 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow-Loss Space in Neural Networks is Continuous and Fully Connected
May 05, 2025


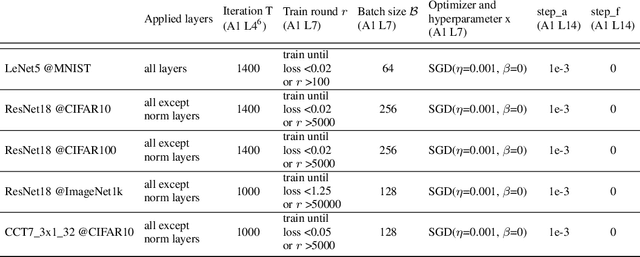
Visualizations of the loss landscape in neural networks suggest that minima are isolated points. However, both theoretical and empirical studies indicate that it is possible to connect two different minima with a path consisting of intermediate points that also have low loss. In this study, we propose a new algorithm which investigates low-loss paths in the full parameter space, not only between two minima. Our experiments on LeNet5, ResNet18, and Compact Convolutional Transformer architectures consistently demonstrate the existence of such continuous paths in the parameter space. These results suggest that the low-loss region is a fully connected and continuous space in the parameter space. Our findings provide theoretical insight into neural network over-parameterization, highlighting that parameters collectively define a high-dimensional low-loss space, implying parameter redundancy exists only within individual models and not throughout the entire low-loss space. Additionally, our work also provides new visualization methods and opportunities to improve model generalization by exploring the low-loss space that is closer to the origin.
Vanishing Variance Problem in Fully Decentralized Neural-Network Systems
Apr 06, 2024



Federated learning and gossip learning are emerging methodologies designed to mitigate data privacy concerns by retaining training data on client devices and exclusively sharing locally-trained machine learning (ML) models with others. The primary distinction between the two lies in their approach to model aggregation: federated learning employs a centralized parameter server, whereas gossip learning adopts a fully decentralized mechanism, enabling direct model exchanges among nodes. This decentralized nature often positions gossip learning as less efficient compared to federated learning. Both methodologies involve a critical step: computing a representation of received ML models and integrating this representation into the existing model. Conventionally, this representation is derived by averaging the received models, exemplified by the FedAVG algorithm. Our findings suggest that this averaging approach inherently introduces a potential delay in model convergence. We identify the underlying cause and refer to it as the "vanishing variance" problem, where averaging across uncorrelated ML models undermines the optimal variance established by the Xavier weight initialization. Unlike federated learning where the central server ensures model correlation, and unlike traditional gossip learning which circumvents this problem through model partitioning and sampling, our research introduces a variance-corrected model averaging algorithm. This novel algorithm preserves the optimal variance needed during model averaging, irrespective of network topology or non-IID data distributions. Our extensive simulation results demonstrate that our approach enables gossip learning to achieve convergence efficiency comparable to that of federated learning.