 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Loss Space in Neural Networks is Continuous and Fully Connected
May 05, 2025


Visualizations of the loss landscape in neural networks suggest that minima are isolated points. However, both theoretical and empirical studies indicate that it is possible to connect two different minima with a path consisting of intermediate points that also have low loss. In this study, we propose a new algorithm which investigates low-loss paths in the full parameter space, not only between two minima. Our experiments on LeNet5, ResNet18, and Compact Convolutional Transformer architectures consistently demonstrate the existence of such continuous paths in the parameter space. These results suggest that the low-loss region is a fully connected and continuous space in the parameter space. Our findings provide theoretical insight into neural network over-parameterization, highlighting that parameters collectively define a high-dimensional low-loss space, implying parameter redundancy exists only within individual models and not throughout the entire low-loss space. Additionally, our work also provides new visualization methods and opportunities to improve model generalization by exploring the low-loss space that is closer to the origin.
Vanishing Variance Problem in Fully Decentralized Neural-Network Systems
Apr 06, 2024



Federated learning and gossip learning are emerging methodologies designed to mitigate data privacy concerns by retaining training data on client devices and exclusively sharing locally-trained machine learning (ML) models with others. The primary distinction between the two lies in their approach to model aggregation: federated learning employs a centralized parameter server, whereas gossip learning adopts a fully decentralized mechanism, enabling direct model exchanges among nodes. This decentralized nature often positions gossip learning as less efficient compared to federated learning. Both methodologies involve a critical step: computing a representation of received ML models and integrating this representation into the existing model. Conventionally, this representation is derived by averaging the received models, exemplified by the FedAVG algorithm. Our findings suggest that this averaging approach inherently introduces a potential delay in model convergence. We identify the underlying cause and refer to it as the "vanishing variance" problem, where averaging across uncorrelated ML models undermines the optimal variance established by the Xavier weight initialization. Unlike federated learning where the central server ensures model correlation, and unlike traditional gossip learning which circumvents this problem through model partitioning and sampling, our research introduces a variance-corrected model averaging algorithm. This novel algorithm preserves the optimal variance needed during model averaging, irrespective of network topology or non-IID data distributions. Our extensive simulation results demonstrate that our approach enables gossip learning to achieve convergence efficiency comparable to that of federated learning.
NASH: Neural Architecture Search for Hardware-Optimized Machine Learning Models
Mar 10, 2024
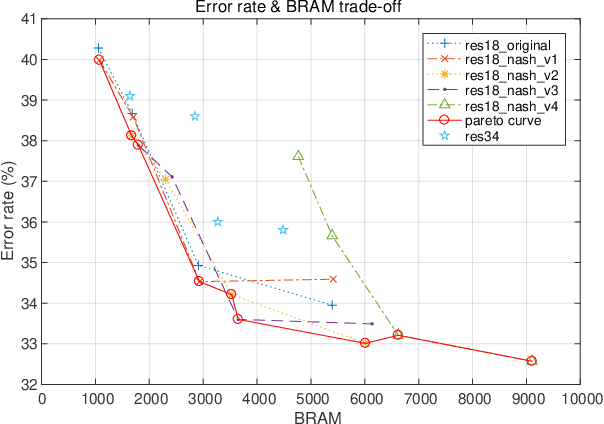

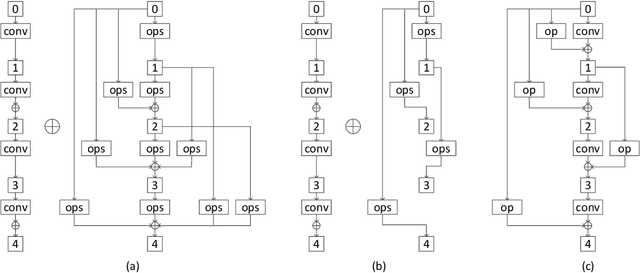
As machine learning (ML) algorithms get deployed in an ever-increasing number of applications, these algorithms need to achieve better trade-offs between high accuracy, high throughput and low latency. This paper introduces NASH, a novel approach that applies neural architecture search to machine learning hardware. Using NASH, hardware designs can achieve not only high throughput and low latency but also superior accuracy performance. We present four versions of the NASH strategy in this paper, all of which show higher accuracy than the original models. The strategy can be applied to various convolutional neural networks, selecting specific model operations among many to guide the training process toward higher accuracy. Experimental results show that applying NASH on ResNet18 or ResNet34 achieves a top 1 accuracy increase of up to 3.1% and a top 5 accuracy increase of up to 2.2% compared to the non-NASH version when tested on the ImageNet data set. We also integrated this approach into the FINN hardware model synthesis tool to automate the application of our approach and the generation of the hardware model. Results show that using FINN can achieve a maximum throughput of 324.5 fps. In addition, NASH models can also result in a better trade-off between accuracy and hardware resource utilization. The accuracy-hardware (HW) Pareto curve shows that the models with the four NASH versions represent the best trade-offs achieving the highest accuracy for a given HW utilization. The code for our implementation is open-source and publicly available on GitHub at https://github.com/MFJI/NASH.
NLICE: Synthetic Medical Record Generation for Effective Primary Healthcare Differential Diagnosis
Jan 24, 2024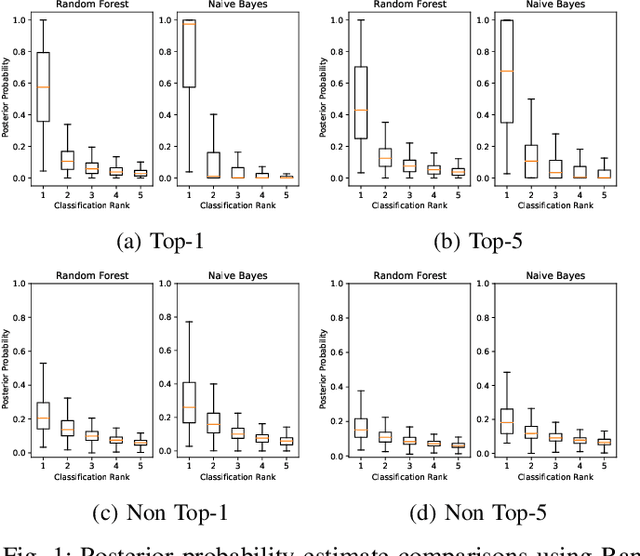
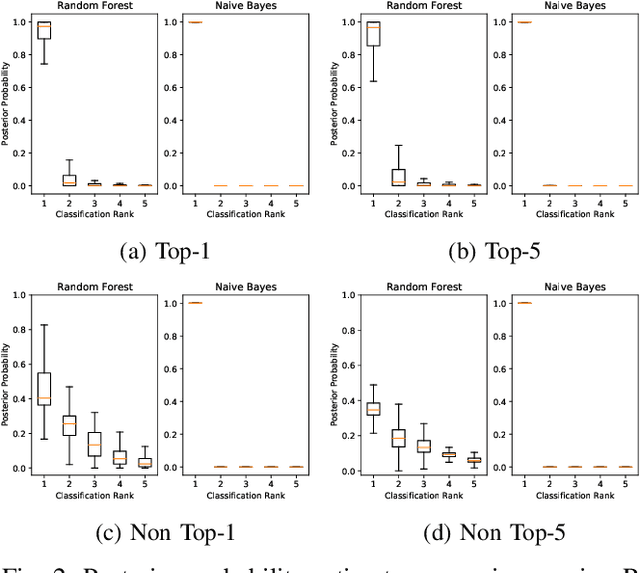
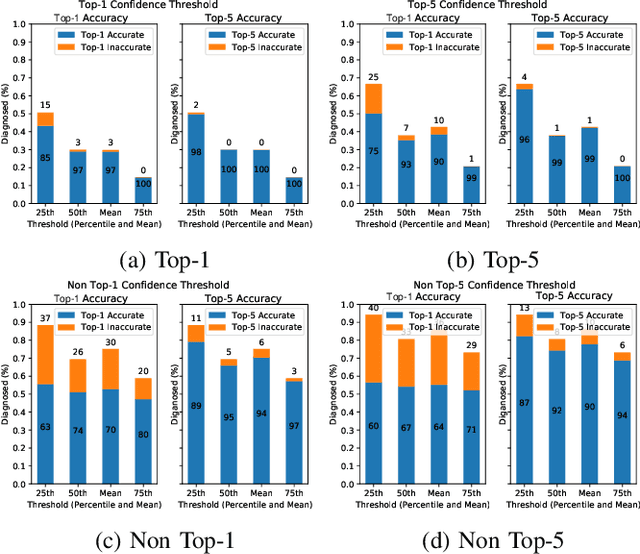
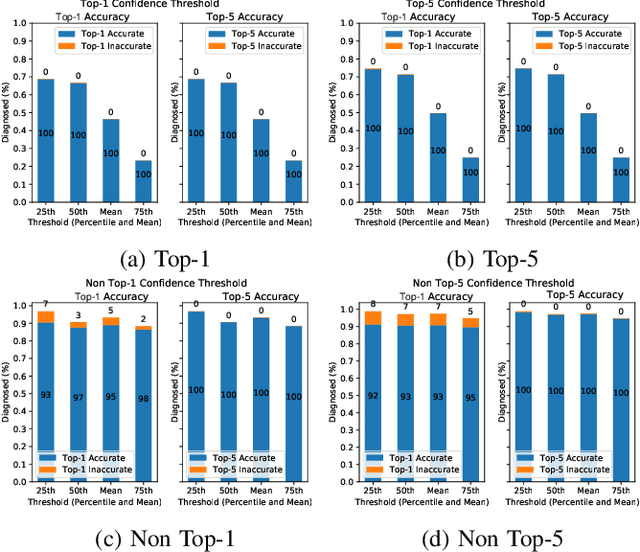
This paper offers a systematic method for creating medical knowledge-grounded patient records for use in activities involving differential diagnosis. Additionally, an assessment of machine learning models that can differentiate between various conditions based on given symptoms is also provided. We use a public disease-symptom data source called SymCat in combination with Synthea to construct the patients records. In order to increase the expressive nature of the synthetic data, we use a medically-standardized symptom modeling method called NLICE to augment the synthetic data with additional contextual information for each condition. In addition, Naive Bayes and Random Forest models are evaluated and compared on the synthetic data. The paper shows how to successfully construct SymCat-based and NLICE-based datasets. We also show results for the effectiveness of using the datasets to train predictive disease models. The SymCat-based dataset is able to train a Naive Bayes and Random Forest model yielding a 58.8% and 57.1% Top-1 accuracy score, respectively. In contrast, the NLICE-based dataset improves the results, with a Top-1 accuracy of 82.0% and Top-5 accuracy values of more than 90% for both models. Our proposed data generation approach solves a major barrier to the application of artificial intelligence methods in the healthcare domain. Our novel NLICE symptom modeling approach addresses the incomplete and insufficient information problem in the current binary symptom representation approach. The NLICE code is open sourced at https://github.com/guozhuoran918/NLICE.
Learning-enabled multi-modal motion prediction in urban environments
Apr 23, 2023



Motion prediction is a key factor towards the full deployment of autonomous vehicles. It is fundamental in order to assure safety while navigating through highly interactive complex scenarios. In this work, the framework IAMP (Interaction- Aware Motion Prediction), producing multi-modal probabilistic outputs from the integration of a Dynamic Bayesian Network and Markov Chains, is extended with a learning-based approach. The integration of a machine learning model tackles the limitations of the ruled-based mechanism since it can better adapt to different driving styles and driving situations. The method here introduced generates context-dependent acceleration distributions used in a Markov-chain-based motion prediction. This hybrid approach results in better evaluation metrics when compared with the baseline in the four
QKSA: Quantum Knowledge Seeking Agent -- resource-optimized reinforcement learning using quantum process tomography
Dec 07, 2021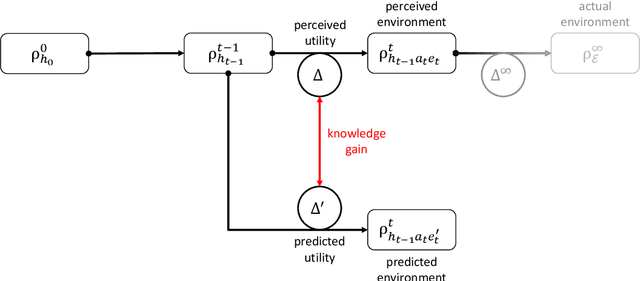
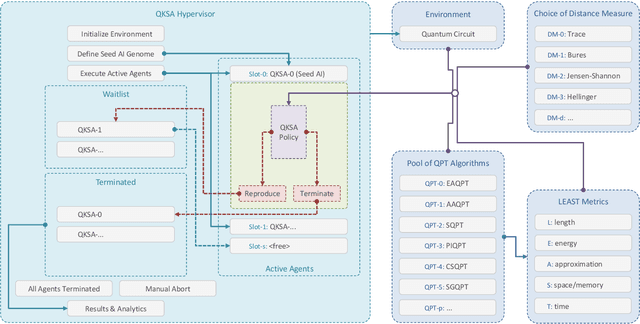
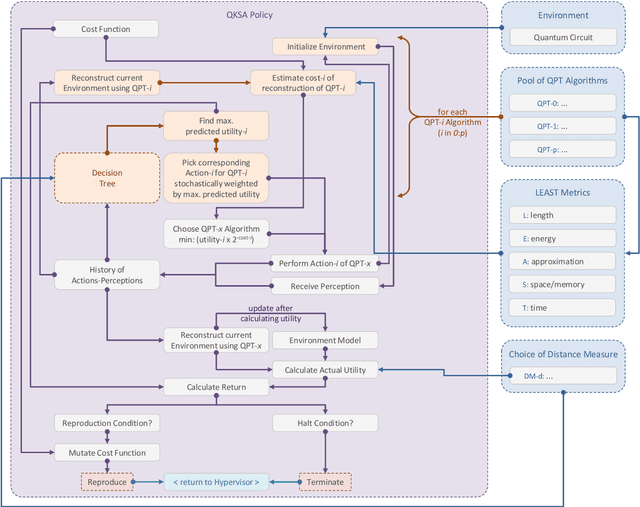
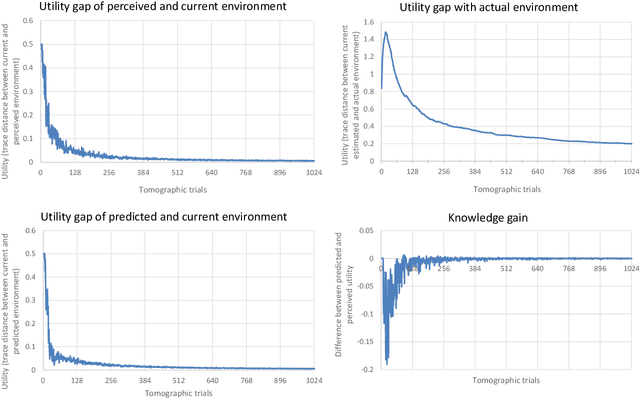
In this research, we extend the universal reinforcement learning (URL) agent models of artificial general intelligence to quantum environments. The utility function of a classical exploratory stochastic Knowledge Seeking Agent, KL-KSA, is generalized to distance measures from quantum information theory on density matrices. Quantum process tomography (QPT) algorithms form the tractable subset of programs for modeling environmental dynamics. The optimal QPT policy is selected based on a mutable cost function based on algorithmic complexity as well as computational resource complexity. Instead of Turing machines, we estimate the cost metrics on a high-level language to allow realistic experimentation. The entire agent design is encapsulated in a self-replicating quine which mutates the cost function based on the predictive value of the optimal policy choosing scheme. Thus, multiple agents with pareto-optimal QPT policies evolve using genetic programming, mimicking the development of physical theories each with different resource trade-offs. This formal framework is termed Quantum Knowledge Seeking Agent (QKSA). Despite its importance, few quantum reinforcement learning models exist in contrast to the current thrust in quantum machine learning. QKSA is the first proposal for a framework that resembles the classical URL models. Similar to how AIXI-tl is a resource-bounded active version of Solomonoff universal induction, QKSA is a resource-bounded participatory observer framework to the recently proposed algorithmic information-based reconstruction of quantum mechanics. QKSA can be applied for simulating and studying aspects of quantum information theory. Specifically, we demonstrate that it can be used to accelerate quantum variational algorithms which include tomographic reconstruction as its integral subroutine.
An Attention Module for Convolutional Neural Networks
Aug 18, 2021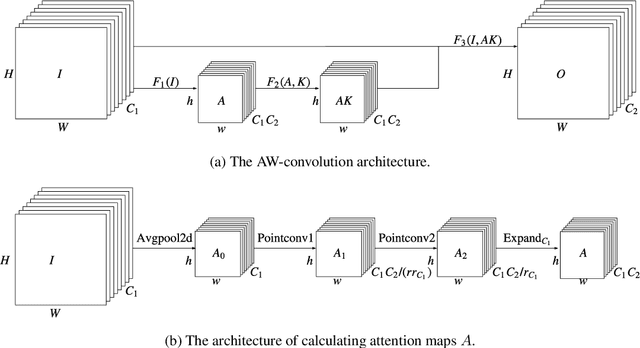
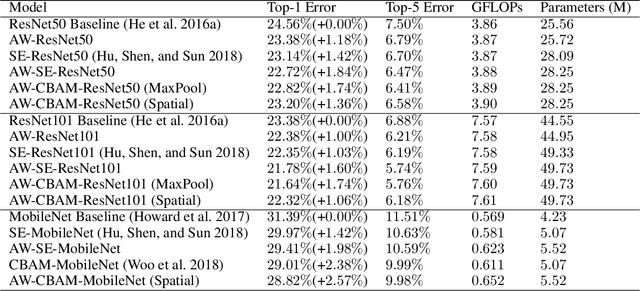
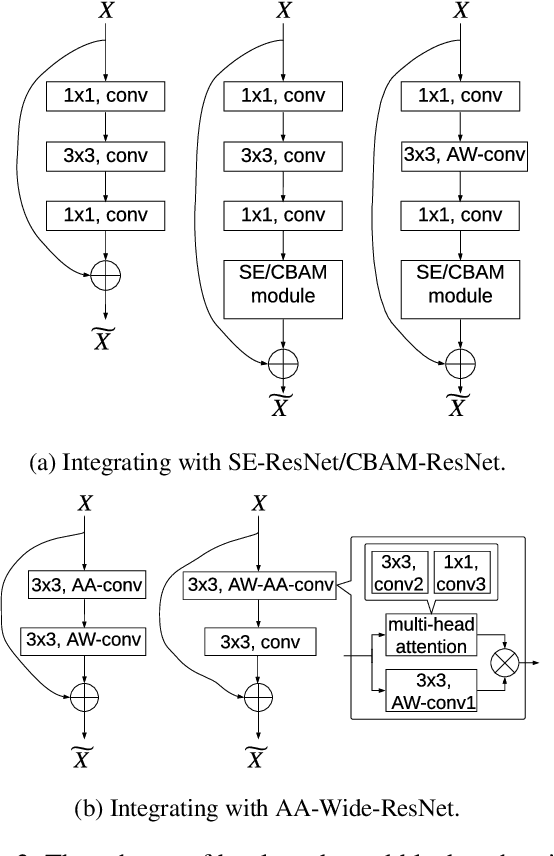
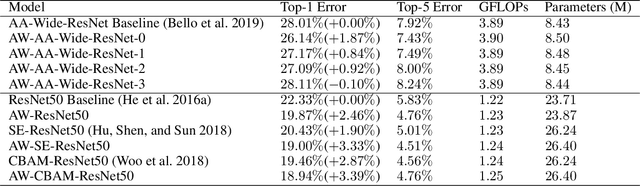
Attention mechanism has been regarded as an advanced technique to capture long-range feature interactions and to boost the representation capability for convolutional neural networks. However, we found two ignored problems in current attentional activations-based models: the approximation problem and the insufficient capacity problem of the attention maps. To solve the two problems together, we initially propose an attention module for convolutional neural networks by developing an AW-convolution, where the shape of attention maps matches that of the weights rather than the activations. Our proposed attention module is a complementary method to previous attention-based schemes, such as those that apply the attention mechanism to explore the relationship between channel-wise and spatial features. Experiments on several datasets for image classification and object detection tasks show the effectiveness of our proposed attention module. In particular, our proposed attention module achieves 1.00% Top-1 accuracy improvement on ImageNet classification over a ResNet101 baseline and 0.63 COCO-style Average Precision improvement on the COCO object detection on top of a Faster R-CNN baseline with the backbone of ResNet101-FPN. When integrating with the previous attentional activations-based models, our proposed attention module can further increase their Top-1 accuracy on ImageNet classification by up to 0.57% and COCO-style Average Precision on the COCO object detection by up to 0.45. Code and pre-trained models will be publicly available.
Fidel: Reconstructing Private Training Samples from Weight Updates in Federated Learning
Jan 01, 2021

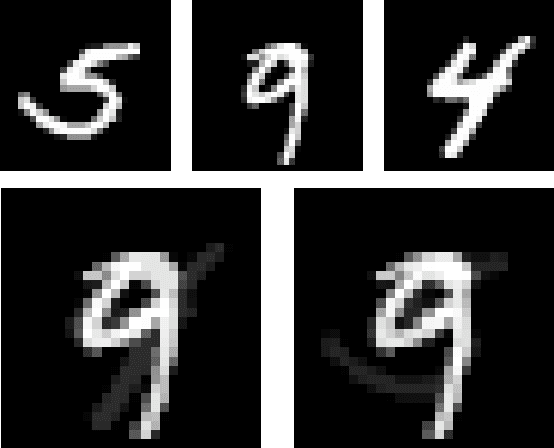

With the increasing number of data collectors such as smartphones, immense amounts of data are available. Federated learning was developed to allow for distributed learning on a massive scale whilst still protecting each users' privacy. This privacy is claimed by the notion that the centralized server does not have any access to a client's data, solely the client's model update. In this paper, we evaluate a novel attack method within regular federated learning which we name the First Dense Layer Attack (Fidel). The methodology of using this attack is discussed, and as a proof of viability we show how this attack method can be used to great effect for densely connected networks and convolutional neural networks. We evaluate some key design decisions and show that the usage of ReLu and Dropout are detrimental to the privacy of a client's local dataset. We show how to recover on average twenty out of thirty private data samples from a client's model update employing a fully connected neural network with very little computational resources required. Similarly, we show that over thirteen out of twenty samples can be recovered from a convolutional neural network update.
Privacy-Preserving Object Detection & Localization Using Distributed Machine Learning: A Case Study of Infant Eyeblink Conditioning
Oct 14, 2020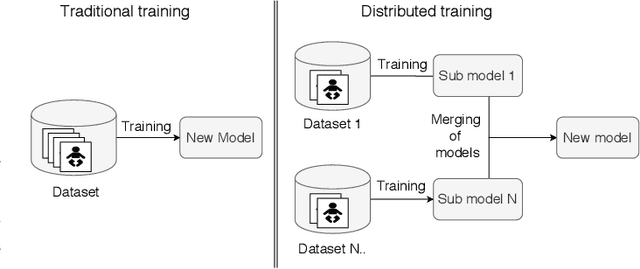
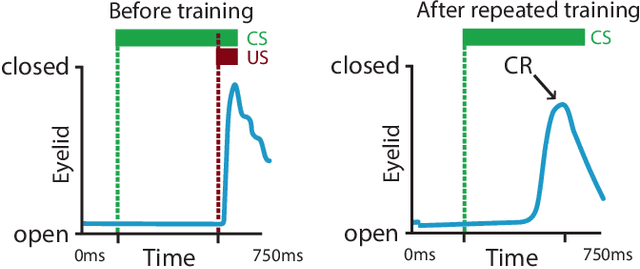
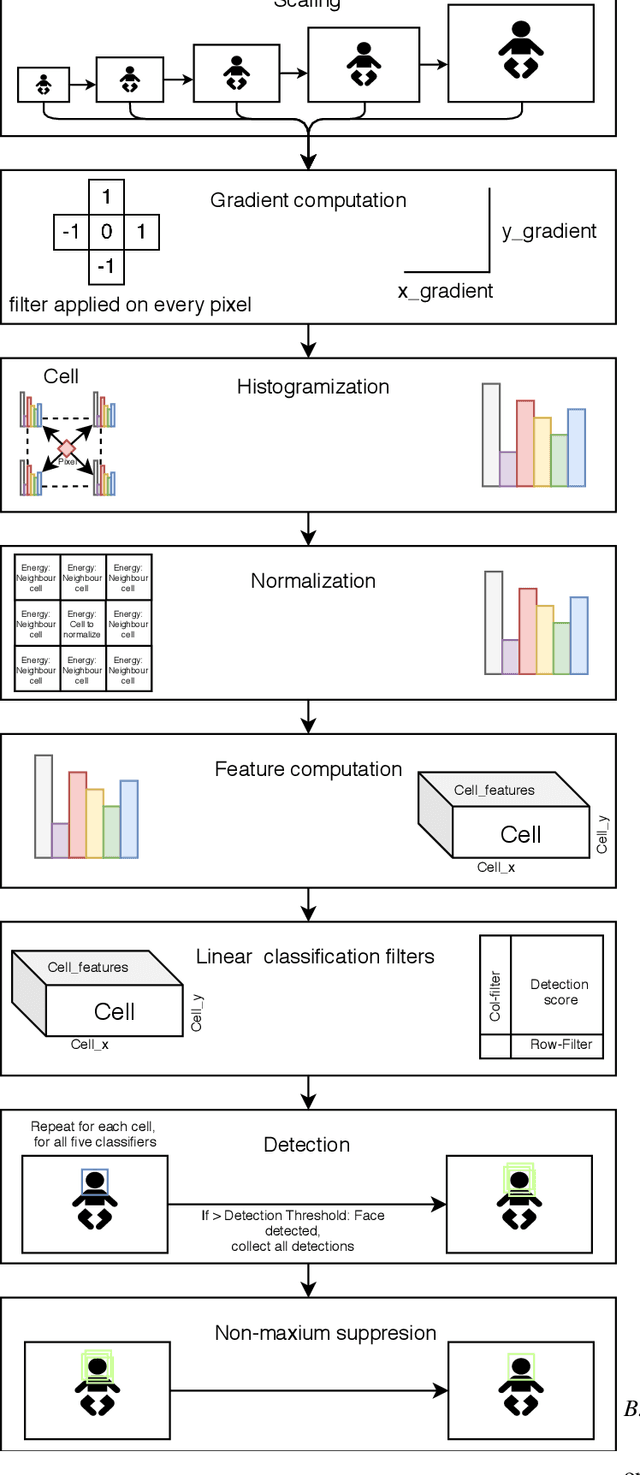
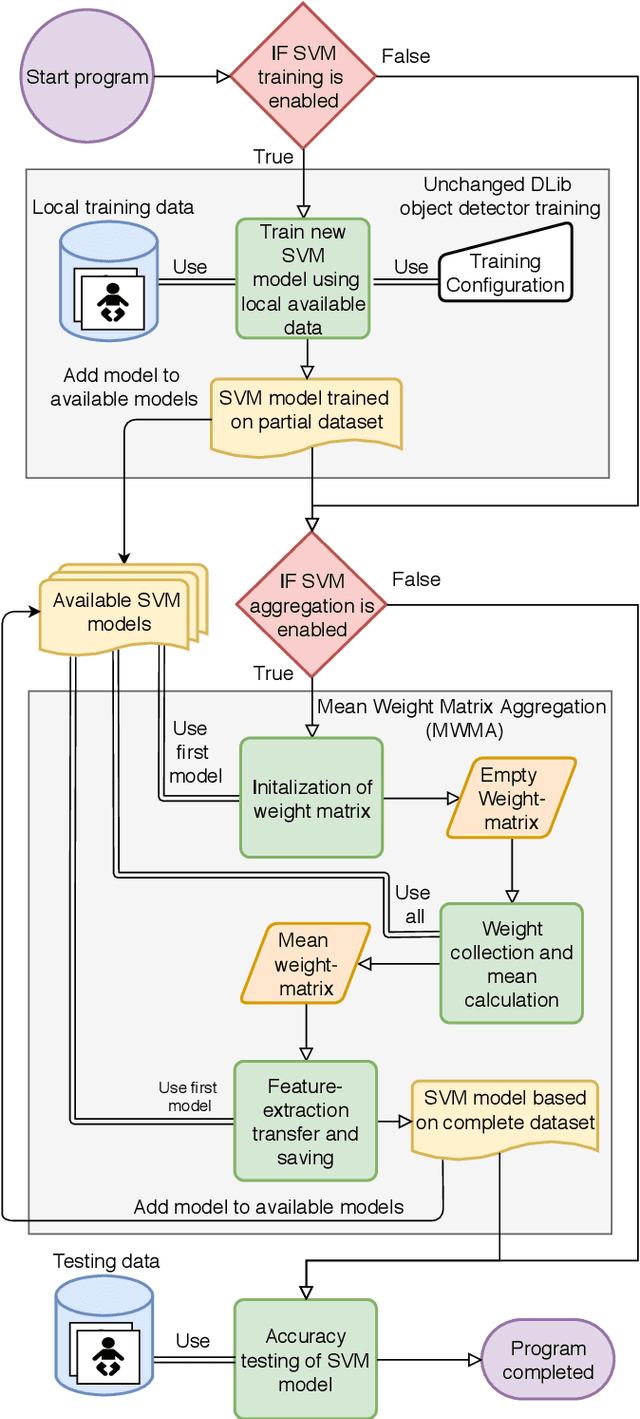
Distributed machine learning is becoming a popular model-training method due to privacy, computational scalability, and bandwidth capacities. In this work, we explore scalable distributed-training versions of two algorithms commonly used in object detection. A novel distributed training algorithm using Mean Weight Matrix Aggregation (MWMA) is proposed for Linear Support Vector Machine (L-SVM) object detection based in Histogram of Orientated Gradients (HOG). In addition, a novel Weighted Bin Aggregation (WBA) algorithm is proposed for distributed training of Ensemble of Regression Trees (ERT) landmark localization. Both algorithms do not restrict the location of model aggregation and allow custom architectures for model distribution. For this work, a Pool-Based Local Training and Aggregation (PBLTA) architecture for both algorithms is explored. The application of both algorithms in the medical field is examined using a paradigm from the fields of psychology and neuroscience - eyeblink conditioning with infants - where models need to be trained on facial images while protecting participant privacy. Using distributed learning, models can be trained without sending image data to other nodes. The custom software has been made available for public use on GitHub: https://github.com/SLWZwaard/DMT. Results show that the aggregation of models for the HOG algorithm using MWMA not only preserves the accuracy of the model but also allows for distributed learning with an accuracy increase of 0.9% compared with traditional learning. Furthermore, WBA allows for ERT model aggregation with an accuracy increase of 8% when compared to single-node models.
SoFAr: Shortcut-based Fractal Architectures for Binary Convolutional Neural Networks
Sep 11, 2020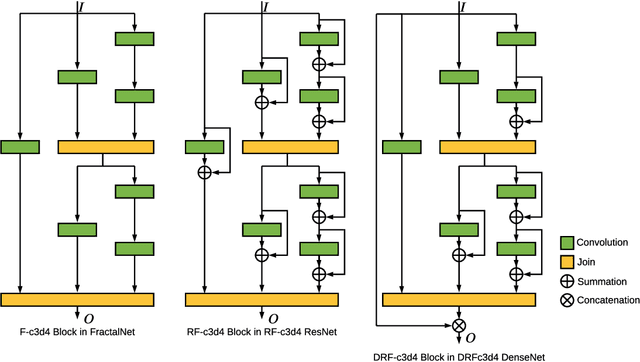
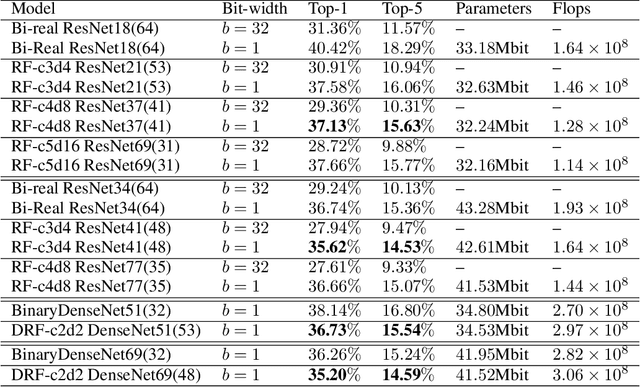
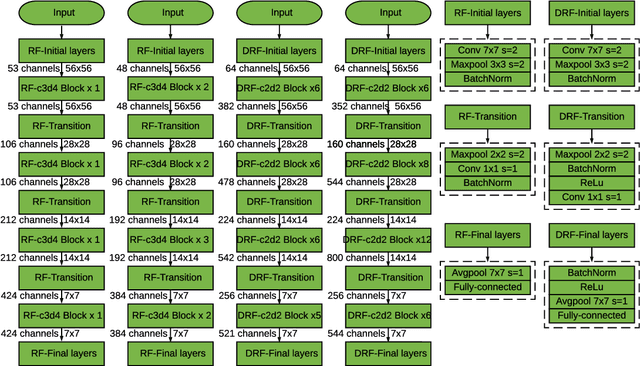
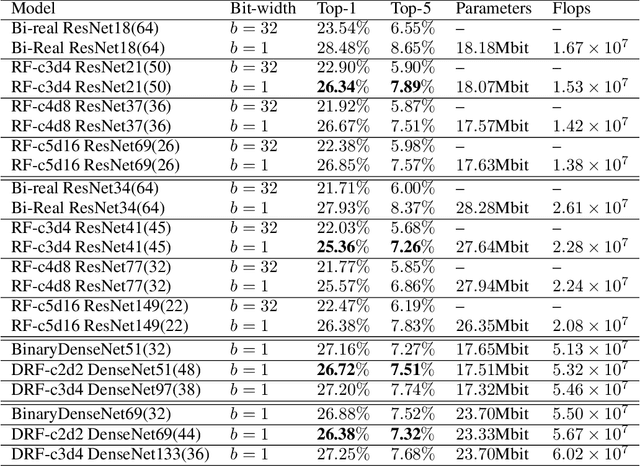
Binary Convolutional Neural Networks (BCNNs) can significantly improve the efficiency of Deep Convolutional Neural Networks (DCNNs) for their deployment on resource-constrained platforms, such as mobile and embedded systems. However, the accuracy degradation of BCNNs is still considerable compared with their full precision counterpart, impeding their practical deployment. Because of the inevitable binarization error in the forward propagation and gradient mismatch problem in the backward propagation, it is nontrivial to train BCNNs to achieve satisfactory accuracy. To ease the difficulty of training, the shortcut-based BCNNs, such as residual connection-based Bi-real ResNet and dense connection-based BinaryDenseNet, introduce additional shortcuts in addition to the shortcuts already present in their full precision counterparts. Furthermore, fractal architectures have been also been used to improve the training process of full-precision DCNNs since the fractal structure triggers effects akin to deep supervision and lateral student-teacher information flow. Inspired by the shortcuts and fractal architectures, we propose two Shortcut-based Fractal Architectures (SoFAr) specifically designed for BCNNs: 1. residual connection-based fractal architectures for binary ResNet, and 2. dense connection-based fractal architectures for binary DenseNet. Our proposed SoFAr combines the adoption of shortcuts and the fractal architectures in one unified model, which is helpful in the training of BCNNs. Results show that our proposed SoFAr achieves better accuracy compared with shortcut-based BCNNs. Specifically, the Top-1 accuracy of our proposed RF-c4d8 ResNet37(41) and DRF-c2d2 DenseNet51(53) on ImageNet outperforms Bi-real ResNet18(64) and BinaryDenseNet51(32) by 3.29% and 1.41%, respectively, with the same computational complexity overhead.