 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeImproving Accent Conversion with Reference Encoder and End-To-End Text-To-Speech
Paper and Code
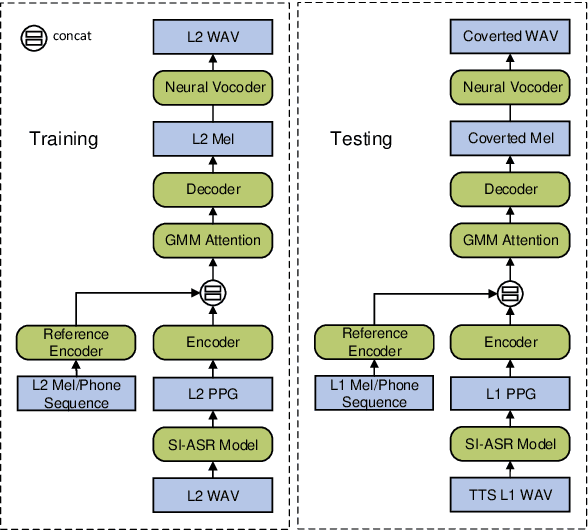
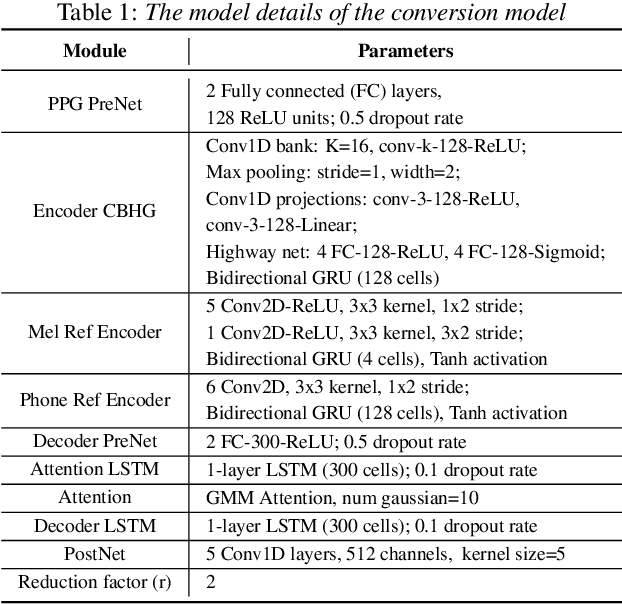
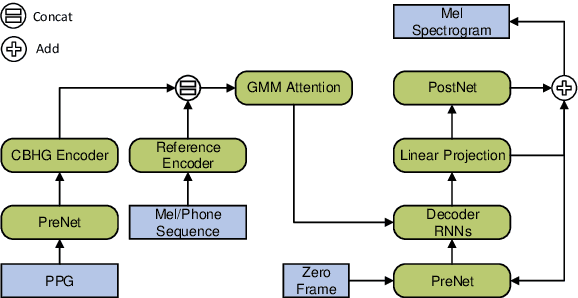
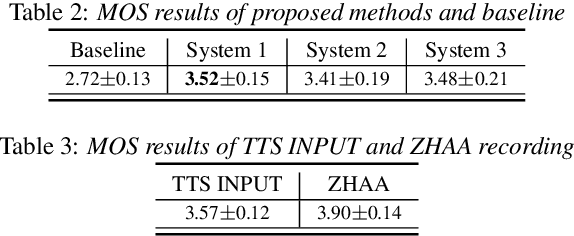
Accent conversion (AC) transforms a non-native speaker's accent into a native accent while maintaining the speaker's voice timbre. In this paper, we propose approaches to improving accent conversion applicability, as well as quality. First of all, we assume no reference speech is available at the conversion stage, and hence we employ an end-to-end text-to-speech system that is trained on native speech to generate native reference speech. To improve the quality and accent of the converted speech, we introduce reference encoders which make us capable of utilizing multi-source information. This is motivated by acoustic features extracted from native reference and linguistic information, which are complementary to conventional phonetic posteriorgrams (PPGs), so they can be concatenated as features to improve a baseline system based only on PPGs. Moreover, we optimize model architecture using GMM-based attention instead of windowed attention to elevate synthesized performance. Experimental results indicate when the proposed techniques are applied the integrated system significantly raises the scores of acoustic quality (30$\%$ relative increase in mean opinion score) and native accent (68$\%$ relative preference) while retaining the voice identity of the non-native speaker.