 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Attention Module for Convolutional Neural Networks
Aug 18, 2021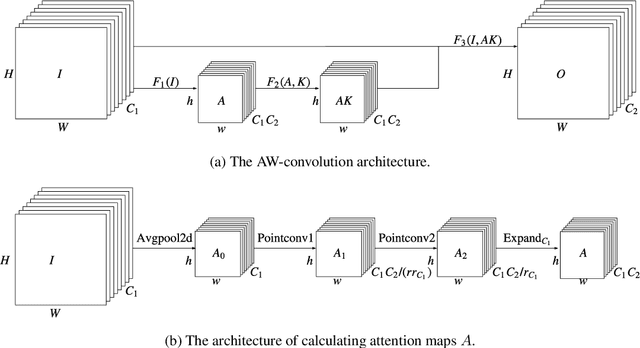
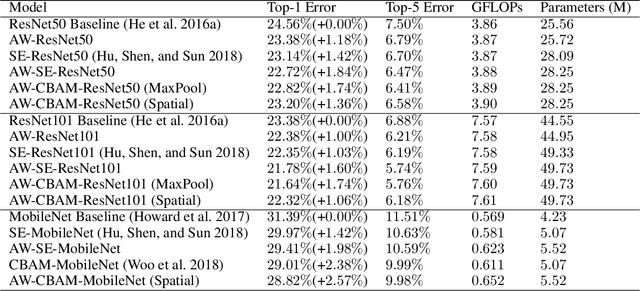
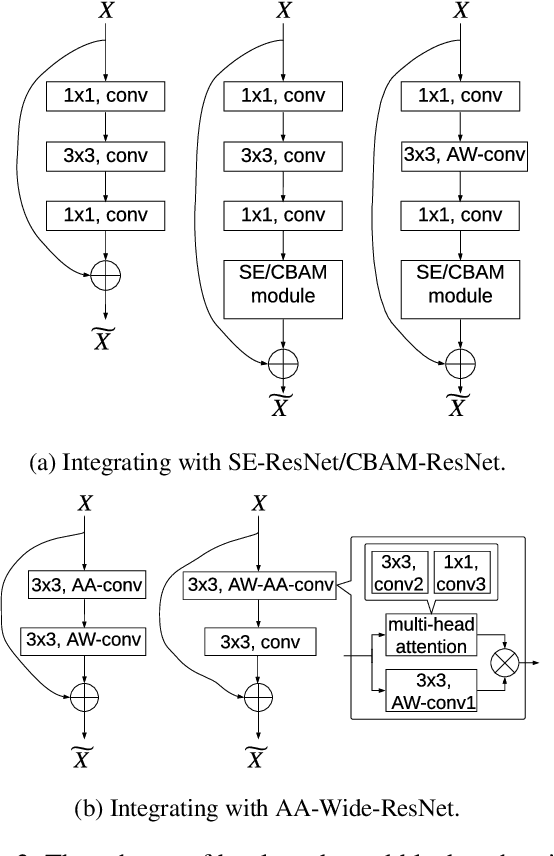
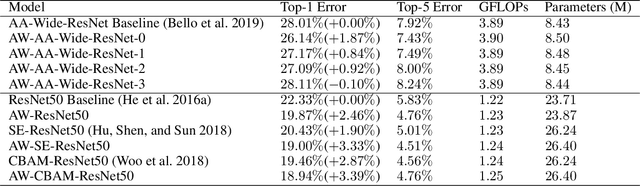
Attention mechanism has been regarded as an advanced technique to capture long-range feature interactions and to boost the representation capability for convolutional neural networks. However, we found two ignored problems in current attentional activations-based models: the approximation problem and the insufficient capacity problem of the attention maps. To solve the two problems together, we initially propose an attention module for convolutional neural networks by developing an AW-convolution, where the shape of attention maps matches that of the weights rather than the activations. Our proposed attention module is a complementary method to previous attention-based schemes, such as those that apply the attention mechanism to explore the relationship between channel-wise and spatial features. Experiments on several datasets for image classification and object detection tasks show the effectiveness of our proposed attention module. In particular, our proposed attention module achieves 1.00% Top-1 accuracy improvement on ImageNet classification over a ResNet101 baseline and 0.63 COCO-style Average Precision improvement on the COCO object detection on top of a Faster R-CNN baseline with the backbone of ResNet101-FPN. When integrating with the previous attentional activations-based models, our proposed attention module can further increase their Top-1 accuracy on ImageNet classification by up to 0.57% and COCO-style Average Precision on the COCO object detection by up to 0.45. Code and pre-trained models will be publicly available.
SoFAr: Shortcut-based Fractal Architectures for Binary Convolutional Neural Networks
Sep 11, 2020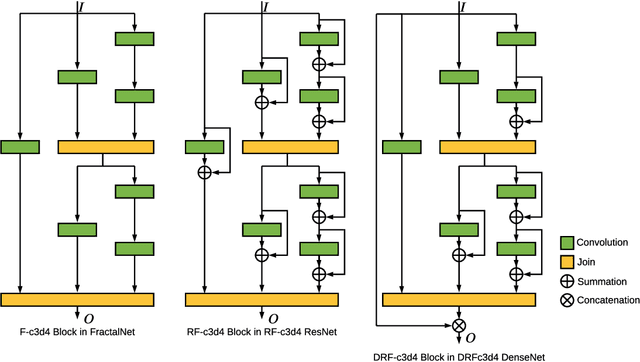
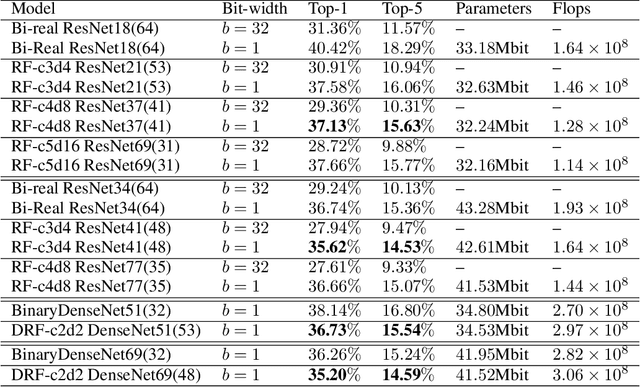
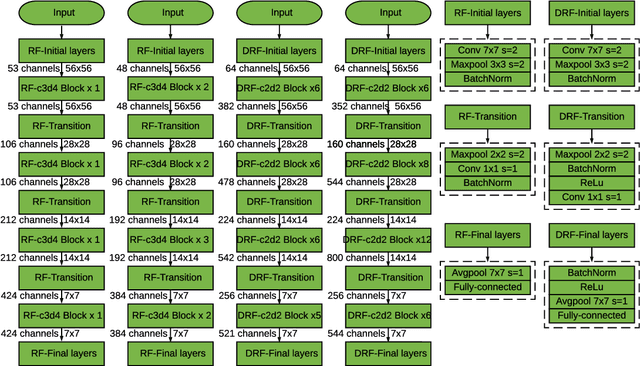
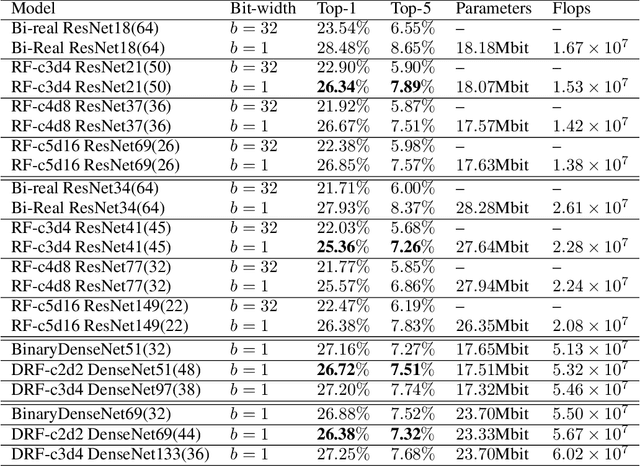
Binary Convolutional Neural Networks (BCNNs) can significantly improve the efficiency of Deep Convolutional Neural Networks (DCNNs) for their deployment on resource-constrained platforms, such as mobile and embedded systems. However, the accuracy degradation of BCNNs is still considerable compared with their full precision counterpart, impeding their practical deployment. Because of the inevitable binarization error in the forward propagation and gradient mismatch problem in the backward propagation, it is nontrivial to train BCNNs to achieve satisfactory accuracy. To ease the difficulty of training, the shortcut-based BCNNs, such as residual connection-based Bi-real ResNet and dense connection-based BinaryDenseNet, introduce additional shortcuts in addition to the shortcuts already present in their full precision counterparts. Furthermore, fractal architectures have been also been used to improve the training process of full-precision DCNNs since the fractal structure triggers effects akin to deep supervision and lateral student-teacher information flow. Inspired by the shortcuts and fractal architectures, we propose two Shortcut-based Fractal Architectures (SoFAr) specifically designed for BCNNs: 1. residual connection-based fractal architectures for binary ResNet, and 2. dense connection-based fractal architectures for binary DenseNet. Our proposed SoFAr combines the adoption of shortcuts and the fractal architectures in one unified model, which is helpful in the training of BCNNs. Results show that our proposed SoFAr achieves better accuracy compared with shortcut-based BCNNs. Specifically, the Top-1 accuracy of our proposed RF-c4d8 ResNet37(41) and DRF-c2d2 DenseNet51(53) on ImageNet outperforms Bi-real ResNet18(64) and BinaryDenseNet51(32) by 3.29% and 1.41%, respectively, with the same computational complexity overhead.