoring wearables. This paper presents a novel deep-learning framework employing a variational autoencoder (VAE) for physiological signal compression to reduce wearables' computational complexity and energy consumption. Our approach achieves an impressive compression ratio of 1:293 specifically for spectrogram data, surpassing state-of-the-art compression techniques such as JPEG2000, H.264, Direct Cosine Transform (DCT), and Huffman Encoding, which do not excel in handling physiological signals. We validate the efficacy of the compressed algorithms using collected physiological signals from real patients in the Hospital and deploy the solution on commonly used embedded AI chips (i.e., ARM Cortex V8 and Jetson Nano). The proposed framework achieves a 91% seizure detection accuracy using XGBoost, confirming the approach's reliability, practicality, and scalability.
An Unobtrusive and Lightweight Ear-worn System for Continuous Epileptic Seizure Detection
Jan 01, 2024Epilepsy is one of the most common neurological diseases globally, affecting around 50 million people worldwide. Fortunately, up to 70 percent of people with epilepsy could live seizure-free if properly diagnosed and treated, and a reliable technique to monitor the onset of seizures could improve the quality of life of patients who are constantly facing the fear of random seizure attacks. The scalp-based EEG test, despite being the gold standard for diagnosing epilepsy, is costly, necessitates hospitalization, demands skilled professionals for operation, and is discomforting for users. In this paper, we propose EarSD, a novel lightweight, unobtrusive, and socially acceptable ear-worn system to detect epileptic seizure onsets by measuring the physiological signals from behind the user's ears. EarSD includes an integrated custom-built sensing, computing, and communication PCB to collect and amplify the signals of interest, remove the noises caused by motion artifacts and environmental impacts, and stream the data wirelessly to the computer or mobile phone nearby, where data are uploaded to the host computer for further processing. We conducted both in-lab and in-hospital experiments with epileptic seizure patients who were hospitalized for seizure studies. The preliminary results confirm that EarSD can detect seizures with up to 95.3 percent accuracy by just using classical machine learning algorithms.
MMTF-DES: A Fusion of Multimodal Transformer Models for Desire, Emotion, and Sentiment Analysis of Social Media Data
Oct 22, 2023



Desire is a set of human aspirations and wishes that comprise verbal and cognitive aspects that drive human feelings and behaviors, distinguishing humans from other animals. Understanding human desire has the potential to be one of the most fascinating and challenging research domains. It is tightly coupled with sentiment analysis and emotion recognition tasks. It is beneficial for increasing human-computer interactions, recognizing human emotional intelligence, understanding interpersonal relationships, and making decisions. However, understanding human desire is challenging and under-explored because ways of eliciting desire might be different among humans. The task gets more difficult due to the diverse cultures, countries, and languages. Prior studies overlooked the use of image-text pairwise feature representation, which is crucial for the task of human desire understanding. In this research, we have proposed a unified multimodal transformer-based framework with image-text pair settings to identify human desire, sentiment, and emotion. The core of our proposed method lies in the encoder module, which is built using two state-of-the-art multimodal transformer models. These models allow us to extract diverse features. To effectively extract visual and contextualized embedding features from social media image and text pairs, we conducted joint fine-tuning of two pre-trained multimodal transformer models: Vision-and-Language Transformer (ViLT) and Vision-and-Augmented-Language Transformer (VAuLT). Subsequently, we use an early fusion strategy on these embedding features to obtain combined diverse feature representations of the image-text pair. This consolidation incorporates diverse information about this task, enabling us to robustly perceive the context and image pair from multiple perspectives.
Edge Data Based Trailer Inception Probabilistic Matrix Factorization for Context-Aware Movie Recommendation
Feb 16, 2022

The rapid growth of edge data generated by mobile devices and applications deployed at the edge of the network has exacerbated the problem of information overload. As an effective way to alleviate information overload, recommender system can improve the quality of various services by adding application data generated by users on edge devices, such as visual and textual information, on the basis of sparse rating data. The visual information in the movie trailer is a significant part of the movie recommender system. However, due to the complexity of visual information extraction, data sparsity cannot be remarkably alleviated by merely using the rough visual features to improve the rating prediction accuracy. Fortunately, the convolutional neural network can be used to extract the visual features precisely. Therefore, the end-to-end neural image caption (NIC) model can be utilized to obtain the textual information describing the visual features of movie trailers. This paper proposes a trailer inception probabilistic matrix factorization model called Ti-PMF, which combines NIC, recurrent convolutional neural network, and probabilistic matrix factorization models as the rating prediction model. We implement the proposed Ti-PMF model with extensive experiments on three real-world datasets to validate its effectiveness. The experimental results illustrate that the proposed Ti-PMF outperforms the existing ones.
Graph Learning: A Survey
May 03, 2021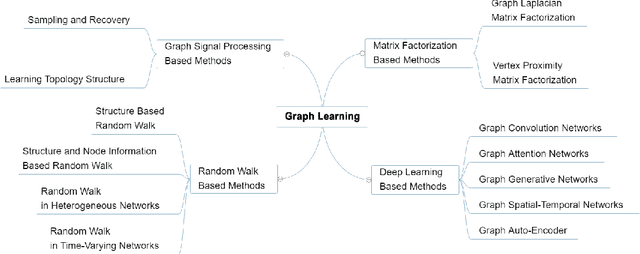
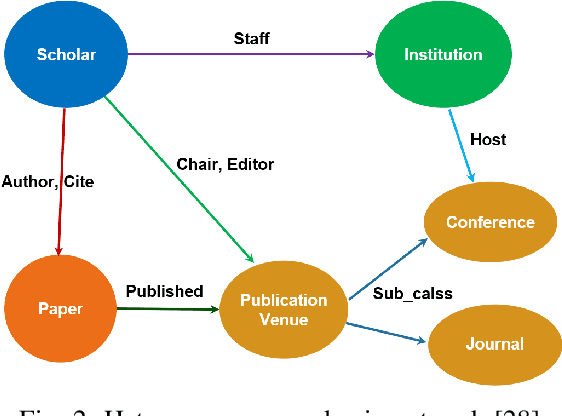
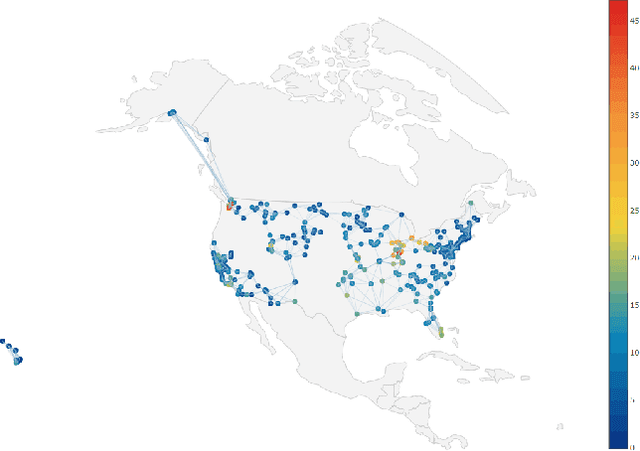
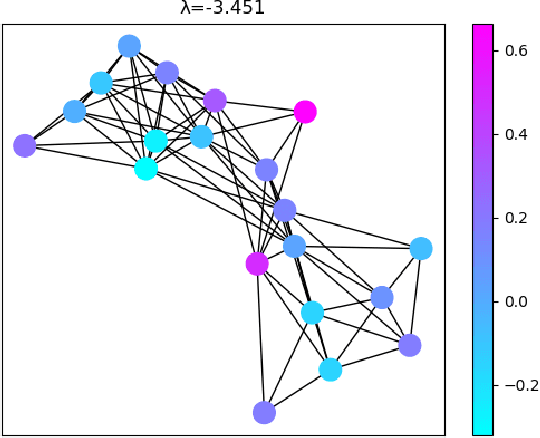
Graphs are widely used as a popular representation of the network structure of connected data. Graph data can be found in a broad spectrum of application domains such as social systems, ecosystems, biological networks, knowledge graphs, and information systems. With the continuous penetration of artificial intelligence technologies, graph learning (i.e., machine learning on graphs) is gaining attention from both researchers and practitioners. Graph learning proves effective for many tasks, such as classification, link prediction, and matching. Generally, graph learning methods extract relevant features of graphs by taking advantage of machine learning algorithms. In this survey, we present a comprehensive overview on the state-of-the-art of graph learning. Special attention is paid to four categories of existing graph learning methods, including graph signal processing, matrix factorization, random walk, and deep learning. Major models and algorithms under these categories are reviewed respectively. We examine graph learning applications in areas such as text, images, science, knowledge graphs, and combinatorial optimization. In addition, we discuss several promising research directions in this field.
* 19 pages, 6 figures