 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLinear Log-Normal Attention with Unbiased Concentration
Nov 22, 2023Transformer models have achieved remarkable results in a wide range of applications. However, their scalability is hampered by the quadratic time and memory complexity of the self-attention mechanism concerning the sequence length. This limitation poses a substantial obstacle when dealing with long documents or high-resolution images. In this work, we study the self-attention mechanism by analyzing the distribution of the attention matrix and its concentration ability. Furthermore, we propose instruments to measure these quantities and introduce a novel self-attention mechanism, Linear Log-Normal Attention, designed to emulate the distribution and concentration behavior of the original self-attention. Our experimental results on popular natural language benchmarks reveal that our proposed Linear Log-Normal Attention outperforms other linearized attention alternatives, offering a promising avenue for enhancing the scalability of transformer models. Our code is available in supplementary materials.
Rotation Invariant Quantization for Model Compression
Mar 03, 2023



Post-training Neural Network (NN) model compression is an attractive approach for deploying large, memory-consuming models on devices with limited memory resources. In this study, we investigate the rate-distortion tradeoff for NN model compression. First, we suggest a Rotation-Invariant Quantization (RIQ) technique that utilizes a single parameter to quantize the entire NN model, yielding a different rate at each layer, i.e., mixed-precision quantization. Then, we prove that our rotation-invariant approach is optimal in terms of compression. We rigorously evaluate RIQ and demonstrate its capabilities on various models and tasks. For example, RIQ facilitates $\times 19.4$ and $\times 52.9$ compression ratios on pre-trained VGG dense and pruned models, respectively, with $<0.4\%$ accuracy degradation. Code: \url{https://github.com/ehaleva/RIQ}.
Improving Post Training Neural Quantization: Layer-wise Calibration and Integer Programming
Jun 14, 2020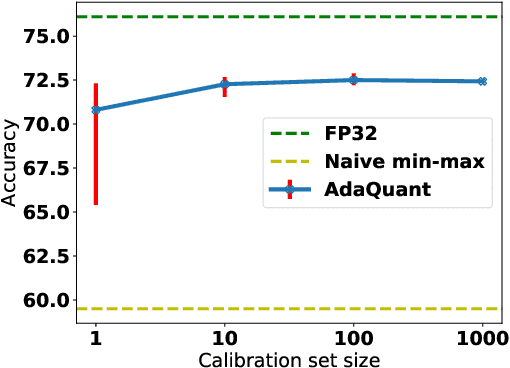

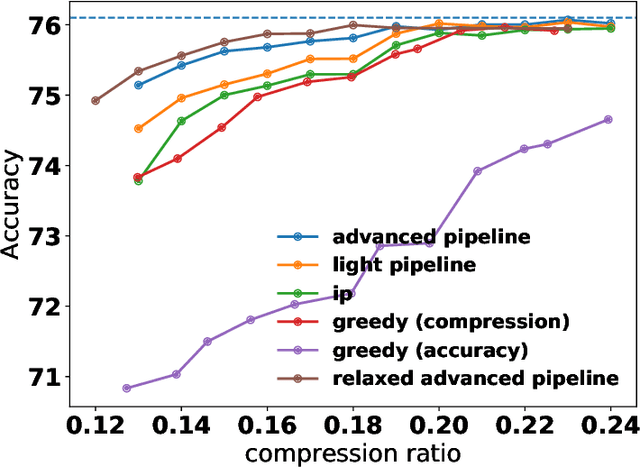
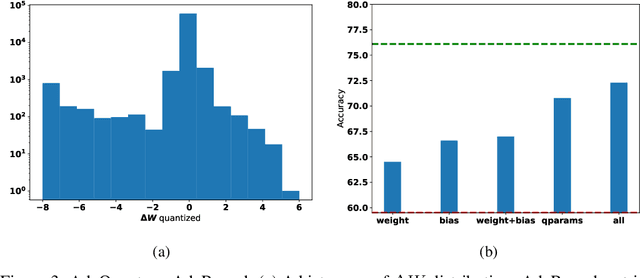
Most of the literature on neural network quantization requires some training of the quantized model (fine-tuning). However, this training is not always possible in real-world scenarios, as it requires the full dataset. Lately, post-training quantization methods have gained considerable attention, as they are simple to use and require only a small, unlabeled calibration set. Yet, they usually incur significant accuracy degradation when quantized below 8-bits. This paper seeks to address this problem by introducing two pipelines, advanced and light, where the former involves: (i) minimizing the quantization errors of each layer by optimizing its parameters over the calibration set; (ii) using integer programming to optimally allocate the desired bit-width for each layer while constraining accuracy degradation or model compression; and (iii) tuning the mixed-precision model statistics to correct biases introduced during quantization. While the light pipeline which invokes only (ii) and (iii) obtains surprisingly accurate results; the advanced pipeline yields state-of-the-art accuracy-compression ratios for both vision and text models. For instance, on ResNet50, we obtain less than 1% accuracy degradation while compressing the model to 13% of its original size. We open-sourced our code.
Loss Aware Post-training Quantization
Nov 17, 2019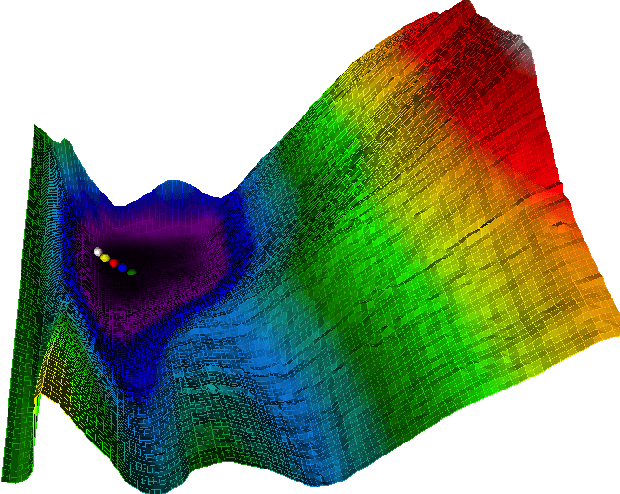

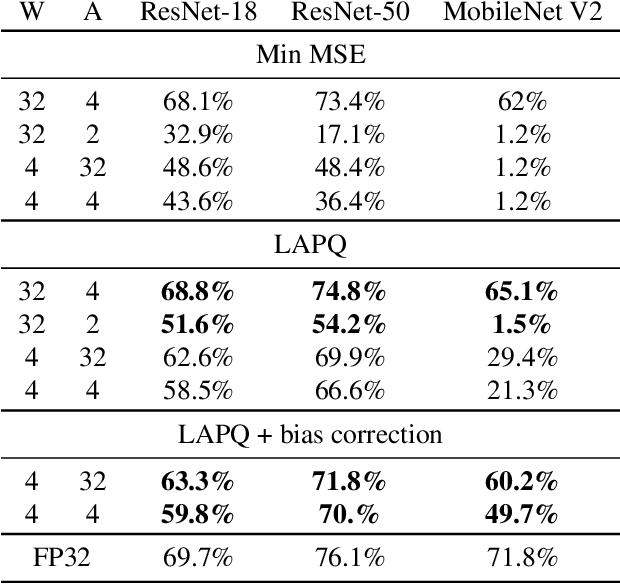
Neural network quantization enables the deployment of large models on resource-constrained devices. Current post-training quantization methods fall short in terms of accuracy for INT4 (or lower) but provide reasonable accuracy for INT8 (or above). In this work, we study the effect of quantization on the structure of the loss landscape. We show that the structure is flat and separable for mild quantization, enabling straightforward post-training quantization methods to achieve good results. On the other hand, we show that with more aggressive quantization, the loss landscape becomes highly non-separable with sharp minima points, making the selection of quantization parameters more challenging. Armed with this understanding, we design a method that quantizes the layer parameters jointly, enabling significant accuracy improvement over current post-training quantization methods. Reference implementation accompanies the paper at https://github.com/ynahshan/nn-quantization-pytorch/tree/master/lapq
ACIQ: Analytical Clipping for Integer Quantization of neural networks
Oct 02, 2018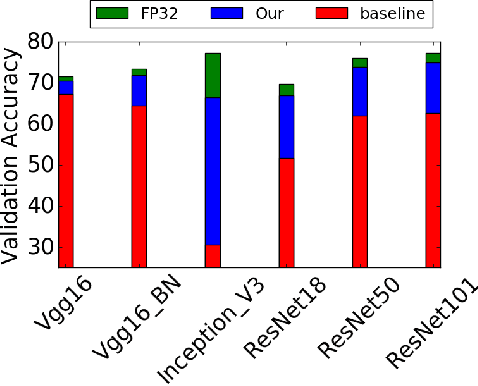

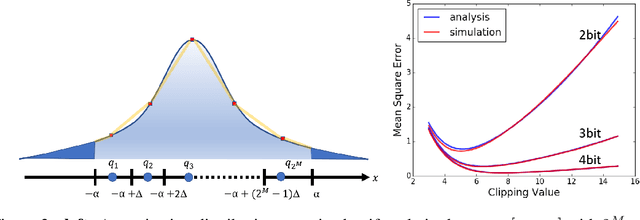
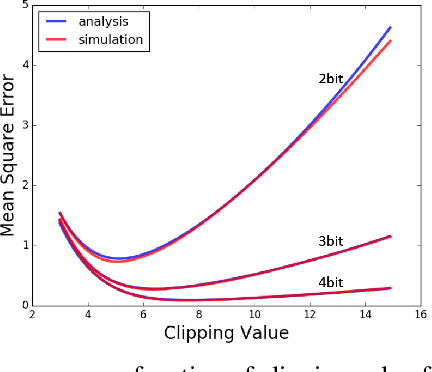
Unlike traditional approaches that focus on the quantization at the network level, in this work we propose to minimize the quantization effect at the tensor level. We analyze the trade-off between quantization noise and clipping distortion in low precision networks. We identify the statistics of various tensors, and derive exact expressions for the mean-square-error degradation due to clipping. By optimizing these expressions, we show marked improvements over standard quantization schemes that normally avoid clipping. For example, just by choosing the accurate clipping values, more than 40\% accuracy improvement is obtained for the quantization of VGG16-BN to 4-bits of precision. Our results have many applications for the quantization of neural networks at both training and inference time. One immediate application is for a rapid deployment of neural networks to low-precision accelerators without time-consuming fine tuning or the availability of the full datasets.