 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Loss Space in Neural Networks is Continuous and Fully Connected
May 05, 2025


Visualizations of the loss landscape in neural networks suggest that minima are isolated points. However, both theoretical and empirical studies indicate that it is possible to connect two different minima with a path consisting of intermediate points that also have low loss. In this study, we propose a new algorithm which investigates low-loss paths in the full parameter space, not only between two minima. Our experiments on LeNet5, ResNet18, and Compact Convolutional Transformer architectures consistently demonstrate the existence of such continuous paths in the parameter space. These results suggest that the low-loss region is a fully connected and continuous space in the parameter space. Our findings provide theoretical insight into neural network over-parameterization, highlighting that parameters collectively define a high-dimensional low-loss space, implying parameter redundancy exists only within individual models and not throughout the entire low-loss space. Additionally, our work also provides new visualization methods and opportunities to improve model generalization by exploring the low-loss space that is closer to the origin.
Vanishing Variance Problem in Fully Decentralized Neural-Network Systems
Apr 06, 2024



Federated learning and gossip learning are emerging methodologies designed to mitigate data privacy concerns by retaining training data on client devices and exclusively sharing locally-trained machine learning (ML) models with others. The primary distinction between the two lies in their approach to model aggregation: federated learning employs a centralized parameter server, whereas gossip learning adopts a fully decentralized mechanism, enabling direct model exchanges among nodes. This decentralized nature often positions gossip learning as less efficient compared to federated learning. Both methodologies involve a critical step: computing a representation of received ML models and integrating this representation into the existing model. Conventionally, this representation is derived by averaging the received models, exemplified by the FedAVG algorithm. Our findings suggest that this averaging approach inherently introduces a potential delay in model convergence. We identify the underlying cause and refer to it as the "vanishing variance" problem, where averaging across uncorrelated ML models undermines the optimal variance established by the Xavier weight initialization. Unlike federated learning where the central server ensures model correlation, and unlike traditional gossip learning which circumvents this problem through model partitioning and sampling, our research introduces a variance-corrected model averaging algorithm. This novel algorithm preserves the optimal variance needed during model averaging, irrespective of network topology or non-IID data distributions. Our extensive simulation results demonstrate that our approach enables gossip learning to achieve convergence efficiency comparable to that of federated learning.
An Attention Module for Convolutional Neural Networks
Aug 18, 2021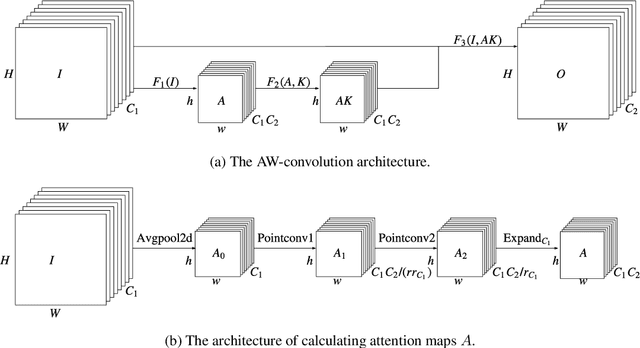
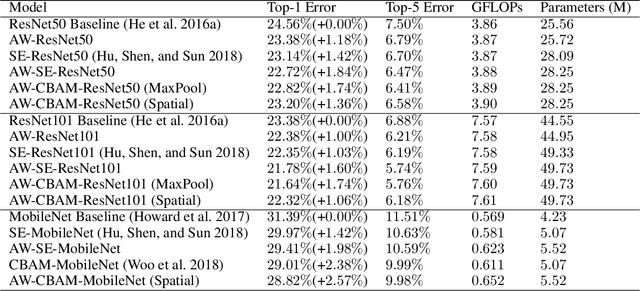
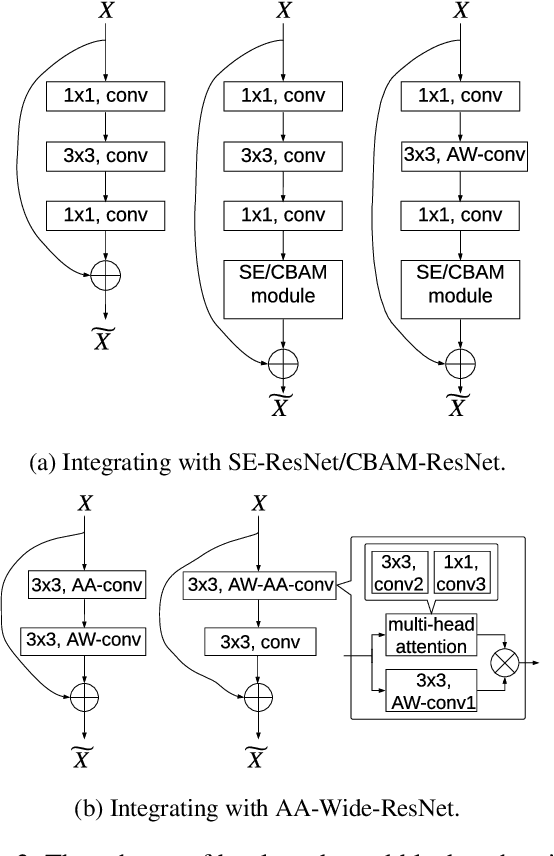
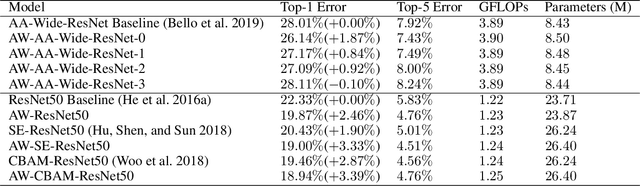
Attention mechanism has been regarded as an advanced technique to capture long-range feature interactions and to boost the representation capability for convolutional neural networks. However, we found two ignored problems in current attentional activations-based models: the approximation problem and the insufficient capacity problem of the attention maps. To solve the two problems together, we initially propose an attention module for convolutional neural networks by developing an AW-convolution, where the shape of attention maps matches that of the weights rather than the activations. Our proposed attention module is a complementary method to previous attention-based schemes, such as those that apply the attention mechanism to explore the relationship between channel-wise and spatial features. Experiments on several datasets for image classification and object detection tasks show the effectiveness of our proposed attention module. In particular, our proposed attention module achieves 1.00% Top-1 accuracy improvement on ImageNet classification over a ResNet101 baseline and 0.63 COCO-style Average Precision improvement on the COCO object detection on top of a Faster R-CNN baseline with the backbone of ResNet101-FPN. When integrating with the previous attentional activations-based models, our proposed attention module can further increase their Top-1 accuracy on ImageNet classification by up to 0.57% and COCO-style Average Precision on the COCO object detection by up to 0.45. Code and pre-trained models will be publicly available.
AutoReCon: Neural Architecture Search-based Reconstruction for Data-free Compression
May 25, 2021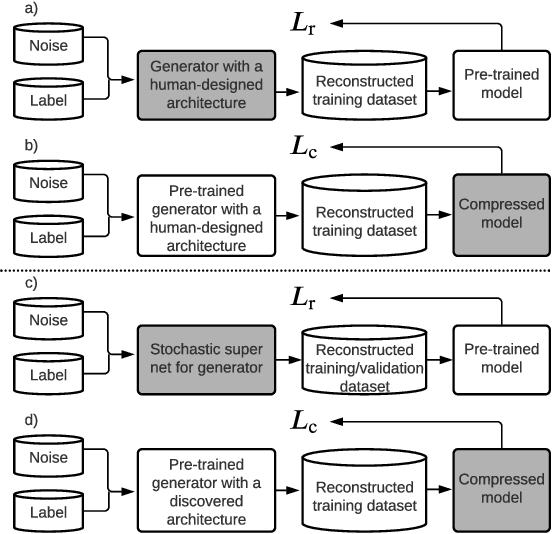
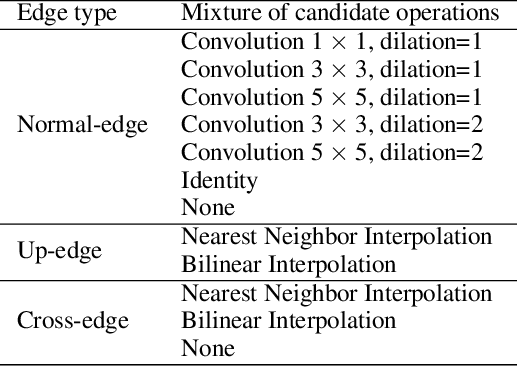
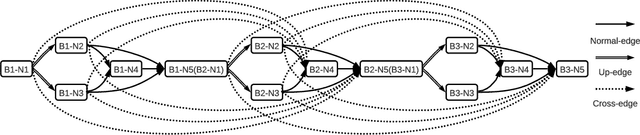
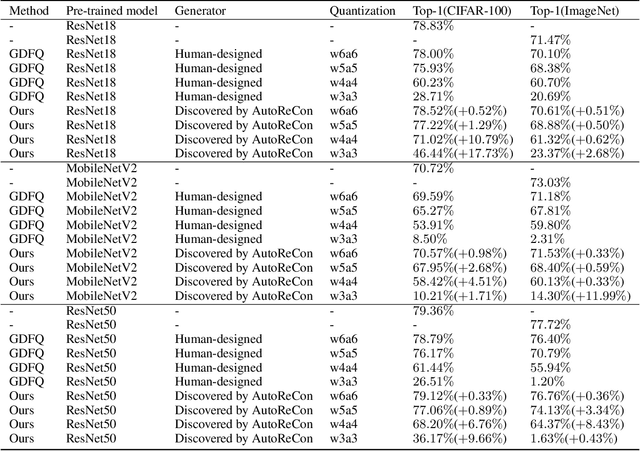
Data-free compression raises a new challenge because the original training dataset for a pre-trained model to be compressed is not available due to privacy or transmission issues. Thus, a common approach is to compute a reconstructed training dataset before compression. The current reconstruction methods compute the reconstructed training dataset with a generator by exploiting information from the pre-trained model. However, current reconstruction methods focus on extracting more information from the pre-trained model but do not leverage network engineering. This work is the first to consider network engineering as an approach to design the reconstruction method. Specifically, we propose the AutoReCon method, which is a neural architecture search-based reconstruction method. In the proposed AutoReCon method, the generator architecture is designed automatically given the pre-trained model for reconstruction. Experimental results show that using generators discovered by the AutoRecon method always improve the performance of data-free compression.
SoFAr: Shortcut-based Fractal Architectures for Binary Convolutional Neural Networks
Sep 11, 2020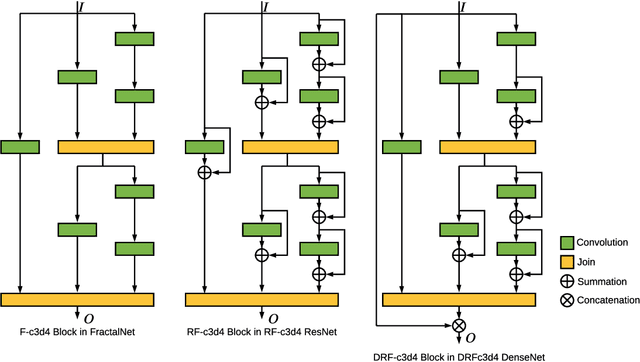
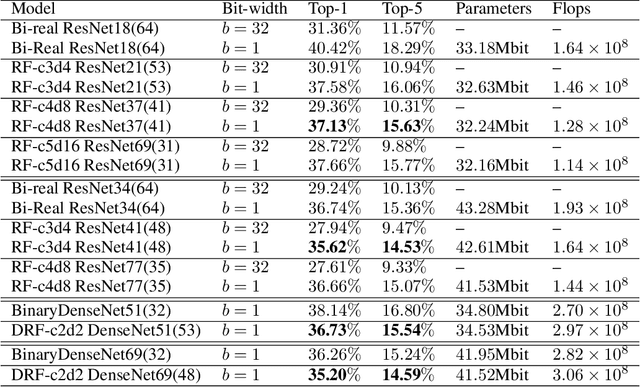
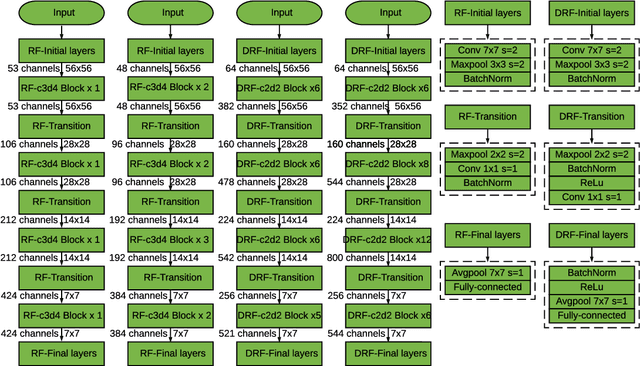
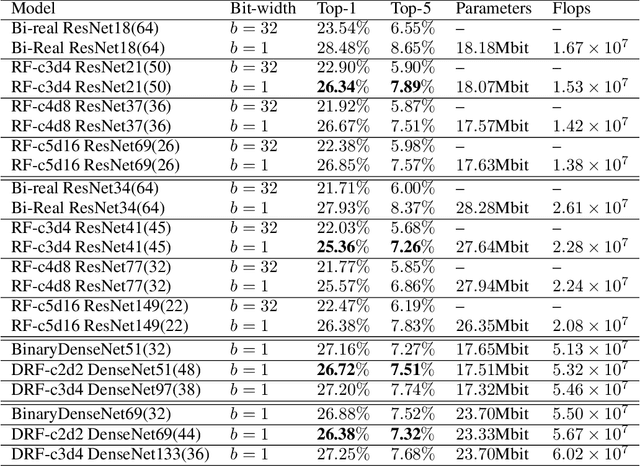
Binary Convolutional Neural Networks (BCNNs) can significantly improve the efficiency of Deep Convolutional Neural Networks (DCNNs) for their deployment on resource-constrained platforms, such as mobile and embedded systems. However, the accuracy degradation of BCNNs is still considerable compared with their full precision counterpart, impeding their practical deployment. Because of the inevitable binarization error in the forward propagation and gradient mismatch problem in the backward propagation, it is nontrivial to train BCNNs to achieve satisfactory accuracy. To ease the difficulty of training, the shortcut-based BCNNs, such as residual connection-based Bi-real ResNet and dense connection-based BinaryDenseNet, introduce additional shortcuts in addition to the shortcuts already present in their full precision counterparts. Furthermore, fractal architectures have been also been used to improve the training process of full-precision DCNNs since the fractal structure triggers effects akin to deep supervision and lateral student-teacher information flow. Inspired by the shortcuts and fractal architectures, we propose two Shortcut-based Fractal Architectures (SoFAr) specifically designed for BCNNs: 1. residual connection-based fractal architectures for binary ResNet, and 2. dense connection-based fractal architectures for binary DenseNet. Our proposed SoFAr combines the adoption of shortcuts and the fractal architectures in one unified model, which is helpful in the training of BCNNs. Results show that our proposed SoFAr achieves better accuracy compared with shortcut-based BCNNs. Specifically, the Top-1 accuracy of our proposed RF-c4d8 ResNet37(41) and DRF-c2d2 DenseNet51(53) on ImageNet outperforms Bi-real ResNet18(64) and BinaryDenseNet51(32) by 3.29% and 1.41%, respectively, with the same computational complexity overhead.
NASB: Neural Architecture Search for Binary Convolutional Neural Networks
Aug 08, 2020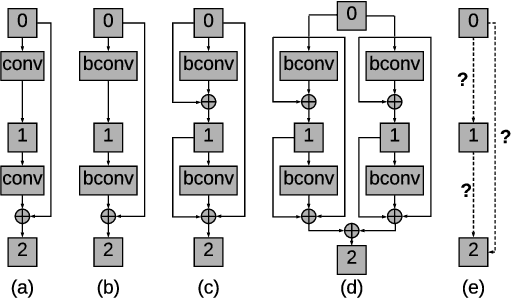
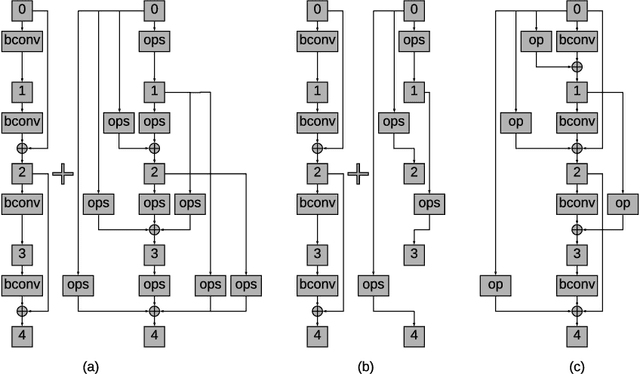
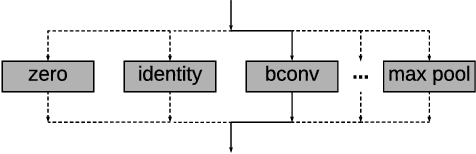
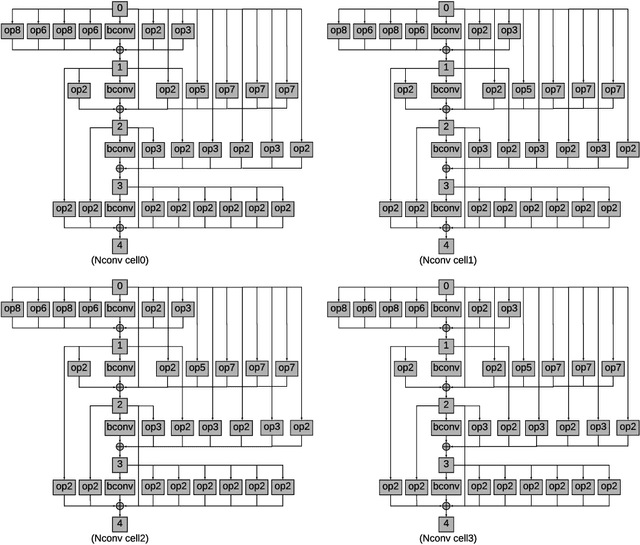
Binary Convolutional Neural Networks (CNNs) have significantly reduced the number of arithmetic operations and the size of memory storage needed for CNNs, which makes their deployment on mobile and embedded systems more feasible. However, the CNN architecture after binarizing requires to be redesigned and refined significantly due to two reasons: 1. the large accumulation error of binarization in the forward propagation, and 2. the severe gradient mismatch problem of binarization in the backward propagation. Even though the substantial effort has been invested in designing architectures for single and multiple binary CNNs, it is still difficult to find an optimal architecture for binary CNNs. In this paper, we propose a strategy, named NASB, which adopts Neural Architecture Search (NAS) to find an optimal architecture for the binarization of CNNs. Due to the flexibility of this automated strategy, the obtained architecture is not only suitable for binarization but also has low overhead, achieving a better trade-off between the accuracy and computational complexity of hand-optimized binary CNNs. The implementation of NASB strategy is evaluated on the ImageNet dataset and demonstrated as a better solution compared to existing quantized CNNs. With the insignificant overhead increase, NASB outperforms existing single and multiple binary CNNs by up to 4.0% and 1.0% Top-1 accuracy respectively, bringing them closer to the precision of their full precision counterpart. The code and pretrained models will be publicly available.