 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Accent Conversion with Reference Encoder and End-To-End Text-To-Speech
May 19, 2020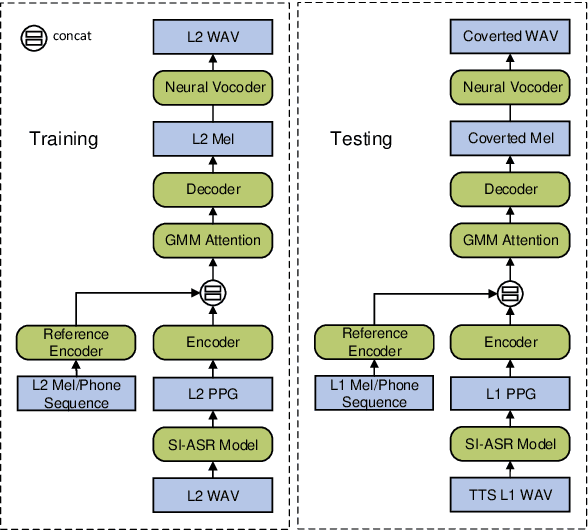
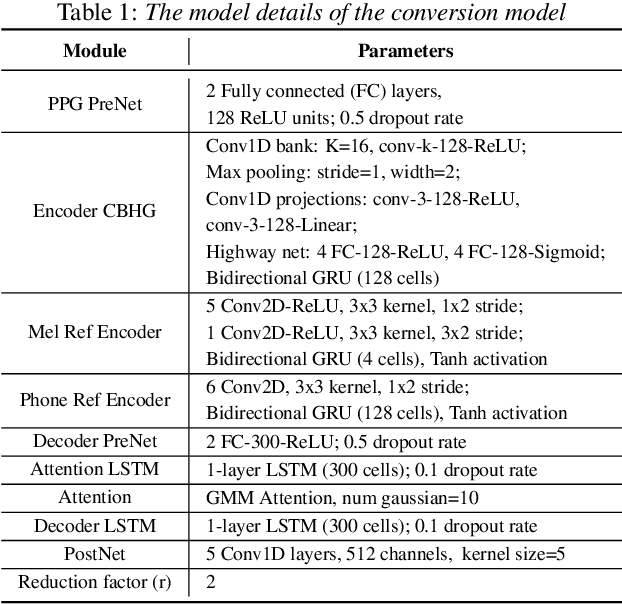
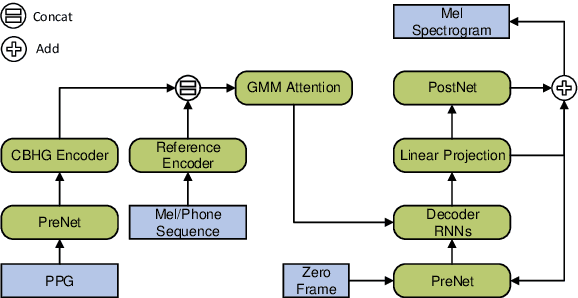
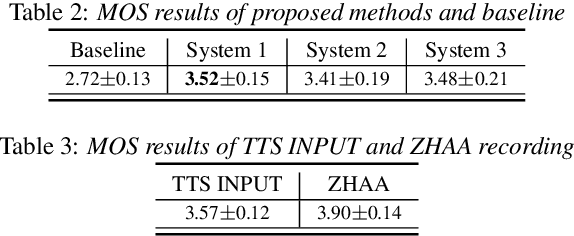
Accent conversion (AC) transforms a non-native speaker's accent into a native accent while maintaining the speaker's voice timbre. In this paper, we propose approaches to improving accent conversion applicability, as well as quality. First of all, we assume no reference speech is available at the conversion stage, and hence we employ an end-to-end text-to-speech system that is trained on native speech to generate native reference speech. To improve the quality and accent of the converted speech, we introduce reference encoders which make us capable of utilizing multi-source information. This is motivated by acoustic features extracted from native reference and linguistic information, which are complementary to conventional phonetic posteriorgrams (PPGs), so they can be concatenated as features to improve a baseline system based only on PPGs. Moreover, we optimize model architecture using GMM-based attention instead of windowed attention to elevate synthesized performance. Experimental results indicate when the proposed techniques are applied the integrated system significantly raises the scores of acoustic quality (30$\%$ relative increase in mean opinion score) and native accent (68$\%$ relative preference) while retaining the voice identity of the non-native speaker.
A Corpus of Adpositional Supersenses for Mandarin Chinese
Mar 18, 2020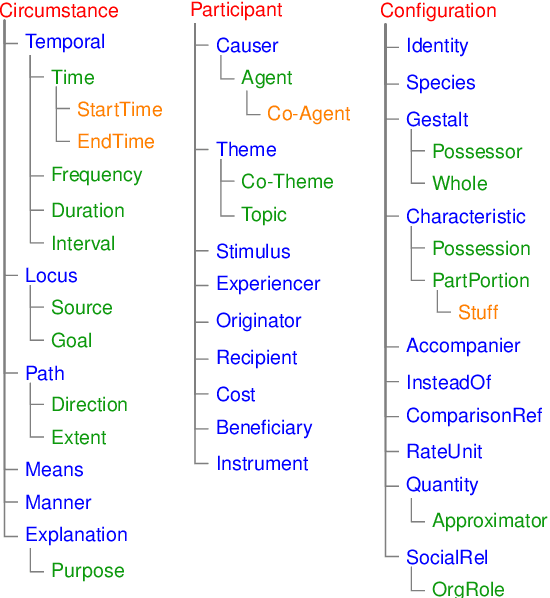
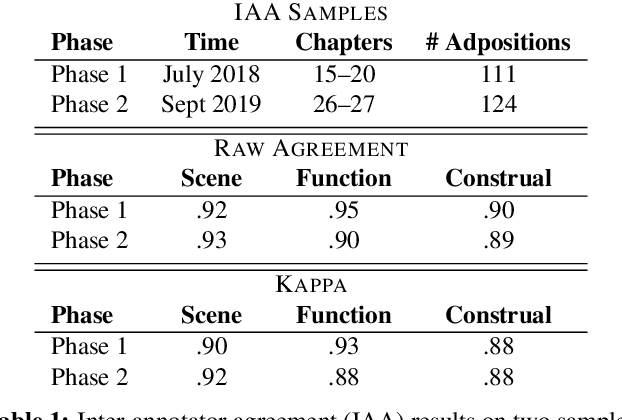
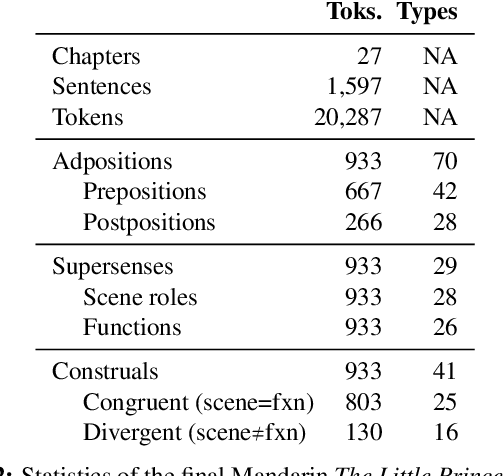
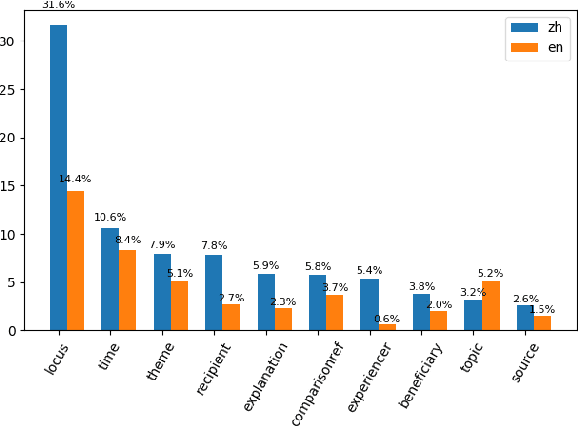
Adpositions are frequent markers of semantic relations, but they are highly ambiguous and vary significantly from language to language. Moreover, there is a dearth of annotated corpora for investigating the cross-linguistic variation of adposition semantics, or for building multilingual disambiguation systems. This paper presents a corpus in which all adpositions have been semantically annotated in Mandarin Chinese; to the best of our knowledge, this is the first Chinese corpus to be broadly annotated with adposition semantics. Our approach adapts a framework that defined a general set of supersenses according to ostensibly language-independent semantic criteria, though its development focused primarily on English prepositions (Schneider et al., 2018). We find that the supersense categories are well-suited to Chinese adpositions despite syntactic differences from English. On a Mandarin translation of The Little Prince, we achieve high inter-annotator agreement and analyze semantic correspondences of adposition tokens in bitext.
Adpositional Supersenses for Mandarin Chinese
Dec 06, 2018

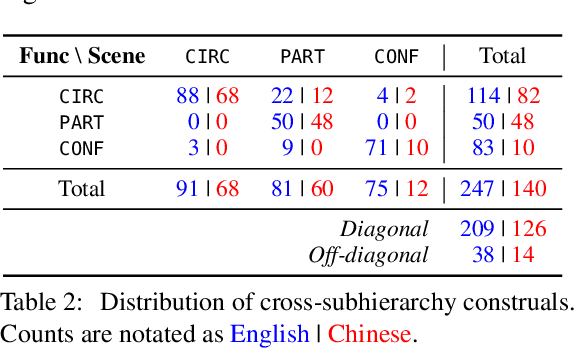
This study adapts Semantic Network of Adposition and Case Supersenses (SNACS) annotation to Mandarin Chinese and demonstrates that the same supersense categories are appropriate for Chinese adposition semantics. We annotated 15 chapters of The Little Prince, with high interannotator agreement. The parallel corpus gives insight into differences in construal between the two languages' adpositions, namely a number of construals that are frequent in Chinese but rare or unattested in the English corpus. The annotated corpus can further support automatic disambiguation of adpositions in Chinese, and the common inventory of supersenses between the two languages can potentially serve cross-linguistic tasks such as machine translation.
* 4 pages