 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNASH: Neural Architecture Search for Hardware-Optimized Machine Learning Models
Paper and Code

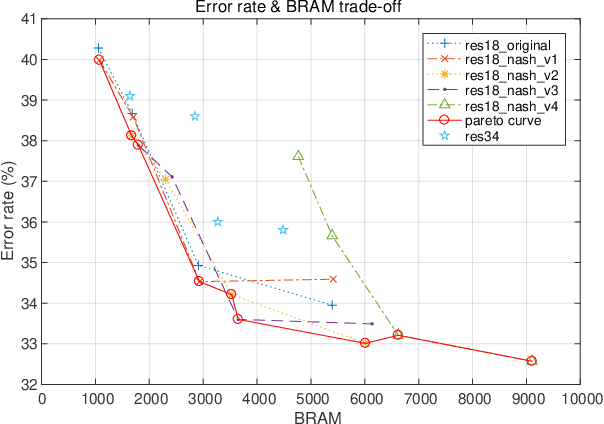

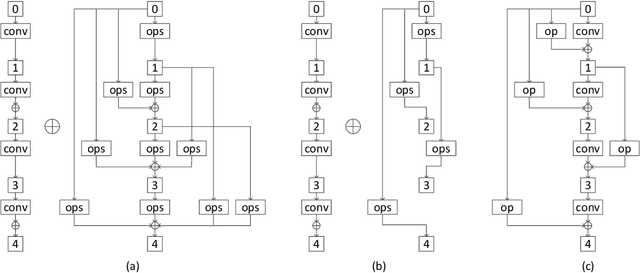
As machine learning (ML) algorithms get deployed in an ever-increasing number of applications, these algorithms need to achieve better trade-offs between high accuracy, high throughput and low latency. This paper introduces NASH, a novel approach that applies neural architecture search to machine learning hardware. Using NASH, hardware designs can achieve not only high throughput and low latency but also superior accuracy performance. We present four versions of the NASH strategy in this paper, all of which show higher accuracy than the original models. The strategy can be applied to various convolutional neural networks, selecting specific model operations among many to guide the training process toward higher accuracy. Experimental results show that applying NASH on ResNet18 or ResNet34 achieves a top 1 accuracy increase of up to 3.1% and a top 5 accuracy increase of up to 2.2% compared to the non-NASH version when tested on the ImageNet data set. We also integrated this approach into the FINN hardware model synthesis tool to automate the application of our approach and the generation of the hardware model. Results show that using FINN can achieve a maximum throughput of 324.5 fps. In addition, NASH models can also result in a better trade-off between accuracy and hardware resource utilization. The accuracy-hardware (HW) Pareto curve shows that the models with the four NASH versions represent the best trade-offs achieving the highest accuracy for a given HW utilization. The code for our implementation is open-source and publicly available on GitHub at https://github.com/MFJI/NASH.